







背景
概率图模型通常很复杂,难以精确求解。随机模拟等近似算法是处理复杂概率图模型的一种有效手段。许多近似算法的一个关键步骤是生成符合特定分布的样本。对于一些标准的概率分布(如均匀分布、正太分布、指数分布等),通常容易进行采样(例如Matlab 的 Statistics Toolbox 支持许多标准的概率分布)。但是对于复杂的概率分布,很难直接进行采样,因此,我们需要借助其他的手段。
在贝叶斯方法中,我们常需要根据观察到的数据集合
D
,估计模型参数
我们下面的讨论将考虑从概率分布
p(z)
中采样,
p(z)
可能是未归一化的,即有如下形式:
下面将介绍两种针对复杂概率分布的采样方法:接受-拒绝采样、重要性采样。
接受-拒绝采样(accept-rejct sampling)
接受-拒绝采样基于这样一个前提: 对一个随机变量取样, 等价于从这个变量所服从的密度函数下方的区域均匀取样。当然, 取样的结果是变量值,如果是一元变量, 取样后得到的是一元变量的值。
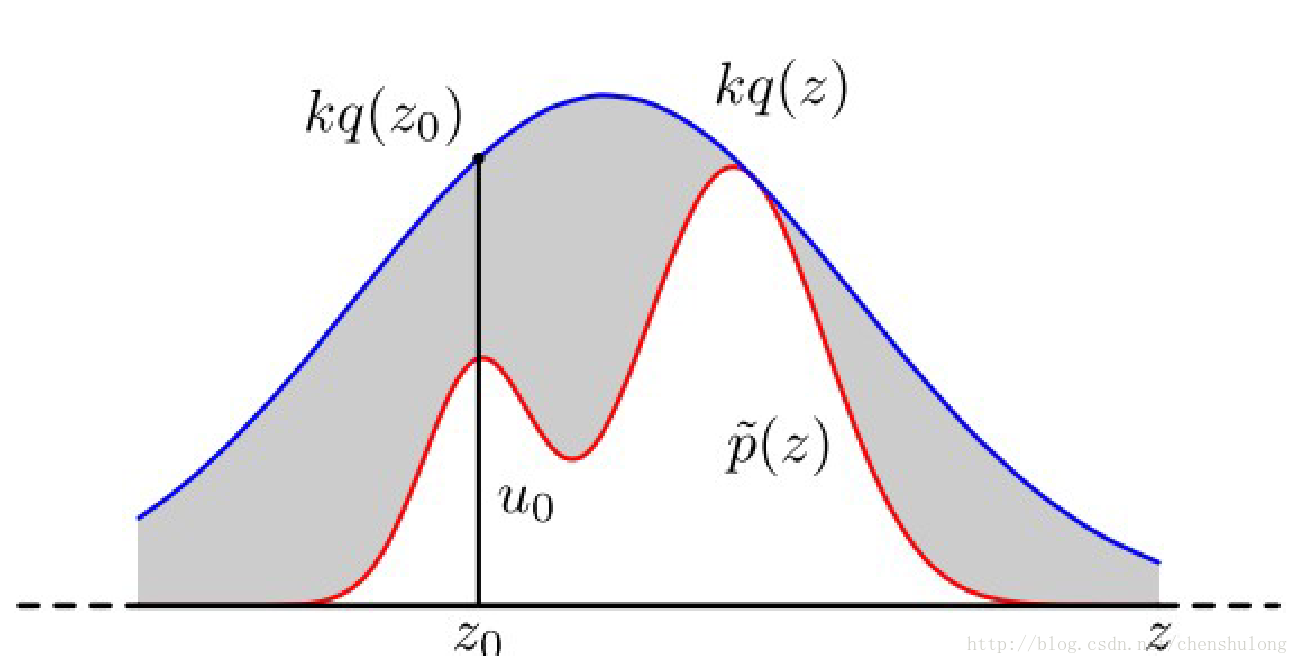
上图显示了采样的过程。我们需要生成符合概率分布 p(z) 的样本。 q(z) 表示选择的建议分布(proposal distribution)。建议分布应选择简单的分布(如正态分布),目的是容易直接进行采样。整个计算过程可以概括如下:
- 选择一个易于采样的建议分布 q(z)
- 寻找一个常数
k
,使
kq(z)≥p~(z) 对于 任意的 z 均成立 - 从建议分布
q(z) 中进行一次采样,得到样本 z0 - 在区间 [0,kq(z0)] 上进行均匀采样,得到 u0
- 如果 u0>p~(z0) (落在灰色区域) 则拒绝采样 z0 ,否则,接受采样
- 重复步骤 3~5,直至生成了足够多的样本。
这种采样方法的效率与样本的接受率(步骤5)密切相关。而样本的接受率是受建议分布 q(z) 影响的。因此,选择合适的建议分布式非常关键的。如果选择的建议分布 q(z) 与 目标分布 p(z) 差异太大,则会导致大量的样本被拒绝,从而降低算法的效率。另外 k 值得选择,也与样本接受率相关。
重要性采样(importance sampling)
Importance Sampling 也是借助了容易采样的建议分布
其中 p(zl)q(zl) 可以看作 important weight,修正了由于从错误的建议分布中采样进入的偏差。
常见的情形是概率分布
p(z)
是未归一化的:
p(z)=p~(z)/Zp
,其中
Zp
未知。类似的,我们采用建议分布
q(z)=q~(z)Zq
,它具有相同的性质。于是有:
其中 r~l=p~(z)q~(z) 。我们可以使用同样的样本集合来计算比值 ZpZq ,结果为:
与接受-拒绝采样的情形相同,重要性采样方法的效果严重依赖于建议分布 q(z) 与 目标分布 p(z) 的匹配程度。重要性采样⽅法的⼀个主要的缺点是它具有产⽣任意错误的结果的可能性,并且这种错误⽆法检测。这也强调了建议分布 q(z) 的⼀个关键的要求,即它不应该 在 p(z) 可能较⼤的区域中取得较⼩的值或者为零的值。
总结
接受-拒绝采样和重要性采样的关键在于建议分布的选取,选择一个合适的建议分布是往往比较困难。另外这两种采样方法通常只适用于单变量的情形。对于多元随机变量的采样,通常是采用MCMC (Markov chain Monte Carlo)或者 Gibbs采样的方法。














 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









