







目前正在通读《Linux内核设计与实现》一书,本文是对第六章<内核数据结构>的总结。
通用数据结构:链表、队列、映射、二叉树;是Linux内核常用的内建数据结构,书中反复强调要重用,不要再另行造轮子。
通用数据结构:链表、队列、映射、二叉树;是Linux内核常用的内建数据结构,书中反复强调要重用,不要再另行造轮子。
1.链表
Linux内核的标准链表是:环形双向链表;
在Linux中的实现是:将链表结构塞入数据结构。如
Linux内核的标准链表是:环形双向链表;
在Linux中的实现是:将链表结构塞入数据结构。如
struct fox{
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct list_head list;
}
其中,链表节点list_head的结构为:
struct list_head{
struct list_head *next;
struct list_head *prev;
}
内核提供了一系列链表操作例程。这些方法的统一特点是:它们只接受list_head结构为参数。不需要知道list_head所嵌入的父结构的具体数据结构。
然后通过宏container_of(),可以方便地从链表指针找到父结构中包含的任何变量。这是因为在C语言中,一个给定结构中的变量偏移在编译时地址就被ABI固定下来了。
然后通过宏container_of(),可以方便地从链表指针找到父结构中包含的任何变量。这是因为在C语言中,一个给定结构中的变量偏移在编译时地址就被ABI固定下来了。
2.队列
Linux内核通用队列实现为kfifo。
3.映射
一个映射,也常称为关联数组,其实是一个由唯一键组成的集合,而每个键必然关联一个特定的值。这种键到值的关联关系称为映射。
对应的是我们Java里的Map数据类型吗?
散列表(也叫哈希表)是一种映射,但是除了使用散列表外,映射也可以通过自平衡二叉搜索树存储数据。
Linux内核提供了简单、有效的非通用的映射。它的目标是:映射一个唯一的标识数(UID)到一个指针。这个映射被命名为idr。
4.树
Linux主要的平衡二叉树数据结构是红黑树。Linux实现的红黑树称为rbtree。
一个映射,也常称为关联数组,其实是一个由唯一键组成的集合,而每个键必然关联一个特定的值。这种键到值的关联关系称为映射。
对应的是我们Java里的Map数据类型吗?
散列表(也叫哈希表)是一种映射,但是除了使用散列表外,映射也可以通过自平衡二叉搜索树存储数据。
Linux内核提供了简单、有效的非通用的映射。它的目标是:映射一个唯一的标识数(UID)到一个指针。这个映射被命名为idr。
4.树
Linux主要的平衡二叉树数据结构是红黑树。Linux实现的红黑树称为rbtree。
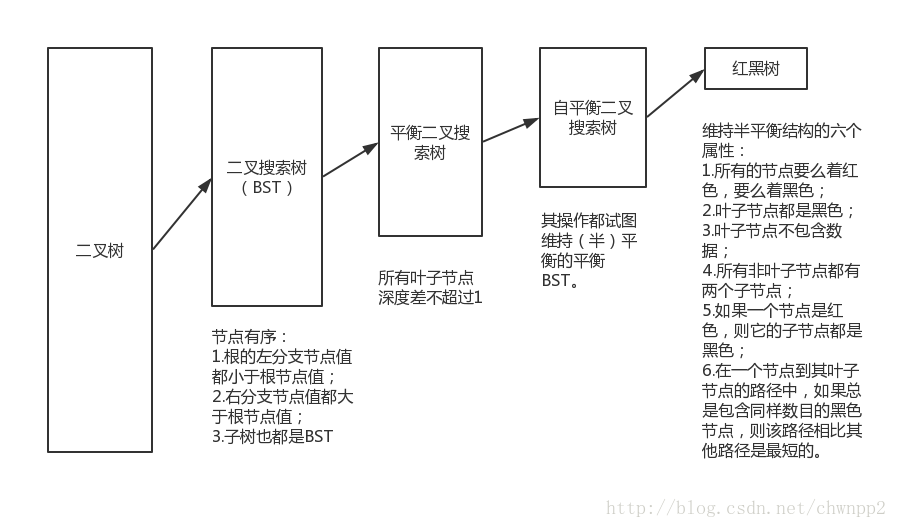
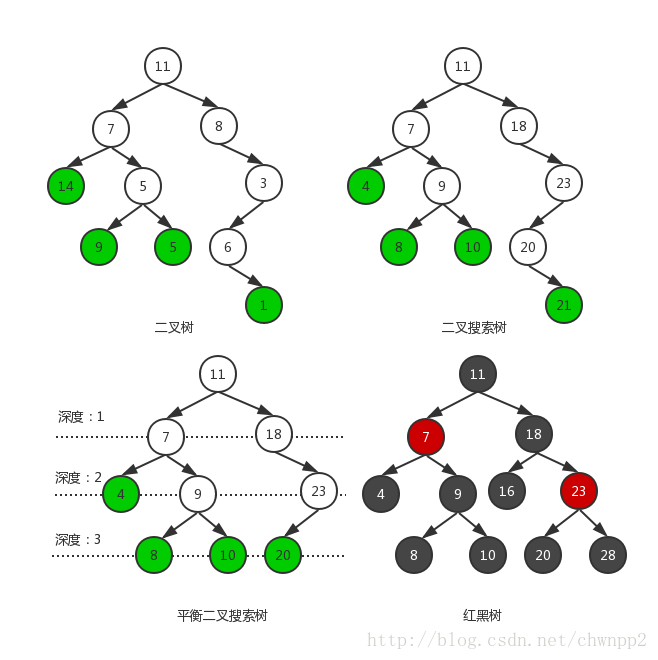
举例说明:
5.算法复杂度:
研究算法复杂度(或者伸缩度),常用的技术是:研究算法的渐进行为(asymptotic behavior)。渐进行为是指当算法的输入变得非常大或者接近于无限大时算法的行为。
Linux中操作链表的复杂度为恒定时间O(1),遍历链表的复杂度为线性关系O(n);
Linux中红黑树搜索的复杂度是对数关系logn,按序遍历的复杂度是线性关系O(n);
6.数据结构的选择:
链表:数据不定长,不要求连续内存,主要操作是遍历数据,数据项相对较少;
队列:符合生产者/消费者模式,特别是需要一个定长缓冲;
映射:映射工作
红黑树:存储大量数据、要求检索迅速、但是数据结构比较复杂
Linux中操作链表的复杂度为恒定时间O(1),遍历链表的复杂度为线性关系O(n);
Linux中红黑树搜索的复杂度是对数关系logn,按序遍历的复杂度是线性关系O(n);
6.数据结构的选择:
链表:数据不定长,不要求连续内存,主要操作是遍历数据,数据项相对较少;
队列:符合生产者/消费者模式,特别是需要一个定长缓冲;
映射:映射工作
红黑树:存储大量数据、要求检索迅速、但是数据结构比较复杂














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









