




 本文介绍在Caffe环境下构建自定义数据集的过程,包括数据准备、标签生成、图像库转换为leveldb格式等步骤,并使用64*64尺寸的图像进行训练。
本文介绍在Caffe环境下构建自定义数据集的过程,包括数据准备、标签生成、图像库转换为leveldb格式等步骤,并使用64*64尺寸的图像进行训练。
前两篇博客中以cifar10为例,分别介绍了使用cifar10生成caffemodel的步骤,和使用cifar10的caffemodel实现图像分类的步骤,本篇博客将介绍在caffe for windows下如何构建自己的数据集,如何训练自己的数据集以及如何利用自己训练出来的caffemodel模型实现图像分类。
本文只是傻瓜式的介绍步骤,要想深入理解caffe,请阅读源码。本文对四种图像进行分类。
数据准备
这部分是最耗时耗力的了,自己自行准备,注意准备的图片的大小最好是一样的,免得麻烦。我使用64*64的尺寸大小。给出train文件夹图像库的列表示意。假设我们已经准备好了数据,每一个分类中有100张train图片,有20张test图片。将这里面的400张train图片放到train文件夹,80张test图片放到test文件夹。
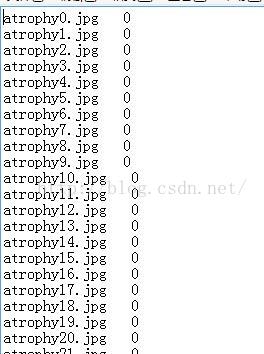
然后我们需要制作标签(label),将图片路径与图片分类作为键值对,因为我们需要对四种不同的图像进行分类,所以我们可以将第一种图像的标签设为0,第二种设为1,第三种设为2,第四种设为3.
这些“键值对”被保存到.txt中。对应的train中的label为:
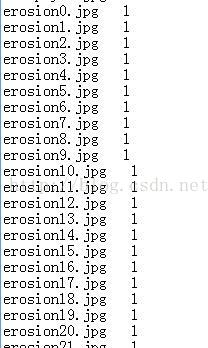
如果图片数据库非常大,直接写一个小程序,自动生成标签label的.txt。注意label包括两个部分,一个是train,一个是test。这里不再赘述test的label的生成。
那么我们为什么要花时间去做label呢,当然是通过程序读取label的.txt,每一行为一个键值对,一个键值对对应一幅图像的路径与标签。注意,是图像的路径而不是图像的名称。因为我的数据库与程序在同级目录,所以这里的图片名称即为图片相对路径。
convert_imageset.exe生成
这一部分换句话说就是将图片库转化成深度学习网络允许的数据格式leveldb。具体步骤:
在Solution新建一个cuda project,导入tools文件夹中的convert_imageset.cpp文件,配置环境。编译,在bin文件夹下面生成了convert_imageset.exe。
新建一个.bat,添加内容并保存。下面是train的的数据集转leveldb,转完之后的数据保存到了train_leveldb文件夹下面。同理可得test.......
H:\happynearcaffe\caffe-windows-master\caffe-windows-master\bin\convert_imageset.exe --resize_height=32 --resize_width=32 --shuffle --backend="leveldb" H:\Gastric_DB\train\ H:\Gastric_DB\labels\train.txt H:\Gastric_DB\train_leveldb
pause计算数据的均值文件
训练数据集
使用caffemodel实现图像分类
以上的三个步骤和我之前介绍的cifar10步骤差不多,不在介绍。需要注意的是,因为我训练的数据集一张图像大小为64*64,cifar10一张图片大小为32*32很接近,所以我使用的网络结构框架prototxt为cifar10的网络结构,当然把相应的位置改了一下,比如输出从10变成了4,图像大小由32*32变成64*64,均值路径,source路径等等。

















 2014
2014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









