







1 三种网页抓取方法
1.1 正则表达式
通过分析网页可以看到多个国家的属性都使用了<td class="w2p_fw">标签,例如国家面积属性的位置:
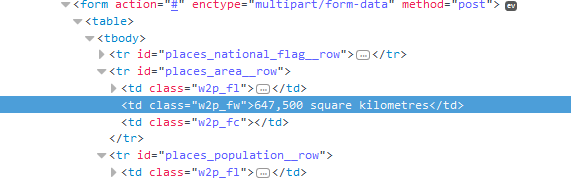
这样就可以通过正则表达式进行数据的抓取:
# -*- coding: utf-8 -*-
import urllib2
import re
def scrape(html):
area = re.findall('<tr id="places_area__row"><td class="w2p_fl"><label class="readonly" for="places_area" id="places_area__label">Area: </label></td><td class="w2p_fw">(.*?)</td><td class="w2p_fc"></td></tr>', html)[0]
return area
if __name__ == '__main__':
html = urllib2.urlopen('http://example.webscraping.com/places/default/view/Afghanistan-1').read()
print scrape(html)1.2 Beautiful Soup
首先安装beautifulsoup4
pip install beautifulsoup4
使用beautifulsoup的第一步就是将已经下载的HTML内容解析为soup文档。此外beautifulsoup还具有修补引号缺失和标签未闭合的问题。
from bs4 import BeautifulSoup
broken_html='<ul class=country><li>Area<li>Population</ul>'
soup=BeautifulSoup(broken_html,'html.parser')
fixed_html=soup.prettify()
print fixed_html
ul=soup.find('ul',attrs={'class':'country'})
li=ul.find('li')
print li.text
print ul.find_all('li')
print soup.li.li.string输出结果为:
<ul class="country">
<li>
Area
<li>
Population
</li>
</li>
</ul>
AreaPopulation
[<li>Area<li>Population</li></li>, <li>Population</li>]
Population
1.3 Lxml
lxml同样具有修补网页标签的能力
import lxml.html
broken_html='<ul class=country><li>Area<li>Population</ul>'
tree=lxml.html.fromstring(broken_html)
fixed_html=lxml.html.tostring(tree, pretty_print=True)
print fixed_html<ul class="country">
<li>Area</li>
<li>Population</li>
</ul>
关于CSS选择器
CSS选择器表示选择元素所使用的模式。常用示例如下:

使用lxml的CSS选择器抽取面积数据的示例代码:
# -*- coding: utf-8 -*-
import urllib2
import lxml.html
def scrape(html):
tree = lxml.html.fromstring(html)
td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0]
area = td.text_content()
return area
if __name__ == '__main__':
html = urllib2.urlopen('http://example.webscraping.com/places/default/view/Afghanistan-1').read()
print scrape(html)1.4 性能对比
下面的代码是分别使用上述三种方式来抓取国家页面的所有属性信息,不仅仅包括国家的面积。同时又对三种方法进行了性能测试(每一种方式运行1000次)。代码如下:
import re
from bs4 import BeautifulSoup
import lxml.html
import urllib2
import time
from test.test_sax import start
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def re_scraper(html):
results={}
for field in FIELDS:
results[field]=re.search('<tr id="places_%s__row">.*?<td class="w2p_fw">(.*?)</td>' % field, html).groups()[0]
return results
def bs_scraper(html):
soup=BeautifulSoup(html,'html.parser')
results={}
for field in FIELDS:
results[field]=soup.find('table').find('tr',id='places_%s__row' % field).find('td',class_='w2p_fw').text
return results
def lxml_scraper(html):
tree=lxml.html.fromstring(html)
results={}
for field in FIELDS:
results[field]=tree.cssselect('table > tr#places_%s__row > td.w2p_fw' % field)[0].text_content()
return results
def main():
NUM_ITERATIONS=1000
for name,scraper in [('Regular expressions',re_scraper),('BeatifulSoup',bs_scraper),('Lxml',lxml_scraper)]:
start=time.time()
for i in range(NUM_ITERATIONS):
if scraper==re_scraper:
re.purge()#默认情况下正则表达式模块会缓存搜索结果,这里是为了清除缓存。
result=scraper(html)
assert(result['area']=='647,500 square kilometres')
end=time.time()
print '%s: %.2f seconds' %(name,end-start)
if __name__ == '__main__':
html = urllib2.urlopen('http://example.webscraping.com/places/default/view/Afghanistan-1').read()
print re_scraper(html)
print bs_scraper(html)
print lxml_scraper(html)
main(){'languages': 'fa-AF,ps,uz-AF,tk', 'area': '647,500 square kilometres', 'country': 'Afghanistan', 'postal_code_regex': '', 'tld': '.af', 'currency_name': 'Afghani', 'phone': '93', 'neighbours': '<div><a href="/places/default/iso/TM">TM </a><a href="/places/default/iso/CN">CN </a><a href="/places/default/iso/IR">IR </a><a href="/places/default/iso/TJ">TJ </a><a href="/places/default/iso/PK">PK </a><a href="/places/default/iso/UZ">UZ </a></div>', 'iso': 'AF', 'postal_code_format': '', 'capital': 'Kabul', 'continent': '<a href="/places/default/continent/AS">AS</a>', 'currency_code': 'AFN', 'population': '29,121,286'}
{'languages': u'fa-AF,ps,uz-AF,tk', 'area': u'647,500 square kilometres', 'country': u'Afghanistan', 'postal_code_regex': u'', 'tld': u'.af', 'currency_name': u'Afghani', 'phone': u'93', 'neighbours': u'TM CN IR TJ PK UZ ', 'iso': u'AF', 'postal_code_format': u'', 'capital': u'Kabul', 'continent': u'AS', 'currency_code': u'AFN', 'population': u'29,121,286'}
{'languages': 'fa-AF,ps,uz-AF,tk', 'area': '647,500 square kilometres', 'country': 'Afghanistan', 'postal_code_regex': '', 'tld': '.af', 'currency_name': 'Afghani', 'phone': '93', 'neighbours': 'TM CN IR TJ PK UZ ', 'iso': 'AF', 'postal_code_format': '', 'capital': 'Kabul', 'continent': 'AS', 'currency_code': 'AFN', 'population': '29,121,286'}
Regular expressions: 3.19 seconds
BeatifulSoup: 25.63 seconds
Lxml: 4.19 seconds

