







本文转载自:http://shujuren.org/article/351.html
作者:悟乙己
概述:作为经统专业看到预测的packages很眼馋。除了之前的forecast包,现在这个prophet功能也很强大。而且! 适合工业界+商业场景的应用。并不喜欢理论分析,能直接上案例的,一般不码字,力求简单粗暴!!
同时,本篇内容会同步更新于个人BLOG:http://blog.csdn.net/sinat_26917383/article/details/57419862
官网网址:https://facebookincubator.github.io/prophet/
github网址:https://github.com/facebookincubator/prophet
论文:《Forecasting at Scale // Sean J.Taylor and Benjamin Letham》
案例数据下载:http://download.csdn.net/detail/sinat_26917383/9764537
那么试玩下来觉得比较赞的功能点:
- 1、大规模、细粒度数据。其实并不是大量数据,而是时间粒度可以很小,在学校玩的计量大多都是“年/月”粒度,而这个包可以适应“日/时”级别的,具体的见后面的案例就知道了。不过,预测速度嘛~
可以定义为:较慢!!! - 2、趋势预测+趋势分解,最亮眼模块哟~~
拟合的有两种趋势:线性趋势、logistic趋势;趋势分解有很多种:Trend趋势、星期、年度、季节、节假日,同时也可以看到节中、节后效应。 - 3、突变点识别+调整。多种对抗突变办法以及调节方式。
- 4、异常值/离群值检测。时间维度的异常值检测。突变点和异常点既相似、又不同。
- 5、处理缺失值数据。这里指的是你可能有一些时间片段数据的缺失,之前的做法是先插值,然后进行预测(一些模型不允许断点),这里可以兼顾缺失值,同时也达到预测的目的。可以处理缺失值数据,这点很棒。
prophet应该就是我一直在找的,目前看到最好的营销活动分析的预测工具,是网站分析、广告活动分析的福音,如果您看到本篇文章内的方法,您在使用中发现什么心得,还请您尽量分享出来~
# install.packages('prophet')library(prophet)library(dplyr)
一、趋势预测+趋势分解
1、案例一:线性趋势+趋势分解
- 数据生成+建模阶段
history <- data.frame(ds = seq(as.Date('2015-01-01'), as.Date('2016-01-01'), by = 'd'),y = sin(1:366/200) + rnorm(366)/10)m <- prophet(history,growth = "linear")
其中,生成数据的时候注意,最好用ds(时间项)、y(一定要numeric)这两个命名你的变量,本案例是单序列+时间项。数据长这样:
prophet是生成模型阶段,m中有很多参数,有待后来人慢慢研究。
