







1 Malloc与new 的区别
1,malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
2,对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
3,因此C++语言需要一个能完成动态内存分配和初始化工作的运算符new,以一个能完成清理与释放内存工作的运算符delete。注意new/delete不是库函数。
4,C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存
new 是个操作符,和什么"+","-","="...有一样的地位.
malloc是个分配内存的函数,供你调用的.
new是保留字,不需要头文件支持.
malloc需要头文件库函数支持.
new 建立的是一个对象,
malloc分配的是一块内存.
new建立的对象你可以把它当成一个普通的对象,用成员函数访问,不要直接访问它的地址空间
malloc分配的是一块内存区域,就用指针访问好了,而且还可以在里面移动指针.
简而言之:
new 是一个操作符,可以重载
malloc是一个函数,可以覆盖
new 初始化对象,调用对象的构造函数,对应的delete调用相应的析构函数
malloc仅仅分配内存,free仅仅回收内存
2 C/C++中volatile关键字详解
1. 为什么用volatile?
C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier。这是 BS 在 "The C++ Programming Language" 对 volatile 修饰词的说明:
A volatile specifier is a hint to a compiler that an object may change its value in ways not specified by the language so thataggressive optimizations must be avoided.
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。声明时语法:int volatile vInt; 当要求使用 volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。例如:
1 | volatileinti=10; |
2 | inta = i; |
3 | ... |
4 | // 其他代码,并未明确告诉编译器,对 i 进行过操作 |
5 | intb = i; |
volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取,因而编译器生成的汇编代码会重新从i的地址读取数据放在 b 中。而优化做法是,由于编译器发现两次从 i读数据的代码之间的代码没有对 i 进行过操作,它会自动把上次读的数据放在 b 中。而不是重新从 i 里面读。这样以来,如果 i是一个寄存器变量或者表示一个端口数据就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。注意,在 VC 6 中,一般调试模式没有进行代码优化,所以这个关键字的作用看不出来。下面通过插入汇编代码,测试有无 volatile 关键字,对程序最终代码的影响:
输入下面的代码:
01 | #include <stdio.h> |
02 |
03 | voidmain() |
04 | { |
05 | inti = 10; |
06 | inta = i; |
07 |
08 | printf("i = %d", a); |
09 |
10 | // 下面汇编语句的作用就是改变内存中 i 的值 |
11 | // 但是又不让编译器知道 |
12 | __asm { |
13 | mov dword ptr [ebp-4], 20h |
14 | } |
15 |
16 | intb = i; |
17 | printf("i = %d", b); |
18 | } |
然后,在 Debug 版本模式运行程序,输出结果如下:
i = 10 i = 32
然后,在 Release 版本模式运行程序,输出结果如下:
i = 10 i = 10
输出的结果明显表明,Release 模式下,编译器对代码进行了优化,第二次没有输出正确的 i 值。下面,我们把 i 的声明加上 volatile 关键字,看看有什么变化:
01 | #include <stdio.h> |
02 |
03 | voidmain() |
04 | { |
05 | volatileinti = 10; |
06 | inta = i; |
07 |
08 | printf("i = %d", a); |
09 | __asm { |
10 | mov dword ptr [ebp-4], 20h |
11 | } |
12 |
13 | intb = i; |
14 | printf("i = %d", b); |
15 | } |
分别在 Debug 和 Release 版本运行程序,输出都是:
i = 10 i = 32
这说明这个 volatile 关键字发挥了它的作用。其实不只是“内嵌汇编操纵栈”这种方式属于编译无法识别的变量改变,另外更多的可能是多线程并发访问共享变量时,一个线程改变了变量的值,怎样让改变后的值对其它线程 visible。一般说来,volatile用在如下的几个地方:
1) 中断服务程序中修改的供其它程序检测的变量需要加volatile;
2) 多任务环境下各任务间共享的标志应该加volatile;
3) 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
2.volatile 指针
和 const 修饰词类似,const 有常量指针和指针常量的说法,volatile 也有相应的概念:
-
修饰由指针指向的对象、数据是 const 或 volatile 的:
1constchar* cpch;2volatilechar* vpch;注意:对于 VC,这个特性实现在 VC 8 之后才是安全的。
-
指针自身的值——一个代表地址的整数变量,是 const 或 volatile 的:
1char*constpchc;2char*volatilepchv;
注意:(1) 可以把一个非volatile int赋给volatile int,但是不能把非volatile对象赋给一个volatile对象。
(2) 除了基本类型外,对用户定义类型也可以用volatile类型进行修饰。
(3) C++中一个有volatile标识符的类只能访问它接口的子集,一个由类的实现者控制的子集。用户只能用const_cast来获得对类型接口的完全访问。此外,volatile向const一样会从类传递到它的成员。
3. 多线程下的volatile
有些变量是用volatile关键字声明的。当两个线程都要用到某一个变量且该变量的值会被改变时,应该用volatile声明,该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中。如果变量被装入寄存器,那么两个线程有可能一个使用内存中的变量,一个使用寄存器中的变量,这会造成程序的错误执行。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值,如下:
