







【启动顺序】
1、关闭防火墙
# service iptables stop2、启动三台zookeeper
# zkServer.sh start3、在其中一个namenode上格式化,这个步骤只需要操作一次,以后跳过这步
# hdfs namenode -format4、在其中一个namenode上初始化zkfc,这个步骤只需要操作一次,以后跳过这步
# hdfs zkfc -formatZK5、全面启动
# start-all.sh 检查namenode是否成功:在浏览器输入http://IP:50070
检查resourcemanager是否成功:在浏览器输入http://IP:8088
a) 停止全部
# stop-all.sh【用到的命令】
# yarn-daemon.sh start resourcemanager 启动resourcemanager
# start-yarn.sh 启动yarn
# start-dfs.sh 启动dfs
# scp -r xxxx root@node3:/opt 复制xxxx全部文件到node3的opt目录下
# jps 查看java进程
# killall java 删除所有java进程
# hadoop-daemon.sh start datanode 启动datanode
# hadoop-daemon.sh start journalnode 启动journalnode
# kill -9 xxxx 删除进程xxxxHA原理图:
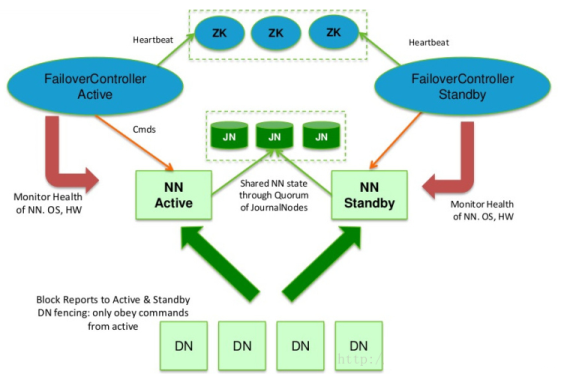
ResourceManager HA原理图:
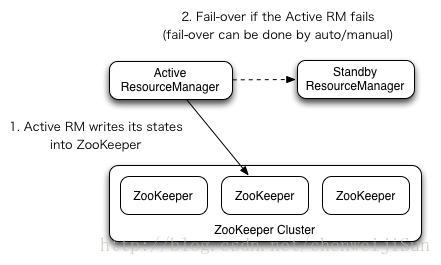
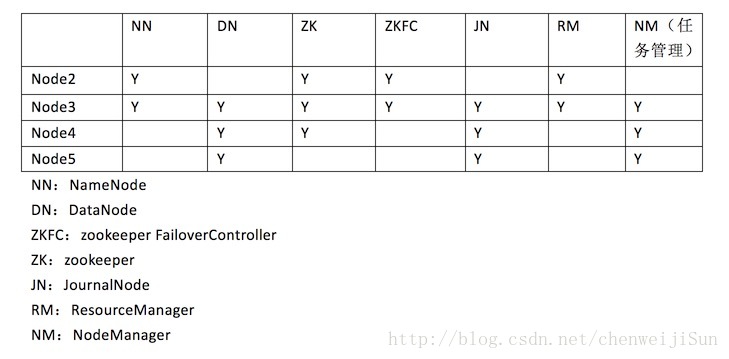
步骤:
四台机器:node2,node3,node4,node5 配置如下:
1、准备Hadoop2.x版本安装包:hadoop-2.5.1_x64.tar.gz,配置Hadoop环境变量参考:配置hadoop环境变量
2、准备zookeeper-3.4.6.tar.gz
3、将Hadoop安装到4台机器上
4、配置zookeeper
a) 三台zookeeper:node2,node3,node4
b) 在conf目录下新建zoo.cfg,编辑zoo.cfg配置文件,如下:
tickTime=2000
dataDir=/opt/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=node2:2888:3888
server.2=node3:2888:3888
server.3=node4:2888:3888c) 分别在三台zookeeper中创建一个myid的文件(myid文件在/opt/zookeeper目录下,/opt/zookeeper目录是我在zoo.cfg配置的dataDir)
# mkdir /opt/zookeeper
# vi myid在myid文件里输入对应的serverID,比如在上面的zoo.cfg文件配置中,我的node2对应的是serverID是1,那么在myid文件里就写1,同理在node3、node4机器
d) 启动zookeeper(启动前先关闭防火墙)
# service iptables stop
# /bin/zkServer.sh start启动后,会在当前目录下生成zookeeper.out文件,查看是否有异常
# tail -100 zookeeper.out5、进入hadoop安装配置文件目录下,删除maters文件,没有则忽略这一步,因为maters是配置SecondaryNameNode的,而Hadoop 2.x 采用了HA机制,已经不需要配置SecondaryNameNode了,当然也还可以用
# rm -rf /home/hadoop-2.5.1/etc/hadoop/masters6、删除Hadoop数据存储文件,文件在哪里?可以去看在core-site.xml文件中配置的hadoop.tmp.dir
# rm -rf /opt/hadoop-2.57、配置hdfs-site.xml 文件
<!-- start -->
<!-- 配置nameservicesID value填写自己定义的ID -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 配置namenode,这里我配置node2和node3为namenode, -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>node2,node3</value>
</property>
<!-- 配置2台namenode的rpc、http协议 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.node2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.node3</name>
<value>node3:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node3</name>
<value>node3:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.node3</name>
<value>node3:50070</value>
</property>
<!-- 配置共享edits文件的url,实际上是配置JournalNode的主机名和端口号,准备3台独立的JournalNode主机,这里为了方便就用node3、node4、node5作为JournalNode主机-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<!-- 配置failoverController -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 远程控制执行命令的时候,需要用到ssh的私钥,在你/root/.ssh/目录下的id_dsa文件,没有则执行# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!-- 配置JournalNode数据存放目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalnode</value>
