







解析:int ShowOnePage(unsigned char *pucTextFileMemCurPos)
其中:
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
这里得到一个字 但是得到的编码并不是返回值而是存在*pdwCode里 返回的是本次一共处理了文件里的多少个字节数据
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap); //这里得到位图数据,就是点阵数据具体参看程序解析说明:
ptFontOpr是谁? 以编码是UTF8来说:
从编码的初始化函数可知:
int Utf8EncodingInit(void)
{
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("freetype"));
AddFontOprForEncoding(&g_tUtf8EncodingOpr, GetFontOpr("ascii"));
return RegisterEncodingOpr(&g_tUtf8EncodingOpr);
}
这里注册了字体,ptFontOpr就是其中的一个,那到底是谁?
再看AddFontOprForEncoding函数:
int AddFontOprForEncoding(PT_EncodingOpr ptEncodingOpr, PT_FontOpr ptFontOpr)
{
PT_FontOpr ptFontOprCpy;
if (!ptEncodingOpr || !ptFontOpr)
{
return -1;
}
else
{
ptFontOprCpy = malloc(sizeof(T_FontOpr));
if (!ptFontOprCpy)
{
return -1;
}
else
{
memcpy(ptFontOprCpy, ptFontOpr, sizeof(T_FontOpr));
ptFontOprCpy->ptNext = ptEncodingOpr->ptFontOprSupportedHead;
ptEncodingOpr->ptFontOprSupportedHead = ptFontOprCpy;
return 0;
}
}
}
由上可知:
越是后调用该函数的字体,他在链表中的位置越靠前,即最后添加的就是链表头指向的字体
往上参看ptFontOpr的来源看到这句话:ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
而其中的ptFontOprSupportedHead就是上面设置的链表头,从上面的这个函数看 int Utf8EncodingInit(void)
可以知道这里的ptFontOpr就是名为"ascii"的字体。
但是这样更加得到一个疑惑,如果是从"ascii"字体库提出字体的,那非"ascii"码该怎么办,现在就来看看"ascii"字体的GetFontBitmap函数,也就是下面的代码:
static int ASCIIGetFontBitmap(unsigned int dwCode, PT_FontBitMap ptFontBitMap)
{
int iPenX = ptFontBitMap->iCurOriginX;
int iPenY = ptFontBitMap->iCurOriginY;
if (dwCode > (unsigned int)0x80)
{
//DBG_PRINTF("don't support this code : 0x%x\n", dwCode);
return -1;
}
ptFontBitMap->iXLeft = iPenX;
ptFontBitMap->iYTop = iPenY - 16;
ptFontBitMap->iXMax = iPenX + 8;
ptFontBitMap->iYMax = iPenY;
ptFontBitMap->iBpp = 1;
ptFontBitMap->iPitch = 1;
ptFontBitMap->pucBuffer = (unsigned char *)&fontdata_8x16[dwCode * 16];;
ptFontBitMap->iNextOriginX = iPenX + 8;
ptFontBitMap->iNextOriginY = iPenY;
return 0;
}
现在就出现了一个疑惑,从这里看根本就没有对非ascii的支持。
有一个函数与AddFontOprForEncoding相对,也就是DelFontOprFrmEncoding函数,这个函数在这里应用:
int SetTextDetail(char *pcHZKFile, char *pcFileFreetype, unsigned int dwFontSize)
{
............................