这个关键字是用来设定某个对象的存储位置在内存中,而不是寄存器中。因为一般的对象编译器可能会将其的拷贝放在寄存器中用以加快指令的执行速度,例如下段代码中:
3 C++ 智能指针
智能指针(Smart Pointer),是一个来用存储指向动态分配(堆)对象指针的类。简单的说,它本身是一个类,这个类是用来存储对象指针。
一、智能指针的介绍
智能指针,就是具备指针功能同时提供安全内存回收的一个类。它是用一个对象来对指针进行建模,使之具有指针的特性,跟指针具有相同含义的 -> 和 * 操作.并且通过对象的构造函数(获取资源),析构资源(释放资源)来对资源进行管理,从而减少程序员对通过new操作获取到的对象的生命周期进行管理的负担。
除了能够在适当的时间自动删除指向的对象外,他们的工作机制很像C++的内置指针。智能指针在面对异常的时候格外有用,因为他们能够确保正确的销毁动态分配的对象,他们也可以用于跟踪被多用户共享的动态分配对象。
事实上,智能指针能够做的还有很多事情,例如处理线程安全,提供写时复制,确保协议,并且提供远程交互服务。有能够为这些ESP (Extremely Smart Pointers)创建一般智能指针的方法,但是并没有涵盖进来。智能指针的大部分使用是用于生存期控制,阶段控制。它们使用operator->和operator*来生成原始指针,这样智能指针看上去就像一个普通指针。
1. 泛型指针
泛型指针,是指数据类型不确定的指针,它有多种含义:
(1) 指void*指针,可以指向任意数据类型,因此具有“泛型”含义。
(2) 指具有指针特性的泛型数据结构,包含泛型的迭代器、智能指针等。
广义的迭代器是一种不透明指针,能够实现遍历访问操作。通常所说的迭代器是指狭义的迭代器,即基于C++的STL中基于泛型的iterator_traits实现的类的实例。
原生指针,就是普通指针,与它相对的是使用起来行为上像指针,但却不是指针。
智能指针,是C++里面的概念,由于 C++ 语言没有自动内存回收机制,程序员每次得自己处理内存相关问题,但用智能指针便可以有效缓解这类问题,引入智能指针可以防止出现悬垂指针的情况。
五、C++智能指针的应用分析
前段时间,在查控件的内存泄露时,最终找出一个错误:
在使用XMLDom(COM)时,由于重复使用某接口指针前未释放Dispatch指针(Release),而导致内存泄露,而此类错误(如同BSTR类型的泄漏),VC的调试器和Bondcheck均无能为力。解决办法,似乎只有细心一途,但只要稍稍仔细看看,就可发现,实际上如果正确使用VC提供的智能指针,是可以避免此问题的。
另外,一直为Java程序员津津乐道的内存使用无需管理的优势,一直知道用C++的智能指针可以模拟。但一直没实际动手做过,趁此分析之机,用C++简单包装了一个。反正粗看之下,可以达到与Java类似的效果,当然,C++的对象更高效且节省内存。
就以上所提到的,简单罗列几点:
1)关于纠错,MFC和ATL中智能指针的应用
1. 在Windows中如何方便的查看当前进程使用的内存。
虽然代码简单,但对纠错时有大用处,不用不停的通过切换任务管理器来查看内存使用。代码如下:
| UINT C_BaseUtil::getProcessMemoryUsed() { UINT uiTotal = 0L; HANDLE hProcess = ::GetCurrentProcess(); PROCESS_MEMORY_COUNTERS pmc; if(::GetProcessMemoryInfo(hProcess, &pmc, sizeof(pmc))) uiTotal = pmc.WorkingSetSize; return uiTotal; } |
| IXMLDOMDocument *pDoc = NULL; CoCreateInstance(...) …… pDoc->Release(); |
| IXMLDOMNode *pNode = NULL; if(FAILED(pDoc->selectSingleNode(_bstr_t("Workbook"), &pNode)) || pNode==NULL) throw(_T("selectSingleNode failed!")); if(FAILED(pDoc->selectSingleNode(_bstr_t("Workbook"), &pNode)) || pNode==NULL) throw(_T("selectSingleNode failed!")); |
注意:可通过查看源码,看到#import生成的智能指针的原型是_com_ptr_t。
3.1
| IXMLDOMDocumentPtr docPtr = NULL; docPtr.CreateInstance(...) …… |
3.2
| IXMLDOMNodePtr nodePtr = NULL; if(FAILED(pDoc->selectSingleNode(_bstr_t("Workbook"), &nodePtr)) || nodePtr==NULL) throw(_T("selectSingleNode failed!")); if(FAILED(pDoc->selectSingleNode(_bstr_t("Workbook"), &nodePtr)) || nodePtr==NULL) throw(_T("selectSingleNode failed!")); |
| Interface** operator&() throw() { _Release(); m_pInterface = NULL; return &m_pInterface; } |
3.3
nodePtr = nodePrt2 ,也不会有问题:
仔细查看源码,在=操作符中会调用Attach,而Attach的做法是,会先调用_Release();
3.4
再看看值传递,拷贝构造函数如下
| template<> _com_ptr_t(const _com_ptr_t& cp) throw() : m_pInterface(cp.m_pInterface) { _AddRef(); } |
3.5
不要在Com智能指针的生命期如果在::CoUninitailize之后,那请在调用::CoUninitailize之前,强制调用MyComPtr = NULL;达到强制释放的目的,否则会出错。
不要混用智能指针和普通Dispatch指针,不要调用MyComPtr->Release(),这违背智能指针的原意,会在析构时报错。
4)使用ATL提供智能指针:CComPtr或是CComQIPtr
如果不使用MFC框架,要自已包装IDispatch,生成智能指针,还可以使用ATL提供的智能指针。查看源码,并参照《深入解析ATL》一书,发现实现与_com_ptr_t大同小异,效果一致。
1)标准C++的智能指针
1.1 auto_ptr要求一个对象只能有一个拥有者,严禁一物二主。
比如以下用法是错误的。
| classA *pA = new classA; auto_ptr<classA> ptr1(pA); auto_ptr<classA> ptr2(pA); |
1.2 auto_ptr是不能以传值方式进行传递的。