</property>
<!-- 启用自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>8、配置core-site.xml 文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.5</value>
</property>
<!-- 配置zookeeper集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
9、配置yarn环境:yarn-site.xml
<!-- 启用resourcemanager自动切换 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置resourcemanager服务ID 不能与nameservices服务ID相同-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster2</value>
</property>
<!-- 配置resourcemanagerID -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1、rm2的主机名分别为node2(主)、node3(备) -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node3</value>
</property>
<!-- 为resourcemanager配置zookeeper集群 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<!-- 配置MapReduce,使之能够在yarn环境运行-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>10、配置mapred-site.xml,将MapReduce执行在yarn环境里
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>11、配置hadoop中的slaves文件(/etc/hadoop/slaves是配置datanode)
node3
node4
node512、配置2台namenode主机可以互相免密码登录,我的2台namenode分别是node2和node3,除此之外也要配置与datanode主机免密码登录
#ssh node2
#ssh node3一旦发现2台中任意一台需要输入密码,则重新配置
a) 删除~/.ssh目录下文件
b) 执行
# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keysc) 将node2公钥拷贝node3并追加到authorized_keys文件中去
@node2# scp ~/.ssh/id_dsa.pub root@node3 /opt/
@node3# cat /opt/id_dsa.pub >> ~/.ssh/authorized_keysd) 将node3公钥拷贝node2并追加到authorized_keys文件中去
@node3# scp ~/.ssh/id_dsa.pub root@node2 /opt/
@node2# cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys13、启动三个JournalNode:
# ./hadoop-daemon.sh start journalnode检查./logs/目录下journalnode.log日志是否出现异常,没有则启动成功
12、在其中一个namenode上格式化(初始化操作,只有一次,后面启动不再需要):我的是node2和node3作为namenode
# hdfs namenode -format14、把刚刚格式化之后的元数据拷贝到另外一个namenode上
# scp -r hadoop-2.5 root@node3:/opt/15、在其中一个namenode上初始化zkfc
# hdfs zkfc -formatZK16、开始启动、关闭是stop-dfs.sh
# start-dfs.sh启动过程中发现:node3: datanode running as process 1851. Stop it first 意思就是在node3上已经有个datanode进程了,于是去node3里删掉datanode进程,再单独启动node3的datanode
# kill -9 1851
# hadoop-daemon.sh start datanode17、启动浏览器打开namenode页面
http://node2:50070
http://node3:50070打开后发现node2和node3其中一台处于active状态、一台处于standby状态即可判断启动成功。
测试一下关闭node2的namenode,看看node3会不会接管node2。
要关闭namenode,杀掉namenode进程即可,查看java进程使用jps命令
18、启动yarn,如果有备用的resourcemanager,也要在相应的机器上启动
# start-yarn.sh启动备用的resourcemanager
# yarn-daemon.sh start resourcemanager打开浏览器,检查是否开启成功
http://node2:8088
http://node3:8088













 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