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
else if (strcmp(ptFontOpr->name, "gbk") == 0)
{
iError = ptFontOpr->FontInit(pcHZKFile, dwFontSize);
}
else
{
iError = ptFontOpr->FontInit(pcFileFreetype, dwFontSize);
}
if (iError == 0)
{
/* 比如对于ascii编码的文件, 可能用ascii字体也可能用gbk字体,
* 所以只要有一个FontInit成功, SetTextDetail最终就返回成功
*/
iRet = 0;
}
else
{
DelFontOprFrmEncoding(g_ptEncodingOprForFile, ptFontOpr);
}
}
说明如果字体初始换不成功,这里就会删除掉字体,那是不是如果传入的不是ascii码,在这里会被删除了,来看看ascii字体的初始换函数:
static int ASCIIFontInit(char *pcFontFile, unsigned int dwFontSize)
{
if (dwFontSize != 16)
{
//DBG_PRINTF("ASCII can't support %d font size\n", dwFontSize);
return -1;
}
return 0;
}
由这里可以知道其实如果传入的字体大小不是16,ascii字体将从utf8码了删除,所以utf8只有FileFreetype字体的支持
但是还有一个疑惑,就是当传入的字体大小为16的时候,如果传入的内容又有非ascii码(如“abcd工具能用eclipse进行源码级别的调试有些前提”)又该怎么办:
继续看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函数,在最后看到有这句话:
}
ptFontOpr = ptFontOpr->ptNext;
}
}
也就说如果字体的GetFontBitmap函数不支持的话,将换字体
测试我们的想法:
两个不同的命令:
./show_file -s 16 -f MSYH.TTF utf8_test.txt
./show_file -s 20 -f MSYH.TTF utf8_test.txt
由上面的分析可知:
第一个命令将会使用ascii字体,第二个命令将使用将使用FileFreetype字体
为了参看结果我们在函数int ShowOnePage(unsigned char *pucTextFileMemCurPos)的pucBufStart = pucTextFileMemCurPos;行后面加上下列打印语句:
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
第二条命令的结果:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 20 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: freetype