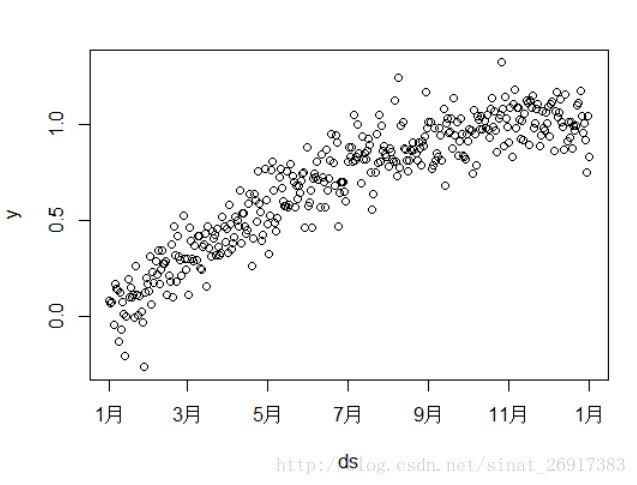
- 预测阶段
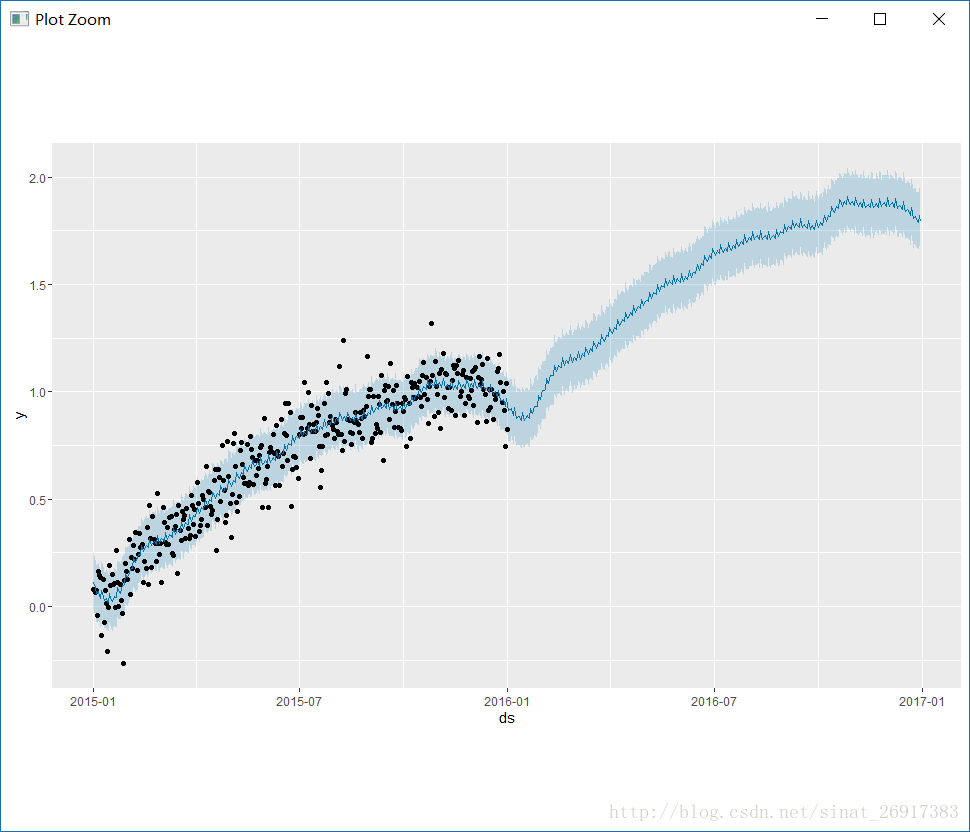
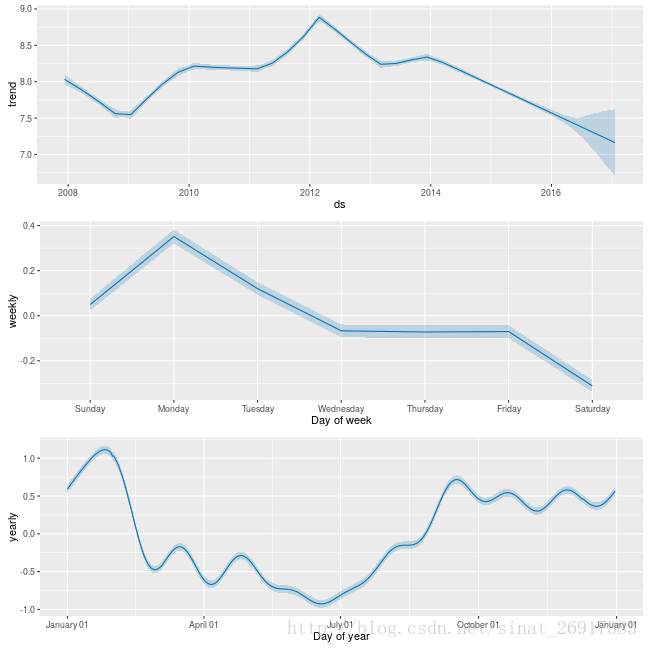
#时间函数future <- make_future_dataframe(m, periods = 365)tail(future)#预测forecast <- predict(m, future)tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')])#直线预测plot(m, forecast)#趋势分解prophet_plot_components(m, forecast)
make_future_dataframe:有趣的时间生成函数,之前的ds数据是2015-1-1到2016-1-1,现在生成了一个2015-1-1到2016-12-30序列,多增加了一年,以备预测。而且可以灵活的调控是预测天,还是周,freq参数。
predict,预测那么ds是时间,yhat是预测值,lower和upper是置信区间。
感受一下plot:
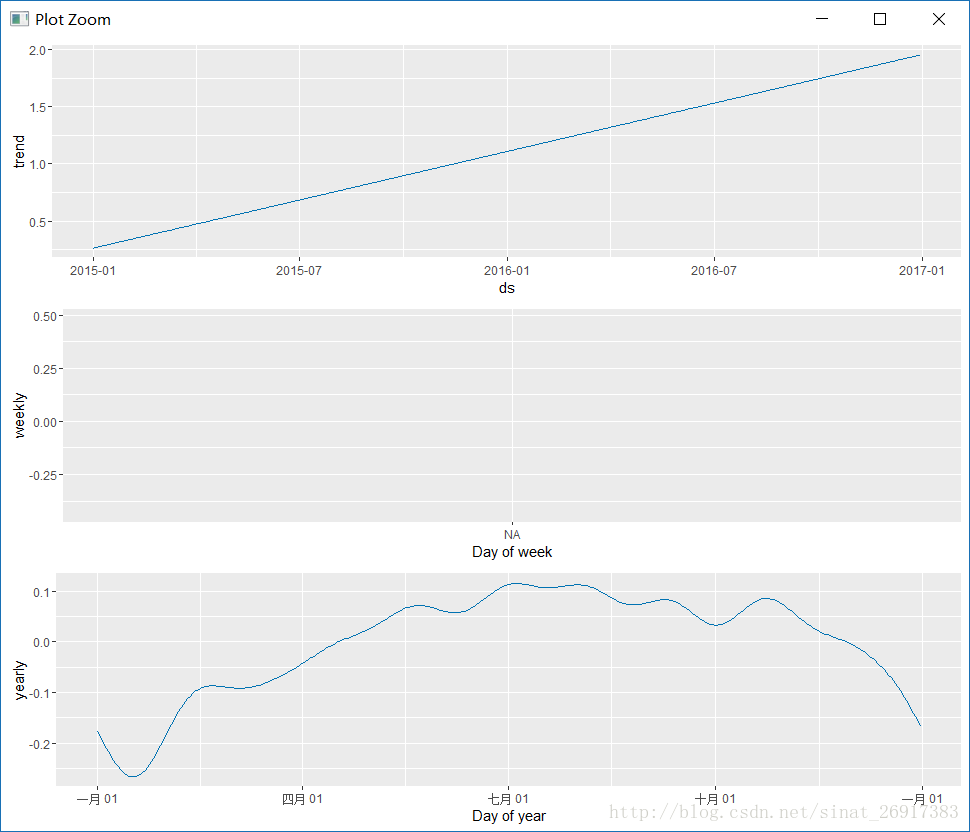
prophet_plot_components函数是趋势分解函数,将趋势分成了趋势项、星期、年份,这是默认配置。
2、案例二:logitics趋势+趋势分解
logitics是啥? 不懂烦请百度。
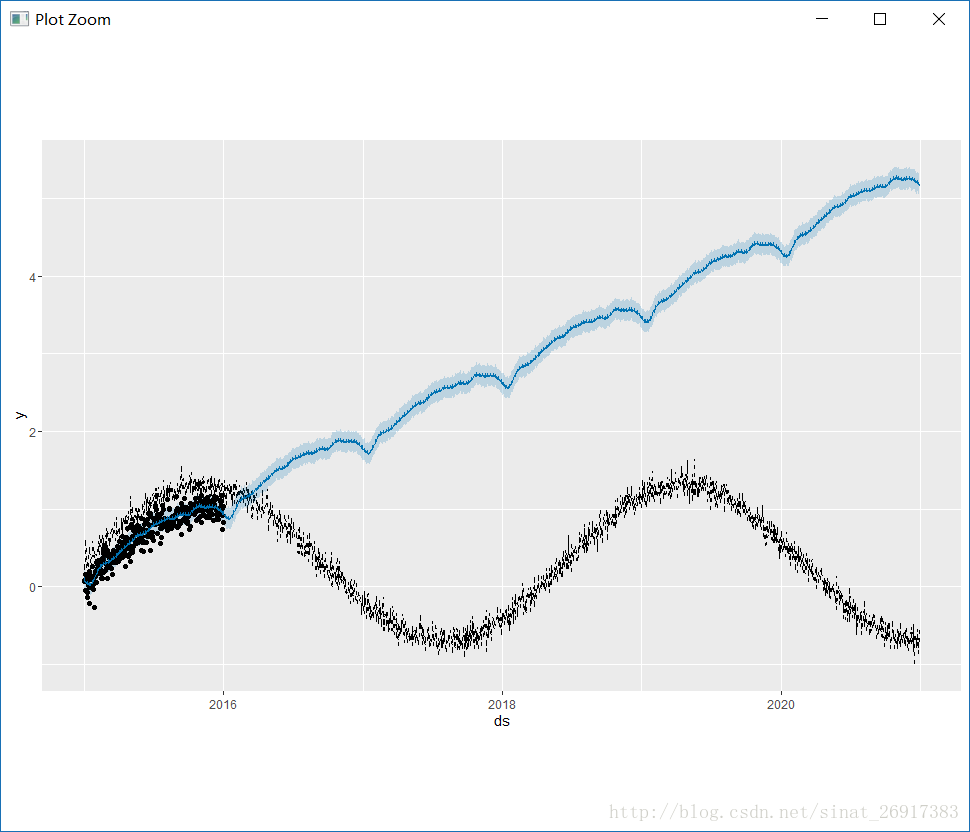
#数据生成阶段history <- data.frame(ds = seq(as.Date('2015-01-01'), as.Date('2016-01-01'), by = 'd'),y = sin(1:366/200) + rnorm(366)/10,cap=sin(1:366/200) + rnorm(366)/10+rep(0.3,366))#最大增长趋势,cap设置cap,就是这个规模的顶点,y当时顶点#模型生成m <- prophet(history,growth = "logistic")future <- make_future_dataframe(m, periods = 1826)future$cap <- sin(1:2191/200) + rnorm(2191)/10+rep(0.3,2191)#预测阶段fcst <- predict(m, future)plot(m, fcst)
prophet这里如果是要拟合logitics趋势,就需要一个cap变量,这个变量是y变量的上限(譬如最大市场规模),因为y如果服从logitics趋势不给范围的话,很容易一下预测就到顶点了,所以cap来让预测变得不那么“脆弱”…
下面来看一个失败拟合logitics案例:
二、节假日效应
可以考察节中、节后效应。
1、节中效应