1.5 为链接爬虫添加抓取回调
callback是一个函数,在发生某个特定事件之后会调用该函数(在本例中,会在网页下载完成后调用)。回调函数scrape_callback2代码如下:
# -*- coding: utf-8 -*-
import csv
import re
import urlparse
import lxml.html
from link_crawler import link_crawler
class ScrapeCallback:
def __init__(self):
self.writer = csv.writer(open('countries.csv', 'wb'))
self.fields = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
self.writer.writerow(self.fields)
def __call__(self, url, html):
if re.search('/view/', url):
tree = lxml.html.fromstring(html)
row = []
for field in self.fields:
row.append(tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content())
self.writer.writerow(row)
if __name__ == '__main__':
link_crawler('http://example.webscraping.com/', '/places/default/view/.*?-\d', scrape_callback=ScrapeCallback())# -*- conding:utf-f -*-
import re
import urlparse
import urllib2
import time
from datetime import datetime
import robotparser
import Queue
def link_crawler(seed_url, link_regex=None, delay=5, max_depth=-1, max_urls=-1, headers=None, user_agent='wswp', proxy=None, num_retries=1, scrape_callback=None):
"""Crawl from the given seed URL following links matched by link_regex
"""
# the queue of URL's that still need to be crawled
crawl_queue = [seed_url]
# the URL's that have been seen and at what depth
seen = {seed_url: 0}
# track how many URL's have been downloaded
num_urls = 0
rp = get_robots(seed_url)
throttle = Throttle(delay)
headers = headers or {}
if user_agent:
headers['User-agent'] = user_agent
while crawl_queue:
url = crawl_queue.pop()
depth = seen[url]
# check url passes robots.txt restrictions
if rp.can_fetch(user_agent, url):
throttle.wait(url)
html = download(url, headers, proxy=proxy, num_retries=num_retries)
links = []
if scrape_callback:#执行下载之后进行回调函数的调用。
links.extend(scrape_callback(url, html) or [])
if depth != max_depth:
# can still crawl further
if link_regex:
# filter for links matching our regular expression
links.extend(link for link in get_links(html) if re.match(link_regex, link))
for link in links:
link = normalize(seed_url, link)
# check whether already crawled this link
if link not in seen:
seen[link] = depth + 1
# check link is within same domain
if same_domain(seed_url, link):
# success! add this new link to queue
crawl_queue.append(link)
# check whether have reached downloaded maximum
num_urls += 1
if num_urls == max_urls:
break
else:
print 'Blocked by robots.txt:', url
class Throttle:
"""Throttle downloading by sleeping between requests to same domain
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
"""Delay if have accessed this domain recently
"""
domain = urlparse.urlsplit(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
def download(url, headers, proxy, num_retries, data=None):
print 'Downloading:', url
request = urllib2.Request(url, data, headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
response = opener.open(request)
html = response.read()
code = response.code
except urllib2.URLError as e:
print 'Download error:', e.reason
html = ''
if hasattr(e, 'code'):
code = e.code
if num_retries > 0 and 500 <= code < 600:
# retry 5XX HTTP errors
html = download(url, headers, proxy, num_retries-1, data)
else:
code = None
return html
def normalize(seed_url, link):
"""Normalize this URL by removing hash and adding domain
"""
link, _ = urlparse.urldefrag(link) # remove hash to avoid duplicates
return urlparse.urljoin(seed_url, link)
def same_domain(url1, url2):
"""Return True if both URL's belong to same domain
"""
return urlparse.urlparse(url1).netloc == urlparse.urlparse(url2).netloc
def get_robots(url):
"""Initialize robots parser for this domain
"""
rp = robotparser.RobotFileParser()
rp.set_url(urlparse.urljoin(url, '/robots.txt'))
rp.read()
return rp
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile('<a href="(.*?)">', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
if __name__ == '__main__':
link_crawler('http://example.webscraping.com', '/places/default/view/.*?-\d|/places/default/index', delay=0, num_retries=1, user_agent='BadCrawler')
link_crawler('http://example.webscraping.com', '/places/default/view/.*?-\d|/places/default/index', delay=0, num_retries=1, max_depth=1, user_agent='GoodCrawler')













 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