Enter 'n' to show next page, 'u' to show previous page, 'q' to exit:
液晶显示的图像:
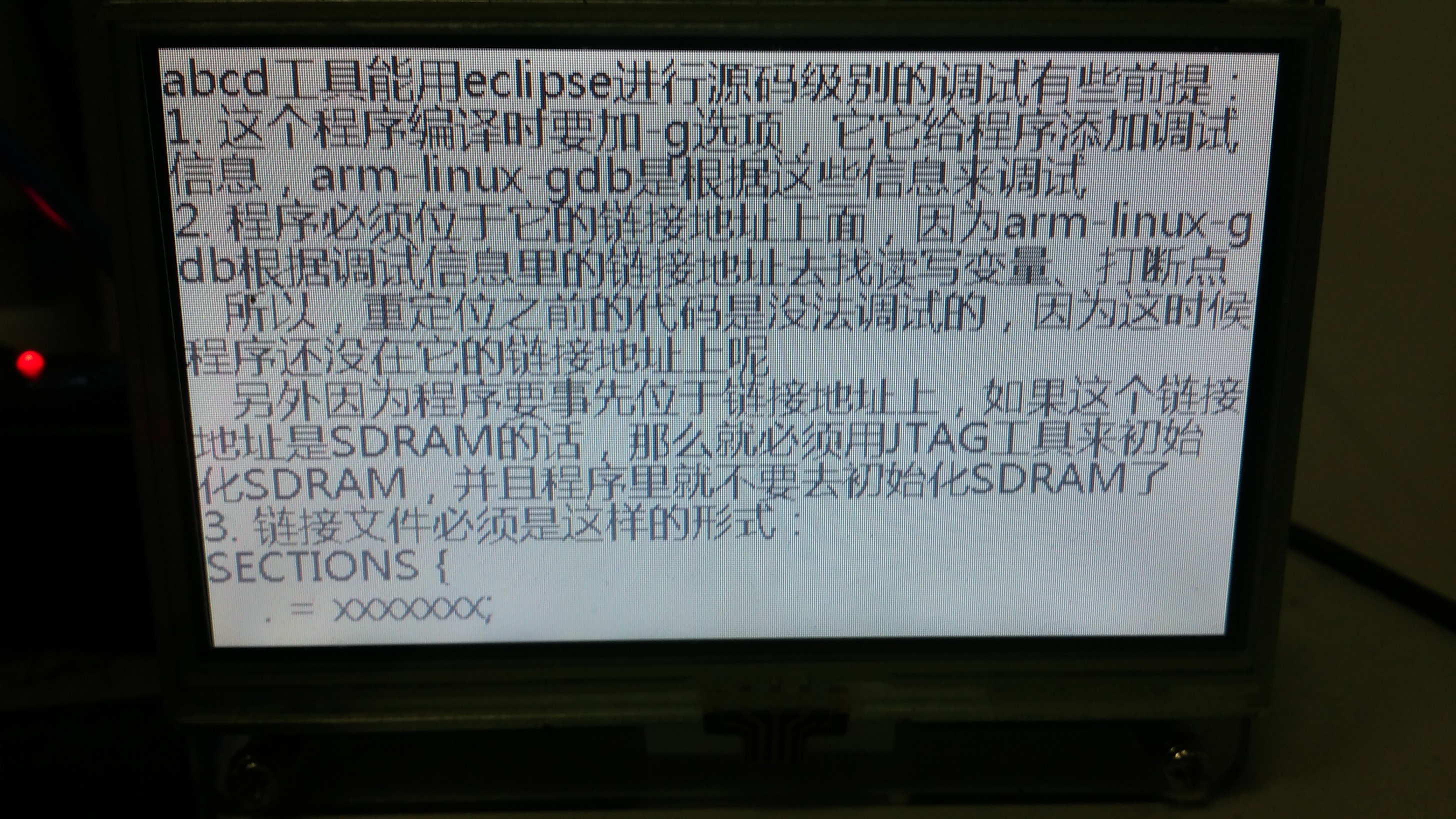
说明我们的假设是对的,图像的字体也只有20号的字体,也就没有使用到ascii字体,这里并没有使用ascii字体,也就是说:
if (strcmp(ptFontOpr->name, "ascii") == 0)
{
iError = ptFontOpr->FontInit(NULL, dwFontSize);
}
是失败的,所以utf-8的字体支持库里已经没有了ascii字体
我们再看看第一个指令,
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: ascii
Enter 'n' to show next page, 'u' to show previous page, 'q' to exit:
液晶显示的图像:
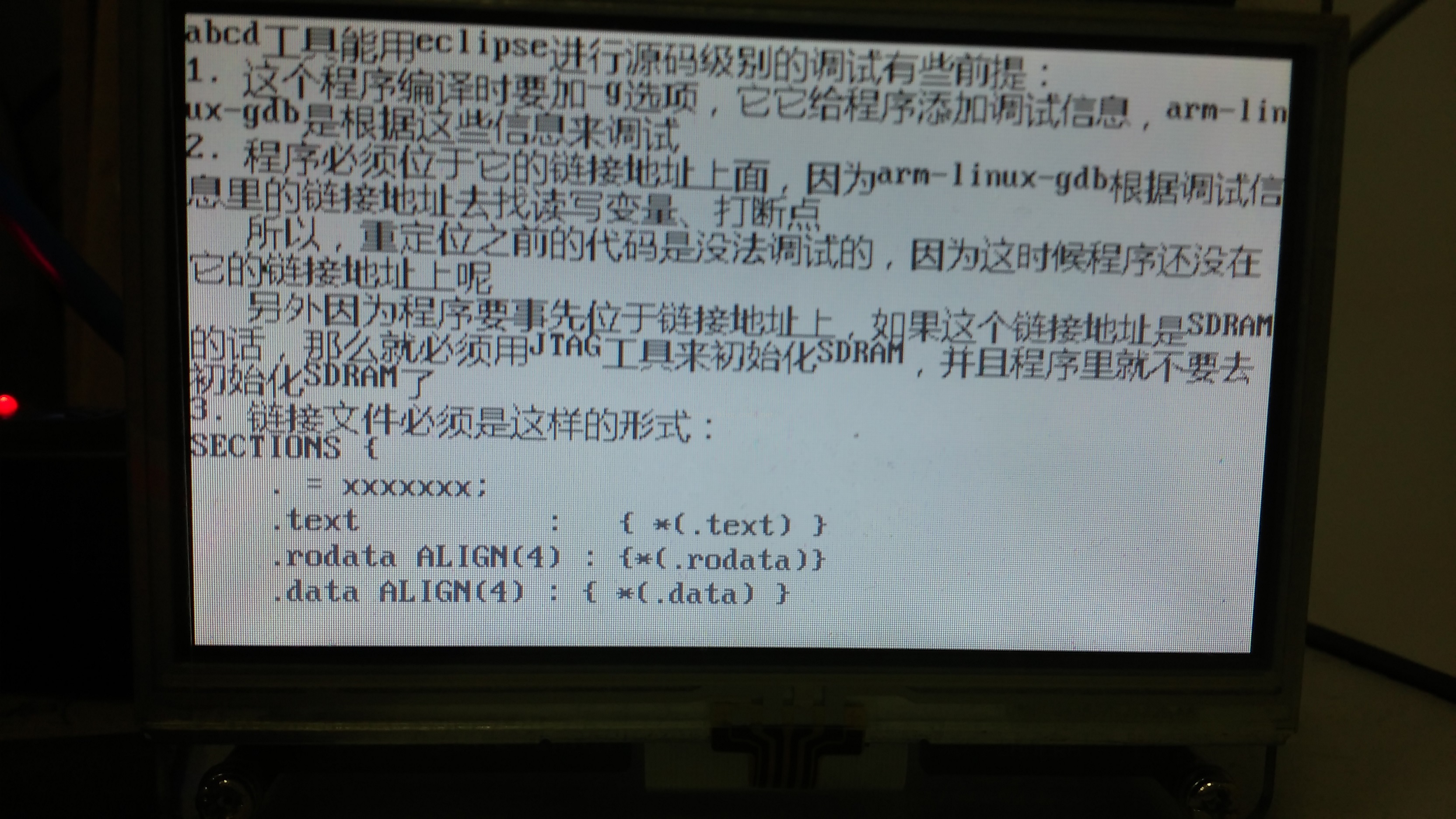
图像的字体不单单有20号的字体,还有16号字体,也就使用到ascii字体,说明第一个使用的字体确实是ascii,也说明我们的想法是对的,现在再来看看当文件里还有非ascii码的文字时是不是存在着字体库的变化:
在函数int ShowOnePage(unsigned char *pucTextFileMemCurPos)的改变字体的语句:ptFontOpr = ptFontOpr->ptNext;后加上打印:
printf("now ptFontOpr: %s\n",ptFontOpr->name);
改变后的周边语句应该是这样的:
/* 继续取出下一个编码来显示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
这样再看看命令./show_file -s 16 -f MSYH.TTF utf8_te的执行:
/digital_photo_frame/04.show_file_mysel # ./show_file -s 16 -f MSYH.TTF utf8_te
st.txt
g_ptEncodingOprForFile: utf-8
first ptFontOpr: ascii
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
now ptFontOpr: freetype
-----------------------
说明切换了很多次字库,至于为什么,我们再来看看int ShowOnePage(unsigned char *pucTextFileMemCurPos)函数的执行过程:
int ShowOnePage(unsigned char *pucTextFileMemCurPos)
{
------------------------
printf("g_ptEncodingOprForFile: %s\n",g_ptEncodingOprForFile->name);