因为所有权的转移,会导致传入的智能指针失去对指针的所有权。如果要传递,可以采用引用方式,利用const引用方式还可以避免程序内其它方式的所有权的转移。就其所有权转移的做法:可以查看auto_ptr的拷贝构造和=操作符的源码,此处略。
1.3 其它注意事项:
a、不支持数组。
b、注意其Release语意,它没有引用计数,与com提供的智能指针不同。Release是指释放出指针,即交出指针的所有权。
c、auto_ptr在拷贝构造和=操作符时的特珠含义,决定它不能做为STL标准容器的成员。
好了,看了上面的注意事项,特别是第三条,基本上可以得出结论:在实际应用场合,auto_ptr基本没什么应用价值的。
2)如何得到支持容器的智能指针
我们利用auto_ptr的原型,制作一个引用计数的智能指针,则时让它支持STL容器的标准。实现代码很简单,参照了《C++标准程序库》中的代码,关键代码如下:
- template<class T>
- class CountedPtr {
- private:
- T *ptr = NULL;
- long *counter = NULL;
- public:
- explicit CountedPtr(T *p = NULL) : ptr(p),count(new long(1){} // 构造
- ~CountedPtr() {Release();} // 析构
- CountedPtr(cont CountedPtr<T> &p) : ptr(p.ptr),count(p.count) {++*counter;} // 拷贝构造
- // = 操作符
- CountedPtr<T>& operator= (const CountedPtr<T>& p) {
- if(this!=&p) {
- Release();
- ptr = p.ptr;
- counter = p.counter;
- ++*counter;
- }
- return *this;
- }
- // 其它略
- // ....
- private:
- void Release() {
- if(--*counter == 0) {
- delete counter;
- delete ptr;
- counter = NULL;
- ptr = NULL;
- }
- }
- }
template<class T>
class CountedPtr {
private:
T *ptr = NULL;
long *counter = NULL;
public:
explicit CountedPtr(T *p = NULL) : ptr(p),count(new long(1){} // 构造
~CountedPtr() {Release();} // 析构
CountedPtr(cont CountedPtr<T> &p) : ptr(p.ptr),count(p.count) {++*counter;} // 拷贝构造
// = 操作符
CountedPtr<T>& operator= (const CountedPtr<T>& p) {
if(this!=&p) {
Release();
ptr = p.ptr;
counter = p.counter;
++*counter;
}
return *this;
}
// 其它略
// ....
private:
void Release() {
if(--*counter == 0) {
delete counter;
delete ptr;
counter = NULL;
ptr = NULL;
}
}
}
参考推荐:
智能指针(百度百科)
Smart pointer(wiki)
android sp wp(推荐)
4 反汇编实地考察C++内存布局和虚函数实现机制
一、一个VC中的问题引发的思考
前些日子在网上看到一篇非常热的帖子,里面是这样一个问题:
#include <iostream>
usingnamespace std;
class Base
{
public:
int m_base;
virtualvoid f() { cout <<"Base::f"<< endl; }
virtualvoid g() { cout <<"Base::g"<< endl; }
};
class Derive : public Base
{
int m_derived;
};
typedef void(*Fun)(void);
void main()
{
Base *d =new Derive;
Fun pFun = (Fun)*((int*)*(int*)(d)+0);
printf("&(Base::f): 0x%x /n", &(Base::f));
printf("&(Base::g):0x%x /n", &(Base::g));
printf("pFun: 0x%x /n", pFun);
pFun();
}
在打印的时候发现pFun的地址和 &(Base::f)的地址竟然不一样太奇怪了?经过一番深入研究,终于把这个问题弄明白了。下面就来一步步进行剖析。
根据VC的虚函数的布局机制,上述的布局如下:

然后我们再细细的分析第一种方式:
Fun pFun = (Fun)*((int*)*(int*)(d)+0);
d是一个类对象的地址。而在32位机上指针的大小是4字节,因此*(int*)(&d)取得的是vfptr,即虚表的地址。从而*((int*)*(int*)(&d)+0)是虚表的第1项,也就是Base::f()的地址。事实上我们得到了验证,程序运行结果如下:

这说明虚表的第一项确实是虚函数的地址,上面的VC虚函数的布局也确实木有问题。
但是,接下来就引发了一个问题,为什么&(Base::F)和PFun的值会不一样呢?既然PFun的值是虚函数f的地址,那&(Base::f)又是什么呢?带着这个问题,我们进行了反汇编。
printf("&(Base::f): 0x%x /n", &(Base::f));
00401068 mov edi,dword ptr [__imp__printf (4020D4h)]
0040106E push offset Base::`vcall'{0}' (4013A0h)
00401073 push offset string"&(Base::f): 0x%x /n" (40214Ch)
00401078 call edi
printf("&(Base::g): 0x%x /n", &(Base::g));
0040107A push offset Base::`vcall'{4}' (4013B0h)
0040107F push offset string"&(Base::g): 0x%x /n" (402160h)
00401084 call edi
那么从上面我们可以清楚的看到:
Base::f 对应于Base::`vcall'{0}' (4013A0h)
Base::g对应于Base::`vcall'{4}' (4013B0h)
那么Base::`vcall'{0}'和Base::`vcall'{4}'到底是什么呢,继续进行反汇编分析
Base::`vcall'{0}':
004013A0 mov eax,dword ptr [ecx]
004013A2 jmp dword ptr [eax]
......