#数据生成:常规数据history <- data.frame(ds = seq(as.Date('2015-01-01'), as.Date('2016-01-01'), by = 'd'),y = sin(1:366/200) + rnorm(366)/10,cap=sin(1:366/200) + rnorm(366)/10+rep(0.3,366))#数据生成:节假日数据library(dplyr)playoffs <- data_frame(holiday = 'playoff',ds = as.Date(c('2008-01-13', '2009-01-03', '2010-01-16','2010-01-24', '2010-02-07', '2011-01-08','2013-01-12', '2014-01-12', '2014-01-19','2014-02-02', '2015-01-11', '2016-01-17','2016-01-24', '2016-02-07')),lower_window = 0,upper_window = 1)superbowls <- data_frame(holiday = 'superbowl',ds = as.Date(c('2010-02-07', '2014-02-02', '2016-02-07')),lower_window = 0,upper_window = 1)holidays <- bind_rows(playoffs, superbowls)#预测m <- prophet(history, holidays = holidays)forecast <- predict(m, future)#影响效应forecast %>%select(ds, playoff, superbowl) %>%filter(abs(playoff + superbowl) > 0) %>%tail(10)#趋势组件prophet_plot_components(m, forecast);
数据生成环节有两个数据集要生成,一批数据是常规的数据(譬如流量),还有一个是节假日的时间数据
其中lower_window,upper_window 可以理解为假日延长时限,国庆和元旦肯定休息时间不一致,设置地很人性化,譬如圣诞节的平安夜+圣诞节两天,那么就要设置(lower_window = -1, upper_window = 1)。数据长这样:
holiday ds lower_window upper_window<chr> <date> <dbl> <dbl>1 playoff 2008-01-13 0 12 playoff 2009-01-03 0 13 playoff 2010-01-16 0 14 playoff 2010-01-24 0 15 playoff 2010-02-07 0 1
预测阶段,记得要开启prophet(history, holidays = holidays)中的holidays。现在可以来看看节假日效应:
ds playoff superbowl1 2015-01-11 0.012300004 02 2015-01-12 -0.008805914 03 2016-01-17 0.012300004 04 2016-01-18 -0.008805914 05 2016-01-24 0.012300004 06 2016-01-25 -0.008805914 07 2016-02-07 0.012300004 08 2016-02-08 -0.008805914 0
从数据来看,可以看到有一个日期是重叠的,超级碗+季后赛在同一天,那么这样就会出现节日效应累加的情况。
可以看到季后赛当日的影响比较明显,超级碗当日基本没啥影响,当然了,这些数据都是我瞎编的,要是有效应就见xxx。
趋势分解这里,除了趋势项、星期、年份,多了一个节假日影响,看到了吗?
.
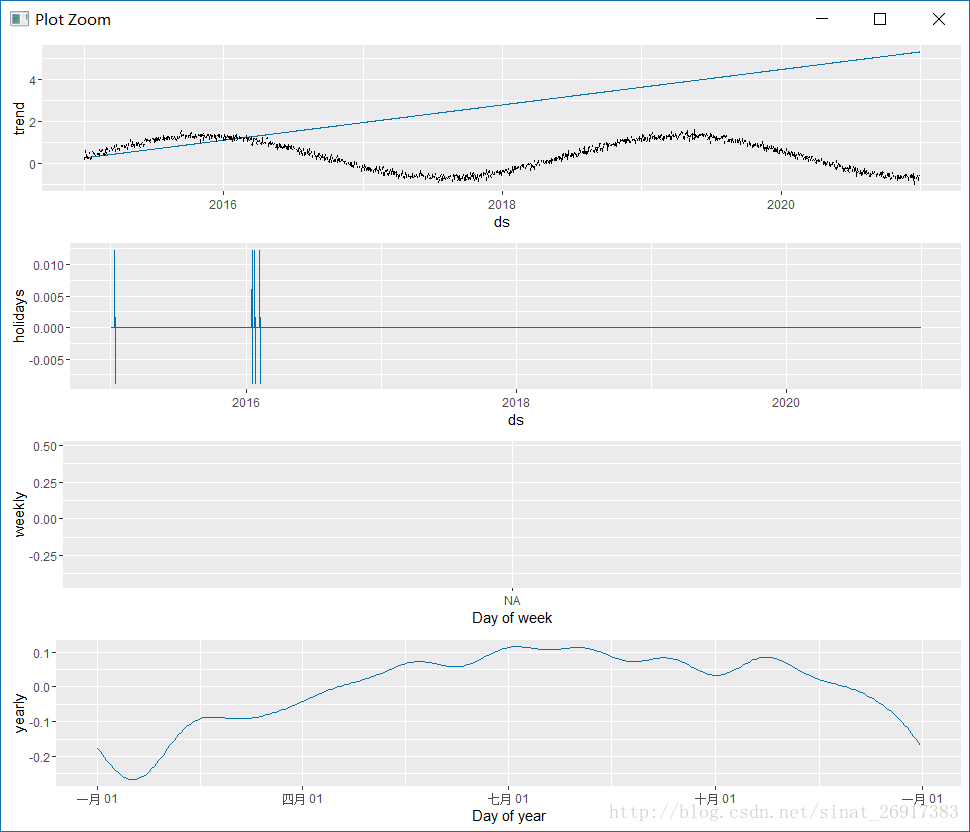
2、调和节前效应(Prior scale for holidays and seasonality)
一些情况下节假日会发生过拟合,那么可以使用holidays.prior.scale参数来进行调节,使其平滑过渡。(不知道翻译地对不对,本来刚开始以为是节后效应…)
#节后效应 holidays.prior.scalem <- prophet(history, holidays = holidays, holidays.prior.scale = 1)forecast <- predict(m, future)forecast %>%select(ds, playoff, superbowl) %>%filter(abs(playoff + superbowl) > 0) %>%tail(10)
主要通过holidays.prior.scale来实现,默认是10。由于笔者乱整数据,这里显示出效应,所以粘贴官网数据。官网的案例里面,通过调节,使得当晚超级碗的效应减弱,兼顾了节前的情况对当日的影响。
同时除了节前,还有季节前的效应,通过参数seasonality_prior_scale 调整
DS PLAYOFF SUPERBOWL2190 2014-02-02 1.362312 0.6934252191 2014-02-03 2.033471 0.5422542532 2015-01-11 1.362312 0.0000002533 2015-01-12 2.033471 0.0000002901 2016-01-17 1.362312 0.0000002902 2016-01-18 2.033471 0.0000002908 2016-01-24 1.362312 0.000000
三、突变点调节、间断点、异常点
本节之后主要就是玩案例里面的数据,案例数据如果R包中没有,可以从这里下载。
1、Prophet——自动突变点识别
时间序列里面的很可能存在突变点,譬如一些节假日的冲击。Prophet会自动检测这些突变点,并进行适当的调整,但是机器判断会出现:没有对突变点进行调整、突变点过度调整两种情况,如果真的突变点出现,也可以通过函数中的参数进行调节。
