






数据库的增删查改
1. 数据库的创建
语法:create [if not exists] 数据库名 [default] character set [=] 字符集 ;
注:[]表示可有可无
例如: create database db1;
2. 数据库的查看
语法:show databases
3. 数据库的修改
1) 修改表名:alter table旧表名 rename as新表名
2) 添加字段:alter table表名 add字段名 列类型(属性)
3) 修改字段:alter table表名 modify 字段名 列类型(属性)
alter table 表名 change 旧字段名 新字段名 列类型(属性)
4) 删除字段:alter table 表名drop 字段名
4. 数据库的删除
语法:drop database [if exists] 数据库名
例1删除一个存在的数据库
drop database db1;
例子2:删除一个不确定存在的数据库
-->mysql> drop database drop_database;
ERROR 1008 (HY000): Can't drop database 'drop_database'; databas e doesn't exist //发生错误,不能删除'drop_database'数据库,该数据库不存在。
-->mysql> drop database if exists drop_database;
Query OK, 0 rows affected, 1 warning (0.00 sec)//产生一个警告说明此数据库不存在
5. 使用数据库
语法:use 数据库名
use 语句可以通告MySQL把db_name数据库作为默认(当前)数据库使用,用于后续语句。该数据库保持为默认数据库,直到语段的结尾,或者直到发布一个不同的USE语句:
mysql> USE db1;
mysql> SELECT COUNT(*) FROM mytable; # selects from db1.mytable
mysql> USE db2;
mysql> SELECT COUNT(*) FROM mytable; # selects from db2.mytable
使用USE语句为一个特定的当前的数据库做标记,不会阻碍您访问其它数据库中的表,例如:
6. 建立一个表
语法:create table tab1(
字段1(属性1),
字段2(属性2),
字段3(属性3),
);
例如:mysql> create table tab2(
-> id int primary key auto_increment,
-> name varchar(20),
-> sex varchar(10)default'保密'
-> );
7. 查看表
语法:show tables from 表名
8. 删除表
语法:drop table 表名
9. 查看表结构
describe 表名
select columns from 表名
10. 添加记录
语法:insert [into] 表名 [(字段名1,字段名2,……)]values(值1,值2,…….)
例如:
第一种:省略字段名。insert tab2 values(null,'李四',default);
第二种:部分添加 insert tab2(id,name) values(null,'李四');
11. 修改记录
语法:update 表名 set 字段名 = 值[where = 条件] ;
例如: update tab2 set sex='女' where id=2;
12. 删除记录
语法:delete from表名 [where = 条件]
13. 查找记录
语法:select 字段1,字段2 from 表名
① 如果要查找全部字段使用*就可以!!!!!!!!表名
② where 语句 + 运算符
语法:select * from 表名 where 条件
select * from student where score >95.0;
③ where 语句 +and/or
mysql> select * from student where score >95.0 and score <99.0
显示分数在95-99之间的记录
mysql> select * from student where score < 95.0 or score>96.0;
显示分数小于95大于96的记录
④ where语句 + in(起始位置,偏移量)
mysql> select * from student where id in(1,2);
显示从id=1的记录开始的两条记录
⑤ where + between+and
mysql> select * from student where score between 95.0 and 99.0;
显示分数在95-99之间的记录
⑥ where+ is not null
mysql> select * from student where id is not null;
显示id不为空的记录
⑦ 使用汇总函数
1.count()
mysql> select count(score) from student ;
统计分数记录的条数
mysql> select count(*) from student where score>93.0;
得到分数大于93记录的条数
2.sum 求和
mysql> select sum(score) from student ;
3.还有max() 求最大值 min()最小值,包括求绝对值函数ABS函数、求圆周率函数PI()、求正玄值SIN()函数、求指数函数EXP()等。
4.系统函数
select version() 显示当前版本
select now() 显示当前时间日期
select user() 显示当前用户
⑧ order by+条件 排序 如果有多个排序的条件,中间用‘,’隔开
逆序:desc
mysql> select * from student order by score;
mysql> select * from student order by score desc; // 逆序输出
//分数按照从低到高的顺序排列
⑨ group by + 条件 按照给定条件分组
mysql> select sex , avg(height) as avgage from student group by sex;