Base::`vcall'{4}':
004013B0 mov eax,dword ptr [ecx]
004013B2 jmp dword ptr [eax+4]
第一句中, 由于ecx是this指针, 而在VC中一般虚表指针是类的第一个成员, 所以它是把vfptr, 也就是虚表的地址存到了eax中. 第二句
相当于取了虚表的某一项。对于Base::f跳转到Base::`vcall'{0}',取了虚表的第1项;对于Base::g跳转到Base::`vcall'{4}',取了虚表第2项。由此都能够正确的获得虚函数的地址。
由此我们可以看出,vc对此的解决方法是由编译器加入了一系列的内部函数"vcall". 一个类中的每个虚函数都有一个唯一与之对应的vcall函数,通过特定的vcall函数跳转到虚函数表中特定的表项。
更深一步的进行讨论,考虑多态的情况,将代码改写如下:
#include <iostream>
usingnamespace std;
class Base
{
public:
virtualvoid f() { cout <<"Base::f"<< endl; }
virtualvoid g() { cout <<"Base::g"<< endl; }
};
class Derive : public Base{
public:
virtualvoid f() { cout <<"Derive::f"<< endl; }
virtualvoid g() { cout <<"Derive::g"<< endl; }
};
typedef void(*Fun)(void);
void main()
{
Base *d =new Derive;
Fun pFun = (Fun)*((int*)*(int*)(d)+0);
printf("&(Base::f): 0x%x /n", &(Base::f));
printf("&(Base::g): 0x%x /n", &(Base::g));
printf("&(Derive::f): 0x%x /n", &(Derive::f));
printf("&(Derive::g): 0x%x /n", &(Derive::g));
printf("pFun: 0x%x /n", pFun);
pFun();
}
打印的时候表现出来了多态的性质:

分析可知原因如下:

这是因为类Derive的虚函数表的各项对应的值进行了改写(rewritting),原来指向Based::f()的地址变成了指向Derive::f(),原来指向Based::g()的地址现在编变成了指向Derive::g()。
反汇编代码如下:
printf("&(Derive::f): 0x%x /n", &(Derive::f));
00401086 push offset Base::`vcall'{0}' (4013B0h)
0040108B push offset string"&(Derive::f): 0x%x /n" (40217Ch)
00401090 call esi
printf("&(Derive::g): 0x%x /n", &(Derive::g));
00401092 push offset Base::`vcall'{4}' (4013C0h)
00401097 push offset string"&(Derive::g): 0x%x /n" (402194h)
0040109C call esi
因此虽然此时Derive::f依然对应Base::`vcall'{0}',而 Derive::g依然对应Base::`vcall'{4}',但是由于每个类有一个虚函数表,因此跳转到的虚表的位置也发生了改变,同时因为进行了改写,虚表中的每个slot项的值也不一样。
稍微总结一下:
在VC中有两种方法调用虚函数,一种是通过虚表,另外一种是通过vcall thunk的方式
通过虚表的方式:
base*d =new Derive;
d->f();
004115FA mov eax,dword ptr [d]
004115FD mov edx,dword ptr [eax]
004115FF mov esi,esp
00411601 mov ecx,dword ptr [d]
00411604 mov eax,dword ptr [edx]
00411606 call eax
00411608 cmp esi,esp
0041160A call @ILT+470(__RTC_CheckEsp) (4111DBh)
这种方式的应用环境是通过类对象的指针或引用来调用虚函数
通过vcall thunk的方式:
typedef void (Base::* func1)( void );
base*d =new Derive;
func1 pFun1 =&Base::f;
(d->*pFun1)();
004115A9 mov dword ptr [pFun1],offset Base::`vcall'{0}' (4110C3h)
004115B0 mov esi,esp
004115B2 lea ecx,[d]
004115B5 call dword ptr [pFun1]
004115B8 cmp esi,esp
004115BA call @ILT+460(__RTC_CheckEsp) (4111D1h)
这种方式对应的应用环境是通过类成员函数的指针来调用虚函
二、反汇编实地考察C++虚函数
诚然,C++虚函数的结构会因编译器不同而异,但所使用的原理是一样的。为此,本文使用linux平台下的g++编译器,试图从汇编的层面上分析虚函数表的结构,以及如何利用它来实现运行时多态。
汇编语言是难读的,特别是对一些没有汇编基础的朋友,因此,本文将汇编翻译成相应的C语言,以方便读者分析问题。
1. 代码
为了方便表述问题,本文选取只有虚函数的两个类,当然,还有它的构造函数,如下:
class Base
{
public:
virtualvoid f() { }
virtualvoid g() { }
};
class Derive : public Base
{
public:
virtualvoid f() {}
};
int main()
{
Derive d;
Base *pb;
pb =&d;
pb->f();
return0;
}
2. 两个类的虚函数表(vtable)
使用g++ –Wall –S test.cpp命令,可以将上述的C++代码生成它相应的汇编代码。
_ZTV4Base:
.long 0
.long _ZTI4Base
.long _ZN4Base1fEv
.long _ZN4Base1gEv
.weak _ZTS6Derive
.section .rodata._ZTS6Derive,"aG",@progbits,_ZTS6Derive,comdat
.type _ZTS6Derive, @object
.size _ZTS6Derive, 8
