









简介
首先,明确问题。假如,我需要了解成都这个城市所有人口的身高情况,如果我是万能的上帝(其实不信上帝),只要告诉我某个人的生成八字我就可以知道ta的身高,但可惜我不是,如果还是想知道这个城市中任何人的身高,就只有采用统计推断的办法了,假设我知道整个城市所有人的身高分布(总体分布)情况,给定一个人的其他情况,我就能大概推断出ta的身高了,如何才能知道总体分布,不可能将所有人的分布都统计下,于是想出不同时期在人口流动比较大的地方如春熙路、磨子桥、都江堰等采集图像,再通过计算机视觉中的知识测出所有人的身高(样本分布),然后用这个样本的分布来估计总体分布,样本的分布参数来估计总体的分布参数(mean、variance)。如何才能知道我这个样本估计总体的方法是否可信?统计学告诉我们如果采集得到的身高每天都是同样情况(即最可能),则说明样本估计总体是比较可信的。很明显,这个比较可信依赖于采样的地点,成都不同地方人的身高肯定也是各不相同的,有的地方高个子多(如春熙路),有的地方高个子少,即存在概率分布的差异,于是提出了MAP方法,样本分布*概率越大,则样本估计总体越可信。
EM算法全称是expectation-maximization algorithm,它是统计学中寻找总体分布的参数的一种迭代方法,参数的好坏评价有两种途径,一个是求得的参数使得概率似然函数值最大(联合概率最大,即maximum likelihood),二是求得的参数使得后验概率函数值最大(maximum a posteriori -MAP),这两个途径都将问题归结为一个求极值的最优化问题。
用数学表达式描述分别是:

其中,分布函数f(x)可以是连续形式的高斯分布或离散形式的伯努利分布。但是要用数学表达式来求解最优参数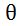
EM算法的原理
关于EM算法的整个推导过程,请参照http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
一句话说就是:反复寻找凸的目标函数的下界,使下界变大直到收敛,即反复进行E步和M步。公式化如下:
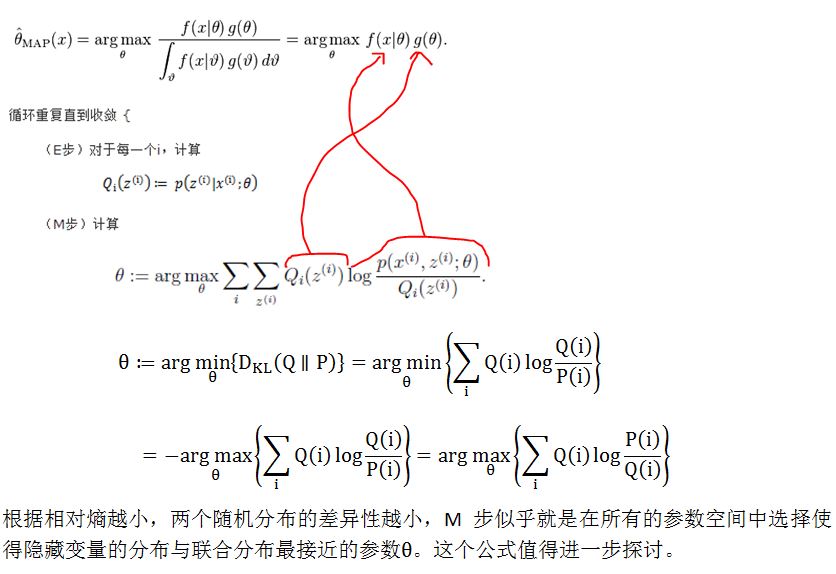
这样做可行的依据是:目标函数是凸函数(凹函数添加负号变为凸函数),收敛时Jessen不等式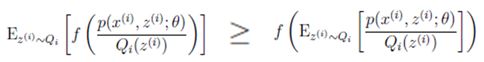
EM算法的启动和终止
算法执行的开始步骤有三种指定方式。如果使用了CvEM::START_AUTO_STEP,则会调用k-means算法估计最初的参数,K-means会随机地初始化类中心,KMEANS_PP_CENTERS,这会导致EM算法得到不同的结果,如果数据量越大,则这种差异性会变小。
如果指定CvEM::START_E_STEP或CvEM::START_M_STEP参数,则不会出现同样的输入数据,得到不同结果的现象。如果指定CvEM::START_M_STEP参数,则以M步开始,
M步固定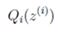
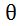
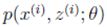
如果指定CvEM::START_E_STEP,则以E步开始,CvEMParams::means必须给出,CvEMParams::weights和CvEMParams::covs参数可给出可不给出,weights代表初始的各个成分的概率。
算法执行的终止条件。EM算法是迭代算法,自然终止条件可以是迭代次数达到了,或者两次迭代之间的差异小于epsilon就结束。
关于参数的解析,请参照机器学习中文参考手册
opencv中EM算法代码分析
CvEM::train函数中执行以下过程:
- init_params。
- emObj = EM //建立一个EM对象。
根据_params.start_step值执行不同过程,train,trainE和trainM。
这三个train过程都会返回logLikelihoods(Mat结构),_labels,probs(给定样本x属于各个类别的后验概率)。在训练之前,train函数里面会调用setTrainData准备训练数据,再调用do_train正式训练。setTrainData会做参数安全检查,如果是START_AUTO_STEP,则会打开K-means并把数据都转换成CV_32FC1。训练数据都保存到类成员trainSamples里。执行do_train过程
1.clusterTrainSamples里调用kmeans方法聚类训练集成nclusters个类,并得到各个样本的类别。Kmeans执行前要保证数据是CV_32FC1类型,执行完后要转换成CV_64FC1类型。
2.根据labels将所有数据放到nclusters个矩阵中,分别计算每个矩阵的协方差矩阵和每个类别权值(该类样本数除以样本总数)。对每个协方差矩阵做奇异值分解(SVD),得到最大的奇异值的倒数。
3.反复循环执行E步,M步,直到满足如下条件:
if(iter >= maxIters - 1)
break;
if( iter != 0 &&
(trainLogLikelihoodDelta < -DBL_EPSILON ||
trainLogLikelihoodDelta < epsilon * std::fabs(trainLogLikelihood)))
break;
trainLogLikelihoodDelta 表示两次相邻迭代过程中对数似然概率的增量。
E步,M步细节后面再更新,今天先到这里。
(转载请注明作者和出处:http://blog.csdn.net/CHIERYU 未经允许请勿用于商业用途)














 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