按照性别来统计男女的平均身高
⑩ having 条件语句
mysql> select sex , avg(height) as avgage from student group by sex having avg(height)>175.0;
having和where的区别:
1.having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。
2.作用对象不同,having作用于组,where作用于表和视图
3.having可以包含聚合函数,而where不行。
窗体底端
11 limit [起始位置,] 偏移量 []可以不要 ,相当于where中in
mysql> select sex , avg(height) as avgage from student group by sex limit 1;
显示从开始位置开始的一条语句
mysql> select sex , avg(height) as avgage from student group by sex limit 1,1;
显示从索引1位置开始显示1条语句
12 order by+条件 排序
二、mysql子查询
1、where型子查询
(把内层查询结果当作外层查询的比较条件)
#不用order by 来查询最新的商品
select goods_id,goods_name from goods where goods_id = (select max(goods_id) from goods);
#取出每个栏目下最新的产品(goods_id唯一)
select cat_id,goods_id,goods_name from goods where goods_id in(select max(goods_id) from goods group by cat_id);
2、from型子查询
(把内层的查询结果供外层再次查询)
#用子查询查出挂科两门及以上的同学的平均成绩
思路:
#先查出哪些同学挂科两门以上
select name,count(*) as gk from stu where score < 60 having gk >=2;
#以上查询结果,我们只要名字就可以了,所以再取一次名字
select name from (select name,count(*) as gk from stu having gk >=2) as t;
#找出这些同学了,那么再计算他们的平均分
select name,avg(score) from stu where name in (select name from (select name,count(*) as gk from stu having gk >=2) as t) group by name;
3、exists型子查询 返回的是一个布尔型
(把外层查询结果拿到内层,看内层的查询是否成立)
#查询哪些栏目下有商品,栏目表category,商品表goods
select cat_id,cat_name from category where exists(select * from goods where goods.cat_id = category.cat_id);
4、子查询
1》in (子查询) 和not in (子查询)
in中的子查询允许返回的记录不只一条,而在where中只能是一条
如:
SELECT address from student where studentname in(select studentname from student where gradeid = 1);
子查询中返回的studentname不只一个
5、多表查询
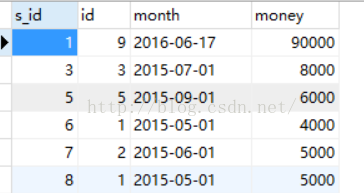
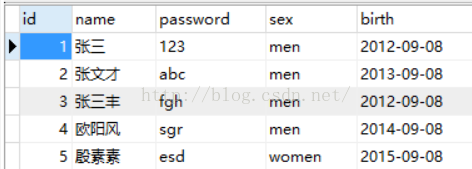
连接 4种连接
1、简单连接
select a.name ,b.chengji from student a,chengji as b where a.id=b.id;
select a.name ,b.chengji from student as a,chengji as b,表名 as 标签
where a.id=b.id and b.id = 标签的id;
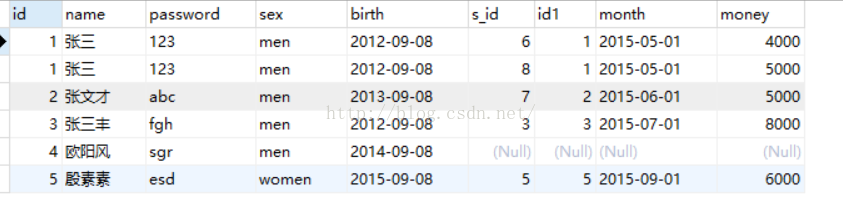
2.左连接 left join XXX on
语法:
selet 字段(表1,表2) from 表1(在左边,基表) left join 表2 on 表1.id=表2.id
多表查询
selet 字段(表1,表2) from 表1(在左边,基表)
left join 表2 on 表1.id=表2.id
left join 表3 on 表1.id = 表3.id
如:
SELECT us.*,sa.* from users as us left join salary as sa on sa.id = us.id;
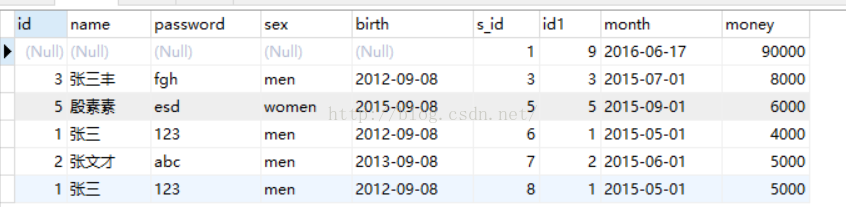
3、右连接 right join XXX on
selet 字段(表1,表2) from 表1(在右边,基表) right join 表2 on 表1.id=表2.id
SELECT us.*,sa.* from users as us right join salary as sa on us.id = sa.id;
4、交叉查询 cross join
select 字段(表1,表2) from 表1 cross join 表2
5、内连接 inner join 也称自身连接
格式:
select 字段列表 from 表1 inner join 表2 on 表1.字段=表2.字段inner join on
6、自然连接 natural join
不用连接条件,若两个表中的多个字段名称和类型都相同,那他们会作为自然连接的条件
SELECT us.*,sa.* from users as us NATURAL join salary as sa;
7、全连接 full join
注意:内连接 、交叉连接、全连接 以及join是等价的,输出的都是笛卡尔积














 4956
4956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









