







我在做【文件搜】网站用到的:
高速版(JAVA+Lucene) http://wjsou.com:8080/
低速版(PHP+Mysql) http://wjsou.com
高速版:耗时 0.015s ,找到约 1000 个结果。
千万份数据全部存到内存里面。
模糊匹配搜索,输错了一两个字也没事。
lucene全文检索引擎,无需数据库。
有人要网盘搜索源码吗?
含所有源码及近7000多万条文件链接(无重复链接)
24小时不间隔自动爬虫采集。响应速度0.015ms内。
语言:Java+Lucene高速版 ,低速版(PHP+MySQL)
最低环境:1G内存 (建议4G)
高速版(Java+Lucene) http://wjsou.com:8080/
低速版(PHP+MySQL) http://wjsou.com
高速版:耗时 0.015s ,找到约 1000 个结果。(4G环境测试结果)
千万份数据全部存到内存里面。模糊匹配搜索,输错了一两个字也没事。lucene全文检索引擎,无需数据库。
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
public class HelloLucene {
public static void main(String[] args) throws IOException, ParseException {
// 0. Specify the analyzer for tokenizing text.
// The same analyzer should be used for indexing and searching
StandardAnalyzer analyzer = new StandardAnalyzer();
// 1. create the index
Directory index = new RAMDirectory();
//Directory index=FSDirectory.open(Paths.get("c:/demo"));//open("c:/demo");
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter w = new IndexWriter(index, config);
addDoc(w, "Lucene in Action小说", "193398817");
addDoc(w, "Lucene for Dummies说", "55320055Z");
addDoc(w, "Managing Gigabytes", "55063554A");
addDoc(w, "The Art of Computer Science", "9900333X");
w.close();
// 2. query
String querystr = args.length > 0 ? args[0] : "小说 ddd Computer";
// the "title" arg specifies the default field to use
// when no field is explicitly specified in the query.
Query q = new QueryParser("title", analyzer).parse(querystr);
// 3. search
int hitsPerPage = 8;
IndexReader reader = DirectoryReader.open(index);
IndexSearcher searcher = new IndexSearcher(reader);
TopScoreDocCollector collector = TopScoreDocCollector.create(hitsPerPage);
searcher.search(q, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs;
// 4. display results
System.out.println("Found " + hits.length + " hits.");
for(int i=0;i<hits.length;++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("isbn") + "\t" + d.get("title"));
}
// reader can only be closed when there
// is no need to access the documents any more.
reader.close();
}
private static void addDoc(IndexWriter w, String title, String isbn) throws IOException {
Document doc = new Document();
doc.add(new TextField("title", title, Field.Store.YES));
// use a string field for isbn because we don't want it tokenized
doc.add(new StringField("isbn", isbn, Field.Store.YES));
w.addDocument(doc);
}
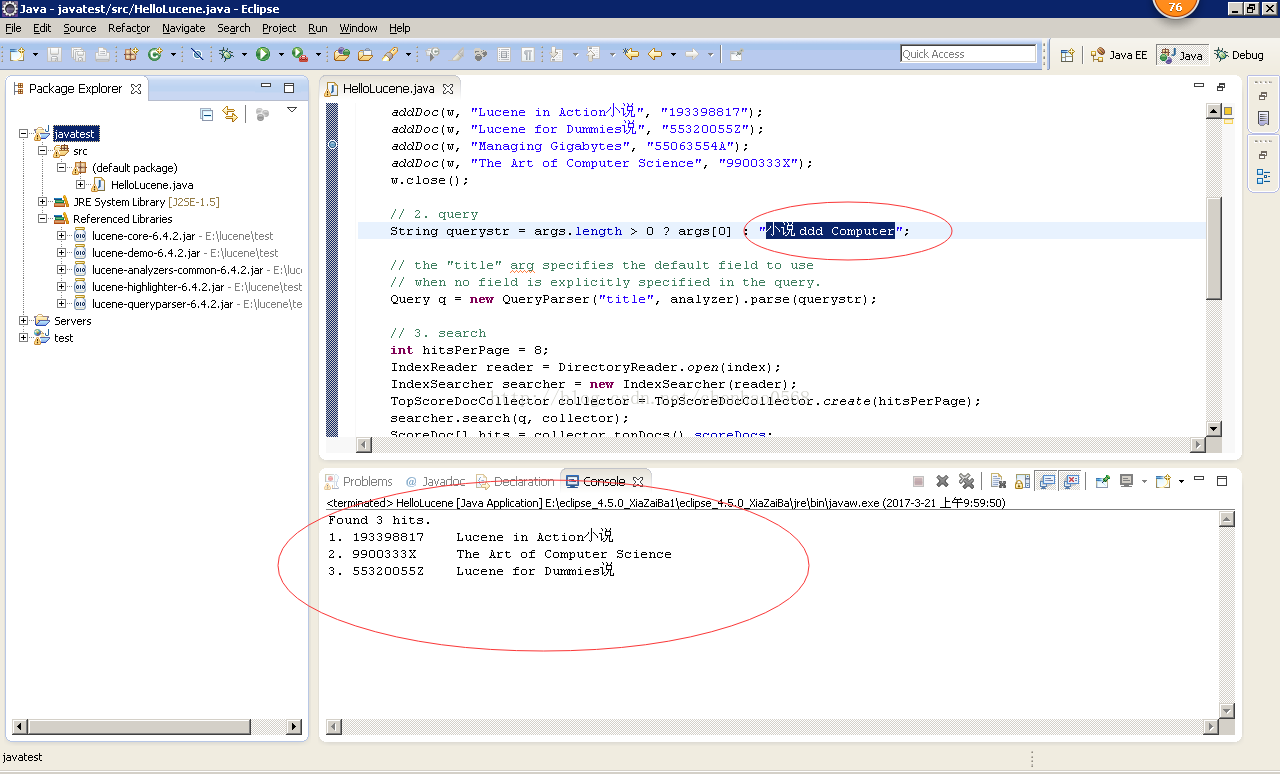
}测试:小说 ddd Computer
结果:
Found 3 hits.
1. 193398817 Lucene in Action小说
2. 9900333X The Art of Computer Science
3. 55320055Z Lucene for Dummies说
达到了我要的效果:
比如test abc
全部匹配test abc defg 优先级最高
匹配test 优先级次高
少一个字匹配tes
再少一字匹配te
等等















 9294
9294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