_ZTV4Base是一个数据符号,它的命名规则是根据g++的内部规则来命名的,如果你想查看它真正表示C++的符号名,可使用c++filt命令来转换,例如:
[lyt@t468 ~]$ c++filt _ZTV4Base
vtable for Base
_ZTV4Base符号(或者变量)可看作为一个数组,它的第一项是0,第二项_ZIT4Base是关于Base的类型信息,这与typeid有关。为方便讨论,我们略去此二项数据。 因此Base类的vtable的结构,翻译成相应的C语言定义如下:
unsigned long Base_vtable[] = {
&Base::f(),
&Base::g(),
};
而Derive的更是类似,只有稍为有点不同:
_ZTV6Derive:
.long 0
.long _ZTI6Derive
.long _ZN6Derive1fEv
.long _ZN4Base1gEv
.weak _ZTV4Base
.section .rodata._ZTV4Base,"aG",@progbits,_ZTV4Base,comdat
.align 8
.type _ZTV4Base, @object
.size _ZTV4Base, 16
相应的C语言定义如下:
unsigned long Derive_vtable[] = {
&Derive::f(),
&Base::g(),
};
从上面两个类的vtable可以看到,Derive的vtable中的第一项重写了Base类vtable的第一项。只要子类重写了基类的虚函数,那么子类vtable相应的项就会更改父类的vtable表项。 这一过程是编译器自动处理的,并且每个的类的vtable内容都放在数据段里面。
3. 谁让对象与vtable绑到一起
上述代码只是定义了每个类的vtable的内容,但我们知道,带有虚函数的对象在它内部都有一个vtable指针,指向这个vtable,那么是何时指定的呢? 只要看看构造函数的汇编代码,就一目了然了:
Base::Base()函数的编译代码如下:
_ZN4BaseC1Ev:
.LFB6:
.cfi_startproc
.cfi_personality 0x0,__gxx_personality_v0
pushl %ebp
.cfi_def_cfa_offset 8
movl %esp, %ebp
.cfi_offset 5, -8
.cfi_def_cfa_register 5
movl 8(%ebp), %eax
movl $_ZTV4Base+8, (%eax)
popl %ebp
ret
.cfi_endproc
ZN4BaseC1Ev这个符号是C++函数Base::Base() 的内部符号名,可使用c++flit将它还原。C++里的class,可以定义数据成员,函数成员两种。但转化到汇编层面时,每个对象里面真正存放的是数据成员,以及虚函数表。
在上面的Base类中,由于没有数据成员,因此它只有一个vtable指针。故Base类的定义,可以写成如下相应的C代码:
struct Base {
unsigned long**vtable;
}
构造函数中最关键的两句是:
movl 8(%ebp), %eax
movl $_ZTV4Base+8, (%eax)
$_ZTV4Base+8 就是Base类的虚函数表的开始位置,因此,构造函数对应的C代码如下:
void Base::Base(struct Base *this)
{
this->vtable =&Base_vtable;
}
同样地,Derive类的构造函数如下:
struct Derive {
unsigned long**vtable;
};
void Derive erive(struct Derive *this)
erive(struct Derive *this)
{
this->vtable =&Derive_vtable;
}
4. 实现运行时多态的最关键一步
在造构函数里面设置好的vtable的值,显然,同一类型所有对象内的vtable值都是一样的,并且永远不会改变。下面是main函数生成的汇编代码,它展示了C++如何利用vtable来实现运行时多态。
.globl main
.type main, @function
main:
.LFB3:
.cfi_startproc
.cfi_personality 0x0,__gxx_personality_v0
pushl %ebp
.cfi_def_cfa_offset 8
movl %esp, %ebp
.cfi_offset 5, -8
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
leal 24(%esp), %eax
movl %eax, (%esp)
call _ZN6DeriveC1Ev
leal 24(%esp), %eax
movl %eax, 28(%esp)
movl 28(%esp), %eax
movl (%eax), %eax
movl (%eax), %edx
movl 28(%esp), %eax
movl %eax, (%esp)
call *%edx
movl $0, %eax
leave
ret
.cfi_endproc
andl $-16, %esp
subl $32, %esp
这两句是为局部变量d和bp在堆栈上分配空间,也即如下的语句:
Derive d;
Base *pb;
leal 24(%esp), %eax
movl %eax, (%esp)
call _ZN6DeriveC1Ev
esp+24是变量d的首地址,先将它压到堆栈上,然后调用d的构造函数,相应翻译成C语言则如下:
Deriveervice(&d);
leal 24(%esp), %eax
movl %eax, 28(%esp)
这里其实是将&d的值赋给pb,也即:
pb = &d;
最关键的代码是下面这一段:
movl 28(%esp), %eax
movl (%eax), %eax
movl (%eax), %edx
movl 28(%esp), %eax
movl %eax, (%esp)
call *%edx
翻译成C语言也就传神的那句:
pb->vtable[0](bp);
编译器会记住f虚函数放在vtable的第0项,这是编译时信息。
5. 小结
这里省略了很多关于编译器和C++的细枝未节,是出于讨论方便用的需要。从上面的编译代码可以看到以下信息:
1.每个类都有各有的vtable结构,编译会正确填写它们的虚函数表
2. 对象在构造函数时,设置vtable值为该类的虚函数表
3.在指针或者引用时调用虚函数,是通过object->vtable加上虚函数的offset来实现的。
当然这仅仅是g++的实现方式,它和VC++的略有不同,但原理是一样的。
三、反汇编实地考察C++对象模型
1. C++基本对象的组成