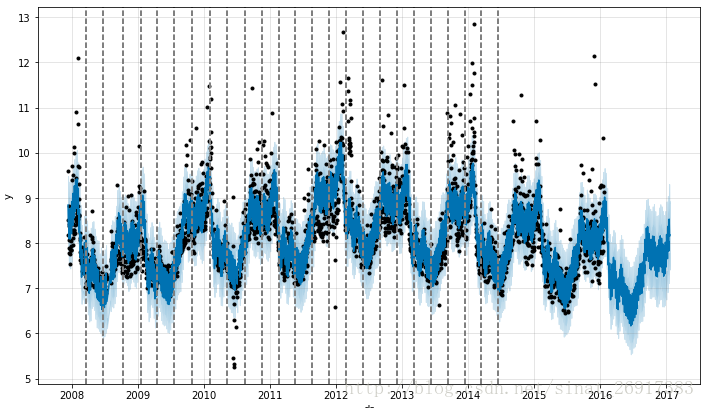
Prophet自己会检测一些突变点,以下的图就是Prophet自己检测出来的,虚纵向代表突变点。检测到了25个,那么Prophet的做法跟L1正则一样,“假装”/删掉看不见这些突变。
其自己检验突变点的方式,类似观察ARIMA的自相关/偏相关系数截尾、拖尾:
.
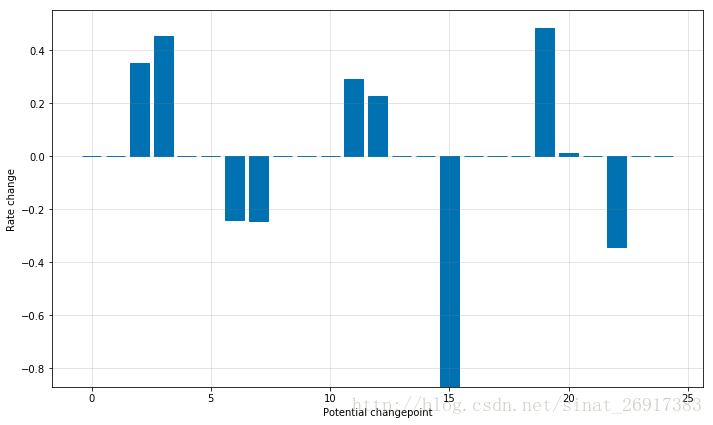
2、人为干预突变点——弹性范围
通过changepoint_prior_scale进行人为干预。
df = pd.read_csv('../examples/example_wp_peyton_manning.csv')m <- prophet(df, changepoint.prior.scale = 0.5)forecast <- predict(m, future)plot(m, forecast)
来感受一下changepoint.prior.scale=0.05和0.5的区别:
可以把changepoint.prior.scale看成一个弹性尺度,值越大,受异常值影响越大,那么波动越大,如0.5这样的。
3、人为干预突变点——某突变点
当你知道数据中,存在某一个确定的突变点,且知道时间。可以用changepoints 函数。不po图了。
df = pd.read_csv('../examples/example_wp_peyton_manning.csv')m <- prophet(df, changepoints = c(as.Date('2014-01-01')))forecast <- predict(m, future)plot(m, forecast)
4、突变预测
标题取了这么一个名字,也是够吓人的,哈哈~ 第三节的前3点都是如何消除突变点并进行预测。
但是! 现实是,突变点是真实存在,且有些是有意义的,譬如双11、双12这样的节日。不能去掉这些突变点,但是不去掉又会影响真实预测,这时候Prophet新奇的来了一招:序列生成模型中,多少受异常值些影响(类似前面的changepoint_prior_scale,但是这里是从生成模型阶段就给一个弹性值)。
这里从生成模型中可以进行三个角度的调节:
(1)调节趋势;
(2)季节性调节
- (1)趋势突变适应
df = pd.read_csv('../examples/example_wp_peyton_manning.csv')m <- prophet(df, interval.width = 0.95)forecast <- predict(m, future)
在prophet生成模型阶段,加入interval.width,就是代表生成模型时,整个序列趋势,还有5%受异常值影响。
- (2)季节性突变适应
对于生产厂家来说,季节性波动是肯定有的,那么又想保留季节性突变情况,又要预测。而且季节性适应又是一个比较麻烦的事情,prophet里面需要先进行全贝叶斯抽样,mcmc.samples参数,默认为0.
