









第6章 MapReduce入门
6.3 加速WordCount
6.3.1 问题分析
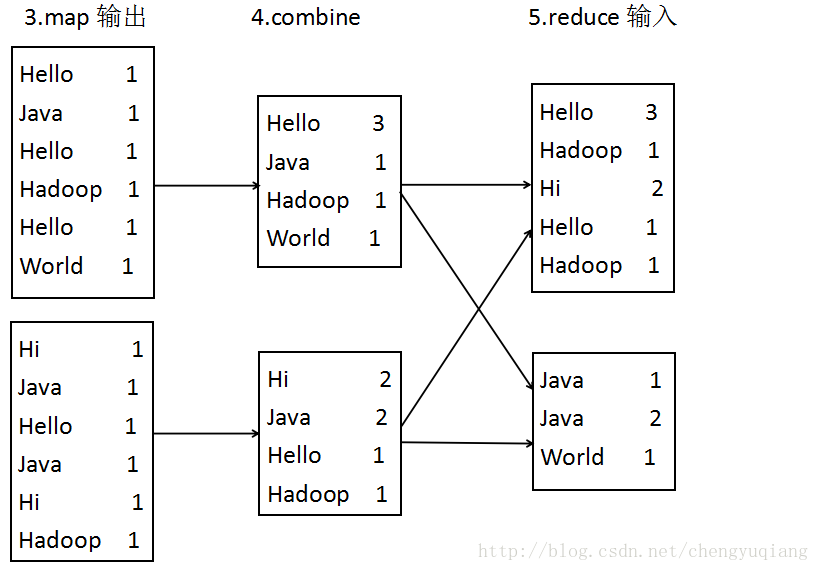
MapReduce的性能很大程度受限于网络宽带,当map输出中间结果很大时,然后通过网络将中间结果传递给reduce方法,这时MapReduce的性能较差。
通过对WordCount程序分析,大家可能已经发现其中存在一个很“笨”的问题:map方法输出值是
<word,1>形式,如果map方法处理的文本很大,则输出的<word,1>很多很多。如果能减少map方法输入内容,也就是减少中间结果值,那么下一步传递给reduce的数据量,也即是reduce的输入数据量将会减小。combine过程正是对map方法输出结果在发送到reduce前进行聚合减少传输数据量。
如图所示,combine过程发生在map方法和reduce方法之间,它将中间结果进行了一次合并。
6.3.2 WordCount v2.0
想在自己的MapReduce程序中其中combine过程,其实很简单,只需要在main方法中增加如下代码:
job.setCombinerClass(IntSumReducer.class);WordCount v2.0 完整代码如下:
package cn.hadron.mr;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount2 {
//4个泛型参数:前两个表示map的输入键值对的key和value的类型,后两个表示输出键值对的key和value的类型
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
//StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,
//所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
//执行MapReduce任务
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordCount");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//开启combine过程
job.setCombinerClass(IntSumReducer.class);
//命令行输入的第一个参数是输入路径,第二个参数是输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}6.3.3 Combiner注意事项
- Combiner能够提高性能,但是不是所有场景都适合。具体问题,需要最具体分析。
- Combiner仅适合求解最大值、最小值以及求和等场景。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