尽管C++社区最近十年兴起元编程范式和模板技术,面向对象编程仍是C++语言最基础,也是最重要的一种编程范式(paradigms)。C++的对象,将过程式的数据结构,以及操作在它们之上的函数,绑定到一个单一的语法单元,那就是类(class)。C++世界里,活生生的个体联系就是所有类的对象所进行的消息传递,对象协作而构成千变万化的世界。但对象的内部结构,对象的产生和消亡,数据成员和函数成员的结构,困扰了无数初学者。
C++基本对象由以下几方面元素组成:
对象数据成员(非静态数据成员)
类数据成员(静态数据成员)
函数成员
静态函数成员
这里,我们不考虑类的单继承,多重继承以及虚函数等复杂的特性。
下面我们对C++基本对象进行抽丝剥茧,深入分析对象的内存布局,与之相关的静态变量,成员函数。
2. 一个简单的例子
为简单起见,本文以class point为例子,它包含构造函数,析构函数,函数成员,对象变量,类变量和静态成员函数等语法结构。它的代码如下
class point
{
public:
point(int x, int y)
{
this->x = x;
this->y = y;
ins_cnt++;
}
~point()
{
ins_cnt--;
}
staticint get_instances()
{
return ins_cnt;
}
point & move(int addx, int addy)
{
this->x += addx;
this->y += addy;
return*this;
}
private:
int x, y;
staticint ins_cnt;
};
int point::ins_cnt =0;
int main()
{
point x(3, 4);
x.move(10, 10);
int p_ins_cnt = point::get_instances();
return0;
}
3. 编译生成汇编文件和可执行文件
g++命令行提供了简便方式来生成这两种文件,我们在下面根据实际需要来对这两文件进行分析,从而深入理解point对象的内存布局。
g++命令使用如下:
[lyt@t468 ~]$ g++ -g -o object object.cpp
[lyt@t468 ~]$ g++ -g -S -o object.s object.cpp
object.s文件生成的汇编比较凌乱,因为它里面的符号还未重定位,只是使用一些符号来表示某些以后要分配内存的变量,编译器使用的变量或符号。因此,我们可以利用它来分析某些C++变量经编译器处理后,在汇编层面上的符号名称。
object文件可用来供gdb调试工具来使用,gdb可以对源代码以函数为单位,对每一行语句进行反汇编。
4. 所有与point类相关的符号
C++源代码生成可执行文件(linux下称为ELF格式文件)后,它专门有一个符号节区来记录执行文件中各个符号的类型,地址等相关信息。为了便于分析,我们使用readelf工具对生成的object文件,找出与point类相关的所有符号,以及使用c++filt工具,将这些符号转变成C++语言级别上的语义,如下:
[lyt@t468 ~]$ readelf -s object | grep point
41: 08048530 10 FUNC WEAK DEFAULT 13 _ZN5point13get_instancesE
49: 0804853a 40 FUNC WEAK DEFAULT 13 _ZN5point4moveEii
56: 080484fa 35 FUNC WEAK DEFAULT 13 _ZN5pointC1Eii
58: 0804851e 18 FUNC WEAK DEFAULT 13 _ZN5pointD1Ev
59: 0804a01c 4 OBJECT GLOBAL DEFAULT 25 _ZN5point7ins_cntE
[lyt@t468 ~]$ c++filt _ZN5point13get_instancesE
point::get_instances
[lyt@t468 ~]$ c++filt _ZN5point4moveEii
point::move(int, int)
[lyt@t468 ~]$ c++filt _ZN5pointC1Eii
point::point(int, int)
[lyt@t468 ~]$ c++filt _ZN5pointD1Ev
point::~point()
[lyt@t468 ~]$ c++filt _ZN5point7ins_cntE
point::ins_cnt
从上面的结果可以看出来,point类的构造函数,析构函数,move成员函数,get_instances静态成员函数都对应一个函数符号。而令我们感到意外的是,point类的静态变量ins_cnt也对应一个全局变量符号,它的地址是0804a01c;下面对地址0804a01c 的读写汇编语言,都意味着相应的C++函数读写该变量,也即point类的静态变量。
5. point对象的内存布局和构造函数
对象的生命始于构造函数,而在执行构造函数之前,对象还处于混沌状态。在构造函数里面,它按对象内存所包含的每个成员依次进行初始化,因此我们从对象的构造函数就可以一窥它的内存布局。
为了方便大家较对C++源代码和汇编代码,使用gdb对point类的构造函数按源代码行进行反汇编。结果如下:
- (gdb) disassemble /m _ZN5pointC1Eii
- Dump of assembler code for function point:
- 5 point(int x, int y)
- 0x080484fa <point+0>: push ebp
- 0x080484fb <point+1>: mov ebp,esp
- 6 {
- 7 this->x = x;
- 0x080484fd <point+3>: mov eax,DWORD PTR [ebp+0x8]
- 0x08048500 <point+6>: mov edx,DWORD PTR [ebp+0xc]
- 0x08048503 <point+9>: mov DWORD PTR [eax],edx
- 8 this->y = y;
- 0x08048505 <point+11>: mov eax,DWORD PTR [ebp+0x8]
- 0x08048508 <point+14>: mov edx,DWORD PTR [ebp+0x10]
- 0x0804850b <point+17>: mov DWORD PTR [eax+0x4],edx
- 9 ins_cnt++;
- 0x0804850e <point+20>: mov eax,ds:0x804a01c
- 0x08048513 <point+25>: add eax,0x1
- 0x08048516 <point+28>: mov ds:0x804a01c,eax
- 10 }
- 0x0804851b <point+33>: pop ebp
- 0x0804851c <point+34>: ret
- End of assembler dump.