m <- prophet(df, mcmc.samples = 500)forecast <- predict(m, future)prophet_plot_components(m, forecast);
打开mcmc.samples按钮,会把MAP估计改变为MCMC采样,训练时间很长,可能是之前的10倍。最终结果,官网DAO图:
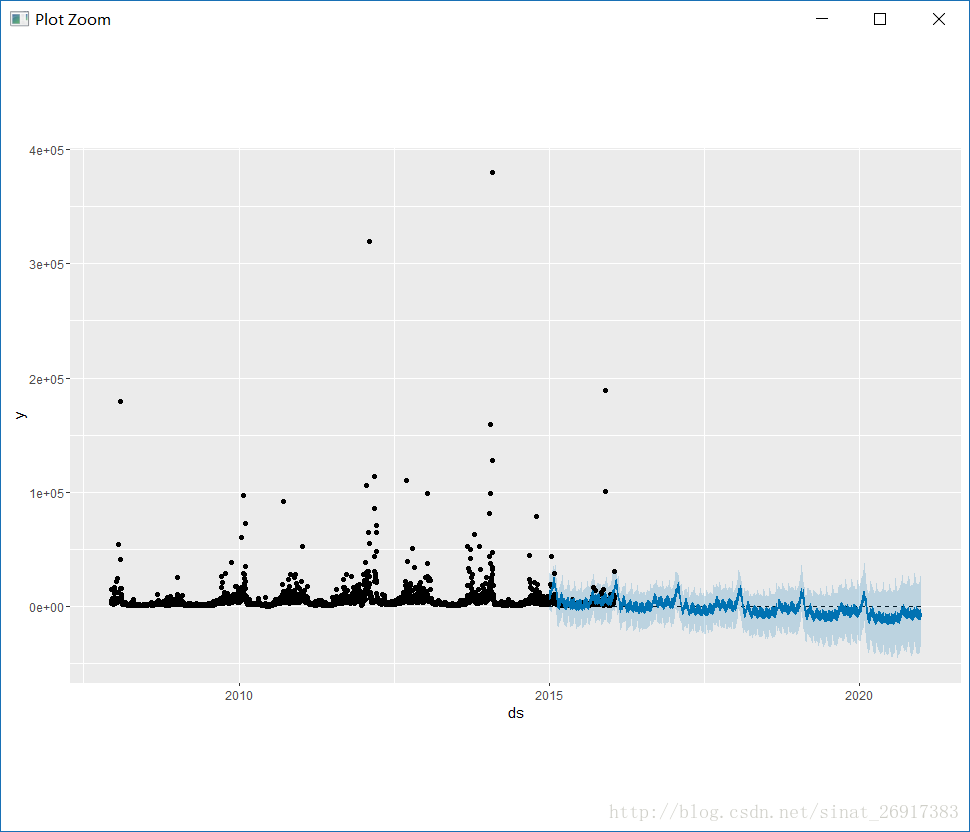
5、异常值/离群值
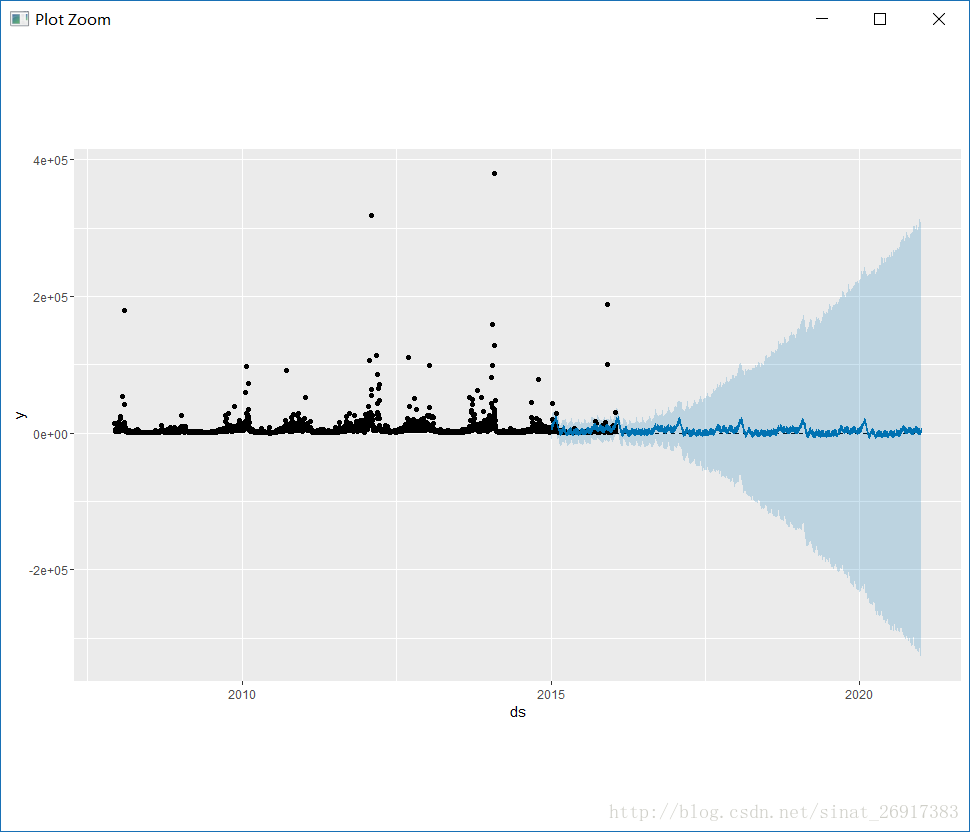
异常值与突变点是有区别的,离群值对预测影响尤其大。
df <- read.csv('../examples/example_wp_R_outliers1.csv')df$y <- log(df$y)m <- prophet(df)future <- make_future_dataframe(m, periods = 1096)forecast <- predict(m, future)plot(m, forecast);
对结果的影响很大,而且导致预测置信区间扩大多倍不止。prophet的优势体现出来了,prophet是可以接受空缺值NA的,所以这些异常点删掉或者NA掉,都是可以的。
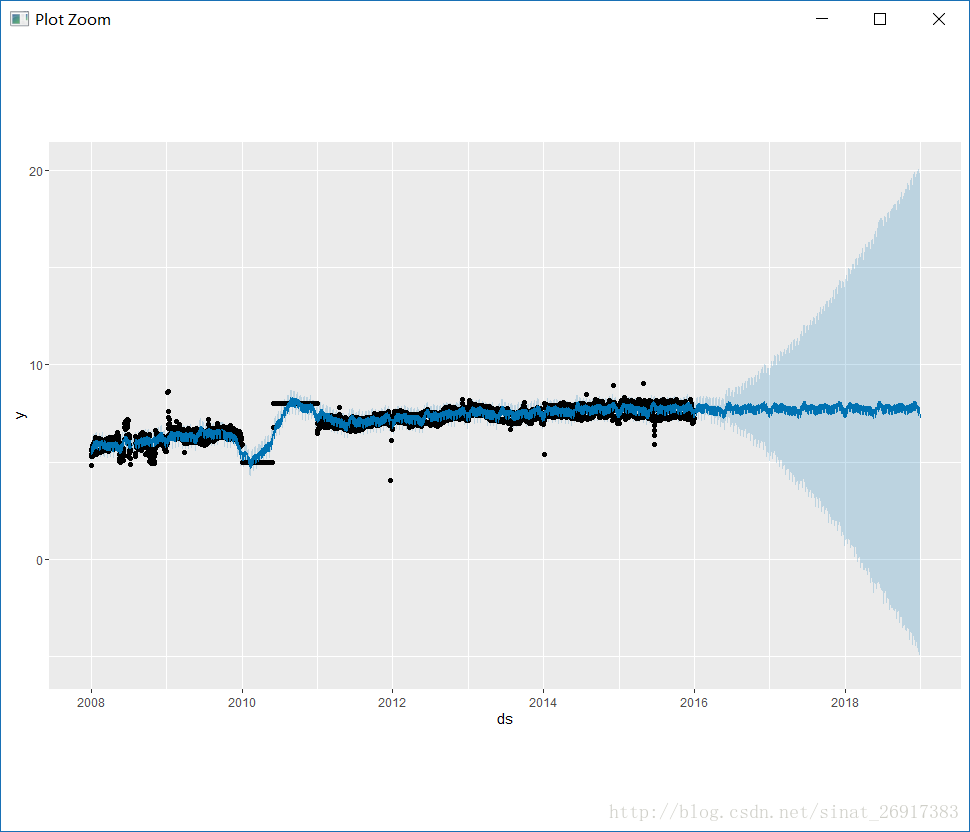
