







数据库重构探讨系列
(1) 基础
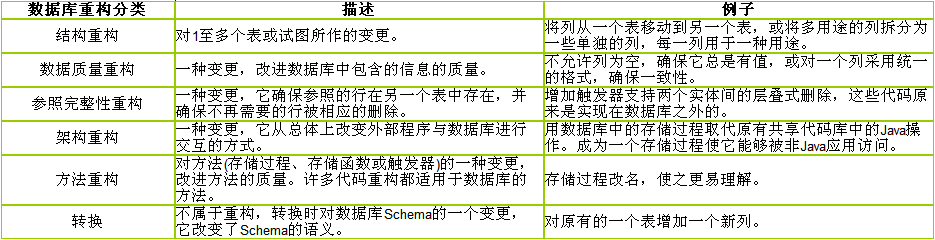
1、数据库重构分成6类:
2、数据库味道
与“代码味道”概念相似,代码味道是代码中出现常见问题,表明需要进行重构。
数据库味道表明数据库需要重构。这些味道包括:
(1) 多用途的列
如一个列被用于多种用途,就可能存在额外的代码来确保源数据以“正确的方式”使用,这些代码常常会检查一个列或更多其它列的值。
比如:
某列用于存储某人的生日,如果此人是顾客的话。假如此人是公司雇员,此列则用于存储入厂日期。
(2) 多用途的表
如一个表被用于存放几种类型的实体,就可能存在设计缺陷。
例如:
某个表Customer同时存放了人和公司的信息。
(3) 重复的数据
重复的数据对操作型数据库来说是一个严重的问题,因为如数据存放在几个地方,不一致的机会就增加了。
(4) 列太多的表
当一个表包含太多的列,则说明这个表缺乏内聚。
比如:
Customer表包含了一些列,存放了3种不同的地址(发货地址、账单地址、公司地址)或几个电话号码(家庭电话、工作电话、手机号等),你可能需要将这种结构进行标准化处理,加入Address和PhoneNumber表。
(5) “智能”列
“智能”列是这样一种列,其中数据的不同位置代表不同的概念。
例如:
客户ID的前4位数字代表客户的开户行,则客户ID就是一个“智能”列。因为你会解析它以取得更细粒度的信息,如开户行ID。
3、数据库重构
数据库重构是一种数据库实现技术,与代码重构相似,对数据库Schema进行重构,使得在上面增加东西变得容易。
上图提供了一些关键开发活动的高层视图,这些活动发生在涉及对象和关系数据库技术的现代项目中。需要在这些活动之间来回迭代。
数据库重构是演进式数据库开发的一个重要组成部分。还需要采用演进/敏捷的方式进行数据建模。
耦合越厉害,就越难重构。代码重构、数据库重构均是如此。
最简单的场景:单应用数据库。因为数据库Schema只与它本身和一个应用相耦合。
而在多应用的数据库架构中,你的数据库Schema可能与应用源码、持久框架、ORM工具、其它数据库(提供复制、数据抽取/加载等)、数据文件Schema、测试代码,甚至数据库自身等耦合在一起。
减少涉及数据库的耦合的一种有效方式是封装对数据库的访问。让外部程序通过持久层来访问数据库,可以实现对数据库访问的封装。
持久层有多种实现方式:
(1) 通过数据访问对象DAO,它实现了所需的SQL代码;
(2) 通过框架;
(3) 通过存储过程;
(4) 通过Web服务。
永远也不可能把耦合降到0,但肯定可以把它降到能管理的程度。














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