为了让大家更清楚构造函数到底作了什么事情,我对上面的汇编语句逐行分析:
7 this->x = x;
0x080484fd <point+3>: mov eax,DWORD PTR [ebp+0x8]
0x08048500 <point+6>: mov edx,DWORD PTR [ebp+0xc]
0x08048503 <point+9>: mov DWORD PTR [eax],edx
mov eax,DWORD PTR [ebp+0x8] 将函数第一个参数的值存放到寄存器eax中
mov edx,DWORD PTR [ebp+0xc] 将函数第二个参数的值存放到寄存器edx中
mov DWORD PTR [eax],edx 将edx寄存器的值写到eax所指向的内存中
结合this->x = x;这个C++代码,我们可以大胆推测,point构造函数生成汇编后,它对应的函数名(或者符号名)为
_ZN5pointC1Eii。该函数的第一个参数为this,类型为point类内存布局的表示类型,我们姑且称为struct point *类型;第二参数为int类型的x。
接下来的this->y = y;语句的反汇编,与上面this->x = x; 语句如同一辙,唯有x和y在point对象的内存偏移量不同。
从而得出,x成员在point对象内存的偏移量为0,而y的为4。
比较迷惑的是最后这句:
9 ins_cnt++;
0x0804850e<point+20>: mov eax,ds:0x804a01c
0x08048513<point+25>: add eax,0x1
0x08048516<point+28>: mov ds:0x804a01c,eax
第一个mov是将内存0x804a01c的值读到eax中,add指令是将eax加1,最后一个mov是将eax最后的值写回到内存中。还记得0x804a01c是哪个符号的地址吗?没错,它就是point类静态变量ins_cnt的地址。
由此,我们可以使用point类的对象在内存的布局如下:
struct point {
int x;
int y;
};
// point::ins_cnt 变量,在汇编层面上,它是一个全局变量
int point_ins_cnt =0;
它的构造函数翻译成如下:
void point::point(struct point *this, int x, int y)
{
this->x = x;
this->y = y;
point_ins_cnt++;
}
正如你早已知道的秘密,C++编译器悄悄地将你写的非静态函数成员(当然包括构造函数的析构函数)加上this指针作为第一个参数,这就是C++资料上所说的this隐藏参数。在汇编的曝光下,这一切都真相大白了。
下面是move成员函数反汇编的结果,如有不明白,可以对比分析一下:
- (gdb) disassemble /m _ZN5point4moveEii
- Dump of assembler code for function _ZN5point4moveEii:
- 22 point & move(int addx, int addy)
- 0x0804853a <_ZN5point4moveEii+0>: push ebp
- 0x0804853b <_ZN5point4moveEii+1>: mov ebp,esp
- 23 {
- 24 this->x += addx;
- 0x0804853d <_ZN5point4moveEii+3>: mov eax,DWORD PTR [ebp+0x8]
- 0x08048540 <_ZN5point4moveEii+6>: mov eax,DWORD PTR [eax]
- 0x08048542 <_ZN5point4moveEii+8>: mov edx,eax
- 0x08048544 <_ZN5point4moveEii+10>: add edx,DWORD PTR [ebp+0xc]
- 0x08048547 <_ZN5point4moveEii+13>: mov eax,DWORD PTR [ebp+0x8]
- 0x0804854a <_ZN5point4moveEii+16>: mov DWORD PTR [eax],edx
- 25 this->y += addy;
- 0x0804854c <_ZN5point4moveEii+18>: mov eax,DWORD PTR [ebp+0x8]
- 0x0804854f <_ZN5point4moveEii+21>: mov eax,DWORD PTR [eax+0x4]
- 0x08048552 <_ZN5point4moveEii+24>: mov edx,eax
- 0x08048554 <_ZN5point4moveEii+26>: add edx,DWORD PTR [ebp+0x10]
- 0x08048557 <_ZN5point4moveEii+29>: mov eax,DWORD PTR [ebp+0x8]
- 0x0804855a <_ZN5point4moveEii+32>: mov DWORD PTR [eax+0x4],edx
- 26
- 27 return *this;
- 0x0804855d <_ZN5point4moveEii+35>: mov eax,DWORD PTR [ebp+0x8]
- 28 }
- 0x08048560 <_ZN5point4moveEii+38>: pop ebp
- 0x08048561 <_ZN5point4moveEii+39>: ret
- End of assembler dump.
