







3.2在多个GPU上训练
一个GTX 580 GPU只有3GB的内存,限制了能够在上面训练的网络的大小。实验证明120万训练样本已经足够用来训练网络,但是放在一个GPU上是不行的。因此论文将网络划分在了两个GPU上。现在的GPU非常适合跨GPU的并行,因为他们可以直接读写彼此的内存,而不用经过主机内存。这里采用的并行方式是将网络平均分配在两个GPU上,并使用了额外的技巧:GPU只在某些特定的层进行通信。看框架图,第三个卷积层的核(kernel)从第二层的所有核映射(kernel map)中取输入值,而第四层的核仅仅从位于同一GPU上的第3层的核映射中取输入值。选择连接模式对于调整通信量是非常重要的。
3.3 Local Response Normalization(这个我没看懂,就不在这献丑了)
3.4 重叠pooling
这个建议大家参考一下SC231n上的这篇文章,这里关于池化讲得比较详细。http://cs231n.github.io/convolutional-networks/#case
3.5 整体结构
就像前面描述的一样,网络包含8层,5层卷积层,剩下的3层是全链接层,最后一个全连接层的输出被送进了一个1000-way的softmax层,其产生一个覆盖1000类标签的分布。该网络最大化多分类logistic回归的目标函数。
(这里补充一点:softmax分类和多个Logistic分类是不同的,softmax分类用于类标签互不相交的情况,而多分类的logistic的类标签是可以重叠的。比如说对于单物体的图像分类来说,一张图像要么是狗,要么是猫,不可能既是狗又是猫(四不像,哈哈),这时使用softmax分类更为合适。而对于歌曲的分类来说,一首歌可能既属于古风,又可能属于90后,因此,使用多分类的logistic更为合适。所以我对文章中上段的表述存在疑惑 )
)
第2,4,5个卷积层的核仅仅跟前一层的位于同一个GPU的核映射相连接。第3层的核跟第2层的所有核映射都相连。全链接层的神经元和前一层的所有神经元相连。ReLU非线性函数应用在每个卷积层和全连接层的后面。
第1个卷积层使用96个大小为11*11*3的核过滤224*224*3的输入图像,步长为4个像素。(这里我觉得有必要引用之前某高人对这个步骤的形象比喻,假设你有一张输入图像,并且有96个小朋友,每个小朋友都以不同的方式去看这张图像,得到96个不同的结果。另外,由于小朋友水平有限,一次不能看完整张图像,因此需要将图像分割,一点一点来看,不断滑动(也就是步长的概念,每次滑动多少步)窗口,最终看完整张图)。第2个卷积层以第1个卷积层的输出为输入,并且使用256个大小为5*5*48的核进行过滤。第3,4,5个卷积层相互连接,并且中间没有池化层或者正则化层。第3个卷积层有384个大小为3*3*256的核连接到第2个卷积层的输出。第4个卷积层有384个大小为3*3*192的核,第5个卷积层有256个大小为3*3*192的核。每个全连接层有4096个神经元。
4 减少过拟合
我们的神经网络架构有6000万的参数,尽管ILSVRC的1000个类别使每个训练样本强加了10位的约束在从图像到标签的映射中,但是这样仍是不够的对于学习这么多的参数而没有很大的过拟合。
4.1 数据扩增
减少过拟合的最简单常用的方法是使用标签保留转换技术人工增加数据集。这里采用了两种不同形式的数据扩增,他们都允许使用非常少量的计算从原始图像得到转换后的图像,所以转换后的图像不需要存储在磁盘上。在我们的实现中,使用Python代码在CPU上进行图像转换,而在GPU上进行先前一批图像的训练。所以,这些图像转换模式其实是计算自由的。
(下面这段其实我不太理解)
第一中形式的数据扩增技术包括生成图像转换和水平映射。我们通过从256*256的图像中抽取随机的224*224的碎片(以及他们的水平反射),并在这些提取的碎片上训练我们的网络(这就是图2中输入为224*224*3维的原因)。这使得我们的训练集规模扩大了2048倍,但是由此产生的训练样例一定高度地相互依赖。如果没有这个方案,我们的网络会有大量的过拟合,这将迫使我们使用小得多的网络。在测试时,该网络通过提取五个224×224的碎片(四个边角碎片和中心碎片)连同它们的水平反射(因此总共是十个碎片)做出了预测,并在这十个碎片上来平均该网络的softmax层做出的预测。
数据增强的第二种形式包含改变训练图像中RGB通道的强度。具体来说,我们在整个ImageNet训练集的RGB像素值集合上执行PCA。对于每个训练图像,我们成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0,标准差为0.1的高斯分布中提取的随机变量。这样一来,对于每个RGB图像像素

其中



4.2 Dropout
结合许多不同模型的预测是一种非常成功的减少测试误差的方式,但似乎对于大型神经网络来说太过昂贵,因为他们已经花费了好几天的时间去训练。然而,有一个非常有效的模型组合版本,它在训练中只花费两倍于单模型的时间。最近推出的叫做“dropout”的技术,它做的就是以0.5的概率将每个隐层神经元的输出设置为零。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。所以每次得到一个输入,该神经网络就尝试采样一个不同的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元是否存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。在测试时,我们将所有神经元的输出都仅仅只乘以0.5,对于获取指数级dropout网络产生的预测分布的几何平均值,这是一个合理的近似方法。 我们在图2中前两个全连接层使用dropout。如果没有dropout,我们的网络会表现出大量的过拟合。dropout使收敛所需的迭代次数大致增加了一倍。
5. 学习细节
我们使用随机梯度下降(SGD)来训练我们的网络,样本大小为128张图片,动量为0.9,权重衰减为0.0005。我们发现这么小的权重衰减对于我们的训练是非常重要的,换句话来说,这里的权重衰减不仅仅只是一个正则化器,它减少了模型的训练误差。权重w的更新规则为:

其中i是迭代索引,v是动力变量,

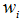
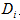
我们用一个均值为0、标准差为0.01的高斯分布初始化了每一层的权重。我们用常数1初始化了第二、第四和第五个卷积层以及全连接隐层的神经元偏差。该初始化通过提供带正输入的ReLU来加速学习的早期阶段。我们在其余层用常数0初始化神经元偏差。
我们对于所有层都使用了相等的学习率,这是在整个训练过程中手动调整的。我们遵循的启发式是,当验证误差率在当前学习率下不再提高时,就将学习率除以10。学习率初始化为0.01,在终止前降低三次。我们训练该网络时大致将这120万张图像的训练集循环了90次,在两个NVIDIA GTX 580 3GB GPU上花了五到六天。
6.结果
结果显而易见,ILSVRC-2012的冠军,远远超过了第二名26.2的top-5误差率,具体的细节不再详述,有兴趣的同学可以阅读参考文献里面的内容。
参考文献:















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









