







工作中同事提的一个问题:
有一张用户表,表里面三个字段,分别是用户ID,用户姓名,和用户薪水,表里面有100万条数据,如何用一句SQL查询出
薪水小于1000,薪水=1000,1000<薪水<5000,薪水=5000,薪水>5000的人。写出的SQL效率越高越好。
测试:
CREATE TABLE test (
id int(11) NOT NULL AUTO_INCREMENT,
money int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
插入100W条数据;进行写sql。
最开始打算使用最普通的方式写:
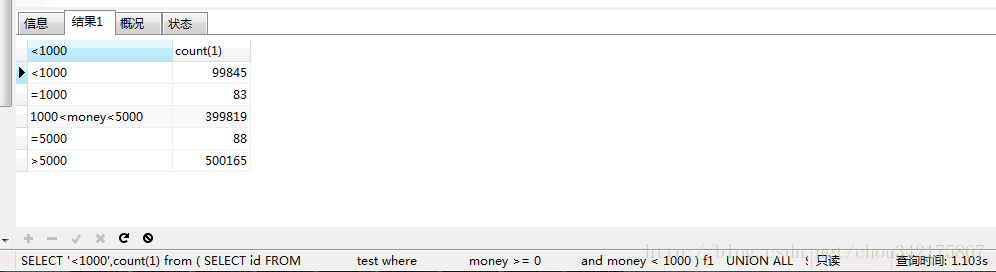
SELECT '<1000',count(1) from (
SELECT
id
FROM
test
where
money >= 0
and money < 1000
) f1
UNION ALL
SELECT '=1000',count(1) from (
SELECT
id
FROM
test where money=1000
) f2
UNION ALL
SELECT '1000<money<5000',count(1) from (
SELECT
id
FROM
test
where money>1000 and money < 5000
) f3
UNION ALL
SELECT '=5000',count(1) from (
SELECT
id
FROM
test
where money = 5000
) f4
UNION ALL
SELECT '>5000',count(1) from (
SELECT
id
FROM
test
where
money > 5000
) f5刚开始想到的方式。。。用了1.103s ,肯定是效率不达标的。
后面公司开发老大发出的sql:
SELECT
f,
COUNT(1)
FROM
(
SELECT
IF (
money < 1000,
1,
IF (
money = 1000,
2,
IF (
money < 5000,
3,
IF (money = 5000, 4, 5)
)
)
) AS f
FROM
test
) t
GROUP BY
f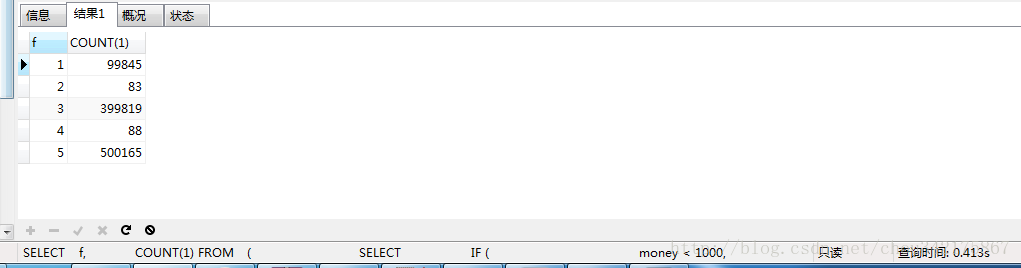
只用了0.413s,很厉害;
可以从sql中看出使用了if的语句,很大程度提高了效率。
sql的效果是对每一条都执行判断然后附上对应条件的值。
这样写应该好看懂一点点
SELECT
f,
COUNT(1)
from (
SELECT
IF (money < 1000, 1,
IF(money = 1000,2,
IF(money < 5000,3,
IF(money = 5000,4,5)
)
)
) f
FROM
test
) r GROUP BY fsql中的if语句是一层一层嵌套执行着的。














 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









