







1.简述
分析(analysis),在lucene中指的是将域(Field)转换成最基本的索引表示单元——项(Term)的过程。项的值称为语汇单元(token)。
对于英文来说,这个过程历经了提取单词、去除标点、字母转小写、去除停用词、词干还原等。
对应关系见图1-1.
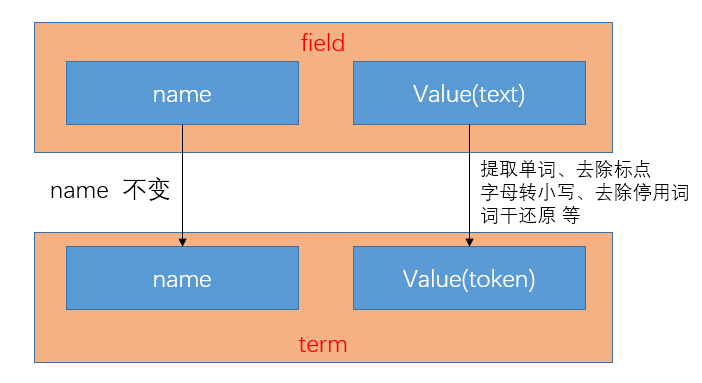
图1-1 field与term的对应关系图示
2.Analyzer
org.apache.lucene.analysis.
Analyzer
抽象类。
lucene内置有WhitespaceAnalyzer、SimpleAnalyzer、StopAnalyzer与StandardAnalyzer等分析器。
2.1 StandardAnalyzer简介
org.apache.lucene.analysis.standard.
StandardAnalyzer
这是lucene最复杂的核心分析器。它包含大量的逻辑操作来识别某些种类的语汇单元(token),比如公司名称、email地址等。它的主要处理有:提取单词、去除标点、字母转小写、去除停用词。
StandardAnalyzer的createComponents()方法见下:
@Override
protected TokenStreamComponents createComponents(final String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(src);
tok = new LowerCaseFilter(tok);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) {
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}2.2 指定分析器
在创建IndexWriter时,会指定默认的分析器。也可以在addDocument()与updateDocument()的时候单独为某个文档指定特殊的分析器。
2.3 索引与查询两个阶段的分析器使用
QueryParser通过解析用户输入的lucene查询语法来生成Query对象,为用户带来了方便。
2.4 相关方法
org.apache.lucene.analysis.
Analyzer
抽象类。分析器,用于从域(field)中构建语汇单元(tokenstream)。
TokenStream org.apache.lucene.analysis.Analyzer. tokenStream(String fieldName, String text)
它会调用createComponents()方法获得 TokenStreamComponents实例,然后返回components.getTokenStream()结果。
TokenStream org.apache.lucene.analysis.Analyzer. tokenStream(String fieldName, Reader reader)
tokenStream()的重载方法。
抽象类。分析器,用于从域(field)中构建语汇单元(tokenstream)。
TokenStream org.apache.lucene.analysis.Analyzer. tokenStream(String fieldName, String text)
它会调用createComponents()方法获得 TokenStreamComponents实例,然后返回components.getTokenStream()结果。
TokenStream org.apache.lucene.analysis.Analyzer. tokenStream(String fieldName, Reader reader)
tokenStream()的重载方法。
TokenStreamComponents org.apache.lucene.analysis.Analyzer.
createComponents(String fieldName)
创建这个analyzer的component。内部会set reader,set tokenizer,set 若干个tokenfilter。
2.4.1 TokenStreamComponents
org.apache.lucene.analysis.Analyzer. TokenStreamComponents内部静态类。它封装了一个tokenstream的外部组件。它提供了对tokenizer的访问。
org.apache.lucene.analysis.Analyzer.TokenStreamComponents.