#异常点变为NA+进行预测outliers <- (as.Date(df$ds) > as.Date('2010-01-01')& as.Date(df$ds) < as.Date('2011-01-01'))df$y[outliers] = NAm <- prophet(df)forecast <- predict(m, future)plot(m, forecast);
当然啦,你也可以删掉整一段影响数据,特别是天灾人祸的影响是永久存在的,那么可以删掉这一整段。下图就是这样的情况,2015年6月份左右的一批数据,都是离群值。
四、缺失值、空缺时间的处理+预测
前面第三章后面就提过,prophet是可以处理缺失值。那么这里就可以实现这么一个操作,如果你的数据不完整,且是间断的,譬如你有一个月20天的数据,那么你也可以根据prophet预测,同时给予你每天的数据结果。实现了以下的功能:
prophet=缺失值预测+插值
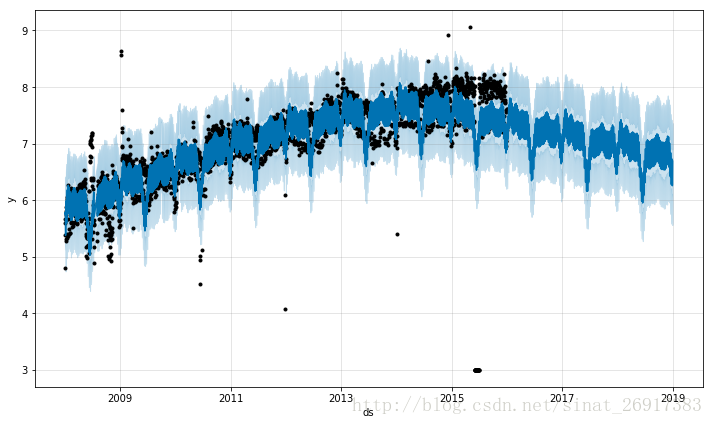
df <- read.csv('../examples/example_retail_sales.csv')m <- prophet(df)future <- make_future_dataframe(m, periods = 3652)fcst <- predict(m, future)plot(m, fcst);
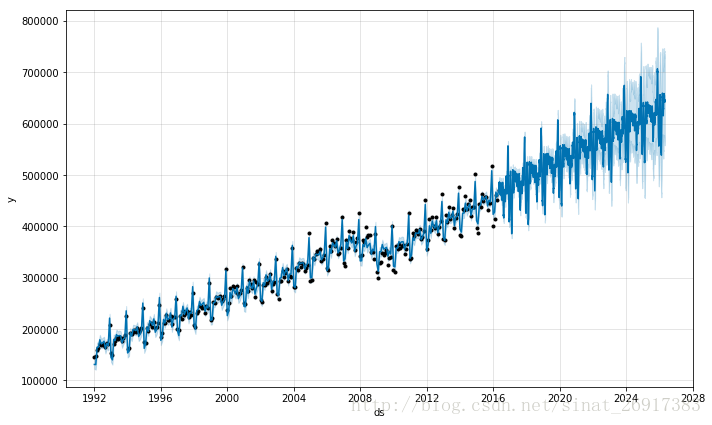
源数据长这样:
ds y1 1992-01-01 1463762 1992-02-01 1470793 1992-03-01 1593364 1992-04-01 1636695 1992-05-01 170068
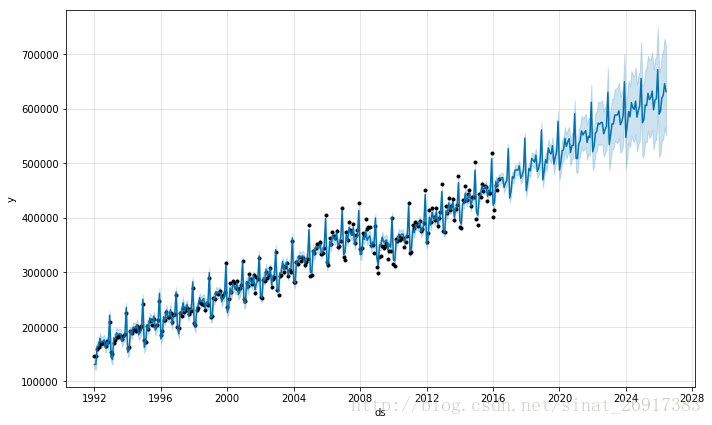
也就是你只有一年的每个月的数据,上面是预测接下来每一天的数据,也能预测,但是后面每天预测的误差有点大。所以你可以设置make_future_dataframe中的freq,后面预测的是每个月的:
future <- make_future_dataframe(m, periods = 120, freq = 'm')fcst <- predict(m, future)plot(m, fcst)
数据人网是数据人学习、交流和分享的平台http://shujuren.org 。专注于从数据中学习。
平台的理念:人人投稿,知识共享;人人分析,洞见驱动;智慧聚合,普惠人人。
您在数据人网平台,可以1)学习数据知识;2)创建数据博客;3)认识数据朋友;4)寻找数据工作;5)找到其它与数据相关的干货。
我们努力坚持做原创,分享和传播有价值的数据知识!
我们都是数据人,数据是有价值的,坚定不移地利用数据价值创造价值!
可以转载,严禁修改,请务必注明出自数据人网和原文链接
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