printf("first ptFontOpr: %s\n",g_ptEncodingOprForFile->ptFontOprSupportedHead->name);
while (1)
{
//这里得到一个字 但是得到的编码并不是返回值而是存在*pdwCode里 返回的是本次一共处理了文件里的多少个字节数据
iLen = g_ptEncodingOprForFile->GetCodeFrmBuf(pucBufStart, g_pucTextFileMemEnd, &dwCode);
----------------------------------------
ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;
while (ptFontOpr)
{
//这里得到位图数据,就是点阵数据具体参看程序解析说明:
//当获取结果不对时出错 也就是字体发现自己不能支持改编码的时候
iError = ptFontOpr->GetFontBitmap(dwCode, &tFontBitMap);
if (0 == iError)
{
------------------------------
/* 显示一个字符 */
if (ShowOneFont(&tFontBitMap))
{
return -1;
}
tFontBitMap.iCurOriginX = tFontBitMap.iNextOriginX;
tFontBitMap.iCurOriginY = tFontBitMap.iNextOriginY;
g_pucLcdNextPosAtFile = pucBufStart;
/* 继续取出下一个编码来显示 */
break;
}
ptFontOpr = ptFontOpr->ptNext;
printf("now ptFontOpr: %s\n",ptFontOpr->name);
}
}
return 0;
}
由此可以发现现实一页这个功能是在while (1)里的,注意其中的现实下一个字符的推出语句是break;,其将推出while (ptFontOpr),所以没显示完一个字符后都会推出到while (1)下继续执行,而while (1)下又会重新赋值字体ptFontOpr = g_ptEncodingOprForFile->ptFontOprSupportedHead;所以也就是说当发现某个编码是非ascii码需要改变,当现实完一个字符后将重新把字体赋值成预定义的ascii字体,这也就是为什么出现那么多的now ptFontOpr: freetype打印语句的原因。
从液晶上也是可以看到凡是英文都是用ascii字体来显示的,也就是16号字体
至此int ShowOnePage(unsigned char *pucTextFileMemCurPos)函数的以后分析完毕
本文使用的源代码:
http://download.csdn.net/detail/chengdong1314/9285361
,














 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