TokenStreamComponents(Tokenizer source, TokenStream result)
构造函数。
TokenStream org.apache.lucene.analysis.Analyzer.TokenStreamComponents. getTokenStream()
此方法被Analyzer.tokenStream()方法调用。
TokenStream org.apache.lucene.analysis.Analyzer.TokenStreamComponents. getTokenStream()
此方法被Analyzer.tokenStream()方法调用。
2.5 自定义Analyzer
继承Analyzer这个抽象类,重写createComponents方法即可。
TokenStreamComponents org.apache.lucene.analysis.Analyzer.
createComponents(String fieldName)
抽象方法,要求子类重写。
一个filter链中,不能随意调整tokenFilter的顺序。例如StopFilter对停用词是区分大小写的,那么将它置于LowerCaseFilter的前面与后面结果是不一样的。
在指定filter顺序时,还要考虑对程序性能的影响。例如我们要考虑这样一个分析器,它既能移除停用词,又能将同义词注入到语汇单元流中。此时,首先移除停用词效果会高一点,避免不必要的计算。
在指定filter顺序时,还要考虑对程序性能的影响。例如我们要考虑这样一个分析器,它既能移除停用词,又能将同义词注入到语汇单元流中。此时,首先移除停用词效果会高一点,避免不必要的计算。
2.6 测试Analyzer
在索引过程中,是看不到field在背后被怎样分析的,我们可以在测试方法中直接new Analyzer对象来测试文本的分析效果。
3.TokenStream
org.apache.lucene.analysis.
TokenStream
抽象类,具体的子类有Tokenizer与TokenFilter。
boolean org.apache.lucene.analysis.TokenStream. incrementToken()
移动游标,得到下一个token,如果tokenstream消费完了返回false。类似JDBC的ResultSet.hasNext()。
void org.apache.lucene.analysis.TokenStream. reset()
在开始调用incrementToken()方法前要先调用此方法。
抽象类,具体的子类有Tokenizer与TokenFilter。
boolean org.apache.lucene.analysis.TokenStream. incrementToken()
移动游标,得到下一个token,如果tokenstream消费完了返回false。类似JDBC的ResultSet.hasNext()。
void org.apache.lucene.analysis.TokenStream. reset()
在开始调用incrementToken()方法前要先调用此方法。
3.1 TokenNizer
org.apache.lucene.analysis.
Tokenizer
抽象类。TokenStream的子类,输入为reader对象。
void org.apache.lucene.analysis.Tokenizer.
setReader(Reader input)
设置Tokenizer的reader。
设置Tokenizer的reader。
3.2 TokenFilter
org.apache.lucene.analysis.
TokenFilter
抽象类,TokenStream的子类,输入为其他的tokenstream对象,可用于迭代链式过滤。常见的子类有LowerCaseFilter,StopFilter等。
org.apache.lucene.analysis.TokenFilter.
TokenFilter(TokenStream input)
构造函数,由子类通过super()方式调用,传入Tokenizer对象或tokenFilter对象。
org.apache.lucene.analysis.core.
LowerCaseFilter
将token中的字母转为小写。
org.apache.lucene.analysis.core. StopFilter
移除停用词。
将token中的字母转为小写。
org.apache.lucene.analysis.core. StopFilter
移除停用词。
org.apache.lucene.analysis.en.
PorterStemFilter
基于波特算法的词干过滤器。StandardAnalyzer没有用它,但我们自己可以方便地写一个Analyzer来用它。
3.3 TokenAttribute
TokenStream在得到token(语汇单元)的时候,并不会创建string来保存token,而是通过维护token在stream中的偏移位置来实现。
3.3.1 CharTermAttribute
org.apache.lucene.analysis.tokenattributes.
CharTermAttribute
接口。代表token的text属性。
org.apache.lucene.analysis.tokenattributes. CharTermAttributeImpl
CharTermAttribute接口的实现类。
String org.apache.lucene.analysis.tokenattributes.CharTermAttributeImpl. toString()
输出代表token的text。
接口。代表token的text属性。
org.apache.lucene.analysis.tokenattributes. CharTermAttributeImpl
CharTermAttribute接口的实现类。
String org.apache.lucene.analysis.tokenattributes.CharTermAttributeImpl. toString()
输出代表token的text。
3.3.2 OffsetAttribute
org.apache.lucene.analysis.tokenattributes.
OffsetAttribute
接口。描述一个token在stream中的偏移位置(起始字符与终止字符)。
接口。描述一个token在stream中的偏移位置(起始字符与终止字符)。














 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









