









一开始自己经过了好长时间的思考,都没有完成这个问题的排序,在最终经过暗暗下定决心,终于完成了这道题目的求解,下面将我的分析思路写下来,希望我平实的语言可以帮助你理解这个题目。
对于五个元素a,b,c,d,e的排序,我们需要借鉴3个元素排序和四个元素中对于3个元素建立全序的思想,下面我们就来看看它们的思想吧!
1.对于三个元素a,b,c进行排序,示意图如下所示:
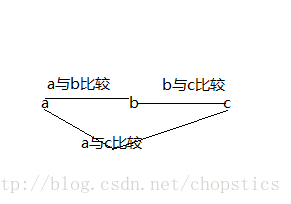
总共需要三次才可完成对a,b,c三个元素的排序。
2.对于四个元素a,b,c,d排序,我们可以对于其中任意三个元素建立全序关系,示意图如下所示:
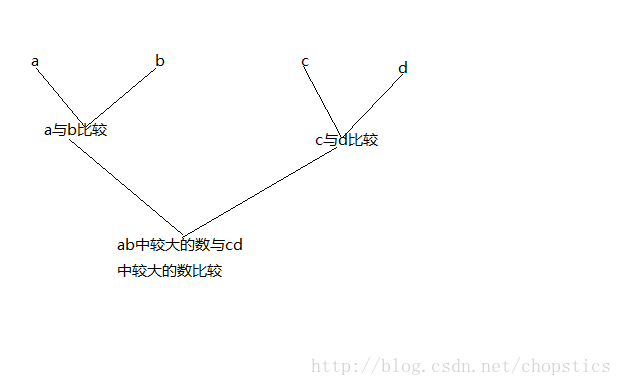
这样总共需要三次比较,我们就对其中的三个元素建立了全序关系。
例如:当ab比较一次较大的数为b,cd比较一次较大的数为d,那么b与d再比较一次(总共需要三次),当b>d时,我们得到三个元素c,d,b的全序关系为c<d<b,其他的结果与这个例子相似。反正总共需要3次比较即可。
3.当五个元素a,b,c,d,e进行排序时,我们已经知道其中三个元素的全序关系为c<d<b且a<b(2中已经说明),我们把e可以通过折半查找放入c,d,b的某个位置,如下所示:
__c__d__b__
e先和d比较,比较结果使得e要么在d的右边,要么在d的左边,当在d的右边时,在和b比较,在左边时,类似比较即可。这样通过折半查找总共需要比较2次即可。
例当e在d的右边时,我们得到这样的排序结果,要么是c<d<e<b,要么是c<d<b<e:
①当c<d<e<b时:由于a<b,所以只需要a同c,d,e比较即可,通过折半查找,需要2次比较即可。
②当c<d<b<e时:也是由于a<b,所以通过两次比较也可以得到五个元素的排序结果,也是需要两次。
综上所述:比较五个元素需要的次数总共为:3+2+2=7次就可以完成五个元素的排序了。














 5625
5625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