6. 静态成员函数
是否还记得静态函数成员不能使用非静态变量成员?为什么不能使用非静态变量成员呢?原因很简单,是因为静态函数成员没有this参数。C++的静态函数成员,和静态数据成员一样,是属于类的,而不是属于对象的,访问它们时,不需要使用任何现成的对象,直接使用<class-name>::<member>形式即可,所以它的函数不需要this指针。
下面point::get_instances()函数反汇编的结果:
- (gdb) disassemble /m _ZN5point13get_instancesEv
- Dump of assembler code for function _ZN5point13get_instancesEv:
- 17 static int get_instances()
- 0x08048530 <_ZN5point13get_instancesEv+0>: push ebp
- 0x08048531 <_ZN5point13get_instancesEv+1>: mov ebp,esp
- 18 {
- 19 return ins_cnt;
- 0x08048533 <_ZN5point13get_instancesEv+3>: mov eax,ds:0x804a01c
- 20 }
- 0x08048538 <_ZN5point13get_instancesEv+8>: pop ebp
- 0x08048539 <_ZN5point13get_instancesEv+9>: ret
- End of assembler dump.
在函数体内,没有从堆栈里面读取任何参数信息,我们可以认为该函数是没有带参数,即它的参数型类为void。
实我们可以从调用该函数的地方去验证。下面是main函数反汇编的部分结果:
39 x.move(10, 10);
0x080484ba<main+38>: mov DWORD PTR [esp+0x8],0xa
0x080484c2<main+46>: mov DWORD PTR [esp+0x4],0xa
0x080484ca<main+54>: lea eax,[esp+0x14]
0x080484ce<main+58>: mov DWORD PTR [esp],eax
0x080484d1<main+61>: call 0x804853a<_ZN5point4moveEii>
40
41 int p_ins_cnt = point::get_instances();
0x080484d6<main+66>: call 0x8048530<_ZN5point13get_instancesEv>
0x080484db<main+71>: mov DWORD PTR [esp+0x1c],eax
在x.move(10, 10);调用时,它使用了两个mov …, 0xa将常量10压入堆栈中,作为_ZN5point4moveEii函数的第二和第三个参数,第一个当然是this拉。
而x.move(10, 10) 调用完后,它接着call _ZN5point13get_instancesEv,说明_ZN5point13get_instancesEv函数不带任何参数。
因此point::get_instances()函数翻译成C语言代码相应如下:
int point::get_instances(void)
{
return point_ins_cnt;
}
7. 总结
不考虑C++虚函数,继承等语法功能后的C++基本对象内存布局模式格外简单。具有以下特点:
1)class内定义的非静态数据成员,它将占用对象的内存,它的布局类似于一种相应的结构体定义相应的字符。
2) class内定义的静态数据成员,它是类变量,每种类只有唯一的一份,它以全局变量的身份挤身于全局变量列表。当然g++可根据它的初始化值是否为0来安排它放在.bss节区还是.data节区。
3)非静态函数成员,不占用对象的内存,它经C++编译器处理后,它是一个全局函数,它的第一个参数为this指针,其余参数类型和名字,与用户定义的一致。
4) 静态函数成员,同样不占用对象的内存,它经C++编译器处理后,它是一个全局函数,它没有this指针,它的参数类型和名字与用户定义的一致
5 float类型数据内存分布
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
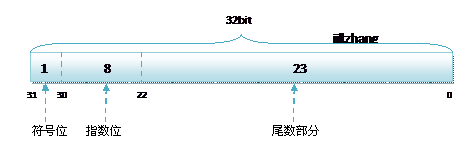
1 8 23
符号位 指数位 尾数部分
而双精度的存储方式为:

1 11 52
符号位 指数位 尾数部分
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*![]() ,而120.5可以表示为:1.205*
,而120.5可以表示为:1.205*![]() ,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.00001*
,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.00001*![]() ,1110110.1可以表示为1.1101101*
,1110110.1可以表示为1.1101101*![]() ,任何一个数都的科学计数法表示都为1.xxx*
,任何一个数都的科学计数法表示都为1.xxx*![]() ,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.25和120.5在内存中真正的存储方式。
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.00001*![]()
按照上面的存储方式,符号位为:0,表示为正,指数位为:3 127=130 ,位数部分为,故8.25的存储方式如下图所示:
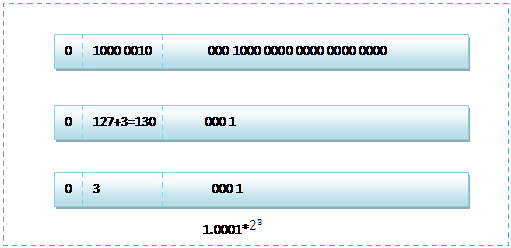
而单精度浮点数120.5的存储方式如下图所示:
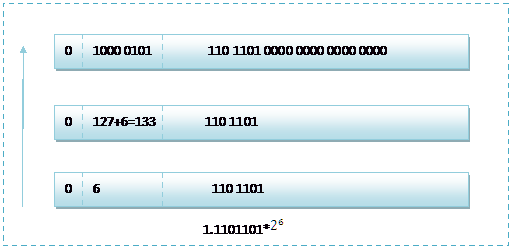
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:
![]()
根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*![]() =120.5
=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的
![]()
下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:
![]()
但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











