







1.pt-table-checksum 用于检测主从的数据是否一致。
常用参数:
1.--nocheck-replication-filters :不检查复制过滤器,建议启用。后面可以用--databases来指定需要检查的数据库。
2.--no-check-binlog-format : 不检查复制的binlog模式,要是binlog模式是ROW,则会报错。
3.--replicate-check-only :只显示不同步的信息。
4.--replicate= :把checksum的信息写入到指定表中,建议直接写到被检查的数据库当中。
5.--databases= :指定需要被检查的数据库,多个则用逗号隔开。
6.--tables= :指定需要被检查的表,多个用逗号隔开,如果是全库检测的时候可以去掉此参数
7.h=127.0.0.1 :Master的地址
8.u=root :用户名
9.p=123456:密码
10.P=3306 :端口
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=XX.checksums --create-replicate-table --databases=XX --tables=XXX -h 192.168.255.138 -P 3306 -u root -p repl --recursion-method="processlist"
运行结果如下下图:
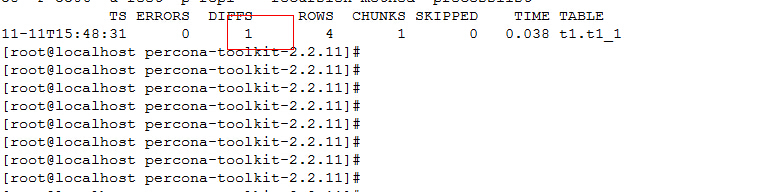
当DIFFS不为0时表示表t1_1中的主从数据不同步。
执行结果显示参数意义: TS :完成检查的时间。
ERRORS :检查时候发生错误和警告的数量。
DIFFS :0表示一致,大于0表示不致。当指定--no-replicate-check时,会一直为0,当指定--replicate-check-only会显示不同的信息。
ROWS :表的行数。
CHUNKS :被划分到表中的块的数目。
SKIPPED :由于错误或警告或过大,则跳过块的数目。
TIME :执行的时间。
TABLE :被检查的表名。
2.pt-table-sync 高效的同步MySQL表之间的数据,他可以做单向和双向同步的表数据。他可以同步单个表,也可以同步整个库。它不同步表结构、索引、或任何其他模式对象。所以在修复一致性之前需要保证他们表存在。
常用参数:
1.--replicate= :指定通过pt-table-checksum得到的表,这2个工具差不多都会一直用。
2.--databases= : 指定执行同步的数据库,多个用逗号隔开。
3.--tables= :指定执行同步的表,多个用逗号隔开。如果是全库执行不需要此参数
4.--charset= 指定字符集
5.--print :打印,但不执行命令。
6.--execute :执行命令。
7.h=127.0.0.1 :Master的地址
8.u=root :用户名
9.p=123456:密码
10.P=3306 端口号
运行命令:
1.pt-table-sync --replicate=wubx.checksums --databases=wubx --charset=utf8 h=192.168.11.81,u=root,p=repl --print(只是查看不同的数据)
运行结果如下图:

2.pt-table-sync --replicate=t1.checksums --databases=t1 --charset=utf8 h=192.168.255.138,u=root,p=repl –-execute(执行之后就会数据同步)
3.pt-query-digest 是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
常用参数:
1.--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。2.--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。
3.--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
4.--limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
5.--host mysql服务器地址
6.--user mysql用户名
7.--password mysql用户密码
8.--history 将分析结果保存到表中,分析结果比较详细,下次再使用-history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
9.--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。
10.--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
11.--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
12.--until 截止时间,配合—since可以分析一段时间内的慢查询。
运行命令:
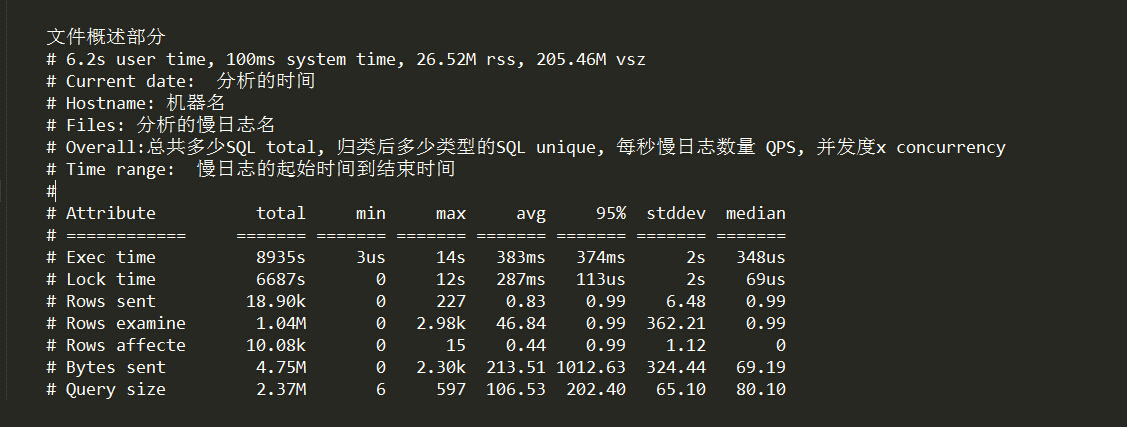
1.pt-query-digest /data/mysql/mysql_3306/logbin.000062 > /data/mysql/mysql_3306/logbin.000062.report.log
2.cat /data/mysql/mysql_3306/logbin.000062
3.如下图(这张截图里没有慢查询日志)














 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









