









能否让HTML内容更加“友好”的显示?
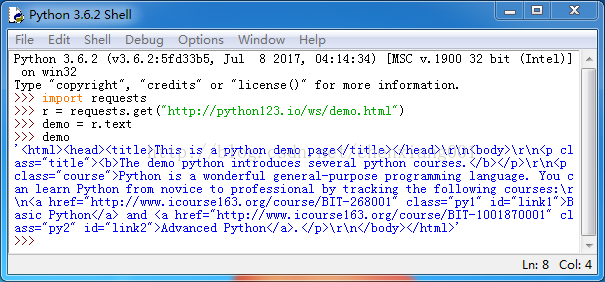
bs4库的prettify()方法
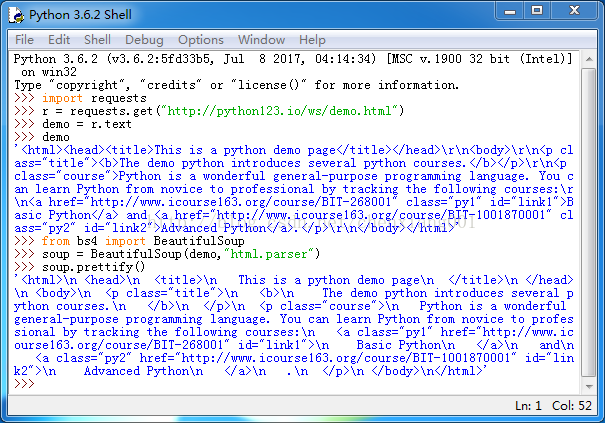
它在每个后面增加了换行符,将其打印出来
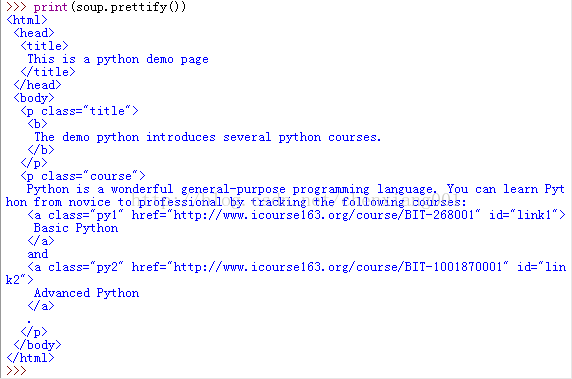
.prettify()为HTML文本<>及其内容增加更加'\n'
.prettify()可用于标签,方法:<tag>.prettify()
>>> print(soup.a.prettify())
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
>>>
bs4库的编码
bs4库将任何HTML输入都变成utf‐8编码
Python 3.x默认支持编码是utf‐8,解析无障碍
>>> soup = BeautifulSoup("<p>中文</p>","html.parser")
>>> soup.p.string
'中文'
>>> print(soup.p.prettify())
<p>
中文
</p>














 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









