







首先推荐看 机器学习lecture note1 里面的逻辑回归的推导,和 逻辑回归介绍 的前两部分一起看
1. 理解什么是梯度上升法
求局部最大值
往梯度上升的方向走,+正的导数值,导数为2,+2,导数为1/2,+1/2,走过了导数为-1,+(-1)= -1,这样逼近最大值
但是,一下面的函数为例
f(x)=13x3−4x
需要注意的:
1. x0不能在 [2,+∞] 的区间,导数为正,会越跑越远
2. 自动调节步长alpha
3. 精度达到就停止迭代
def fun(x):
return 1/3*x**3-4*x
x0=-4.3
alpha=0.45
sigma=1e-4
for iter in range(10):
print("iter ",iter+1,"\tx0 %.6f"%x0,"\t alpha:",alpha)
pl.scatter([x0],[fun(x0)])
x1=x0+alpha*(x0**2-4)
while x1>=2:
alpha=alpha/2
x1=x0+alpha*(x0**2-4)
if abs(x1-x0)<sigma:
break;
x0=x1
print("final x0:",x0)
x=np.arange(-5,5,0.1)
y=fun(x)
pl.plot(x,y)
pl.show()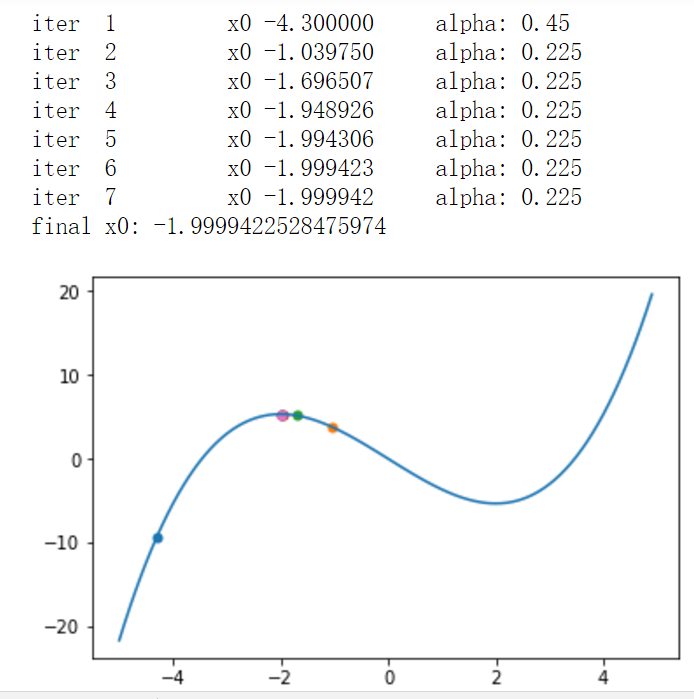
2.理解逻辑回归的目的
我们要找到weight使得用sigmoid函数能拟合数据
用最大似然法推导,然后用最大似然法求weight

3. 代码实现
机器学习实战第五章的代码
import numpy as np
def stocGradAscent1(dataset,labels,num_iter=150):
num_sample,num_feat=np.array(dataset).shape
weights=np.ones(num_feat)
randIndex=[]
for k in range(num_iter):
for i in range(num_sample):
alpha=4/(1+i+k)+0.0001
rand_i=int(np.random.uniform(0,num_sample))
while rand_i in randIndex:
rand_i=int(np.random.uniform(0,num_sample))
randIndex.append(rand_i)
h=sigmoid(sum(dataset[rand_i]*weights)) # w1*x1+w2*x2+w3*x3
error=labels[rand_i]-h
weights=weights+alpha*error*np.array(dataset[rand_i])
return weights
def classify(vector, weights):
vector=np.array(vector)
weights=np.array(weights)
prob=sigmoid(sum(vector*weights))
if prob>0.5:
return 1
else:
return 0
def loadTrainHorsetData():
f1=open("horseColicTraining.txt")
Dataset=[]
Labels=[]
for line in f1.readlines():
currline=line.strip().split("\t")
Dataset.append([float(i)for i in currline[:21]]) # 21个特征
Labels.append(float(currline[-1]))
return Dataset,Labels
def testHorse():
trainDataset,trainLabels=loadTrainHorsetData()
testDataset,testLabels=loadTestHorsetData()
weight=stocGradAscent1(trainDataset,trainLabels,100)
predic=classify(testDataset,weight)













 363
363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









