







在之前的文章《IBM SPSS Modeler算法系列-----决策树CHAID算法》,我们介绍是CHAID算法,今天我们介绍另外一种用得非常广泛的决策树算法C5.0,该算法是专属于RuleQuest 研究有限公司(http://www.rulequest.com/)。
对于决策树算法来说,核心技术就是如何确定最佳分组变量和分割点,上次我们介绍的CHAID是以卡方检验为标准,而今天我们要介绍的C5.0则是以信息增益率作为标准,所以首先我们来了解下信息增益(Gains),要了解信息增益(Gains),先要明白信息熵的概念。
信息熵是信息论中的基本概念,信息论是1948年由C.E.Shannon提出并发展起来的,主要用于解决信息传递中的问题,也称统计通信理论。这些技术的概念很多书籍或者百度一下都有具体的介绍,我们这里不再赘述,我们通过一个例子来理解信息量和信息熵。
在拳击比赛中,两位对手谁能获得胜利,在对两位选择的实力没有任何了解的情况下,双方取得胜利的概率都是1/2,所以谁获得胜利这条信息的信息量,我们通过公式计算 :
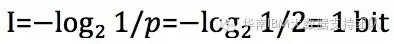
其中p是每种情况出现的概率,这里计算出来的1bit就是谁获得胜利这条信息的信息量。如果信息是最后进入四强的选手谁获得最终胜利,它的信息量是 :
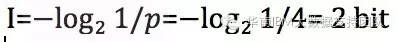
对比这个例子可以看到,不确定性越高,信息量就越大。
信息熵是信息量的数学期望,数学期望听起来有点陌生,但均值我相信大家都明白,那么在概率论和统计学中,数学期望指的就是均值,它是试验中每次可能出现的结果的概率乘以其结果的总和,它反映随机变量平均取值的大小。信息熵是平均信息量,也可以理解为不确定性。因此,信息熵的计算公式是:
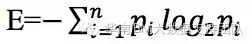
仍以前面拳击比赛为例子,如果两对对手获胜的概率都为50%,那么信息熵:
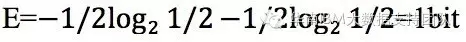
如果两位对手A和B,根据以往的比赛历史经验判断,A胜利的概率是80%,B胜利的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









