







主要流程
在热点话题发现中,主要的流程如下:
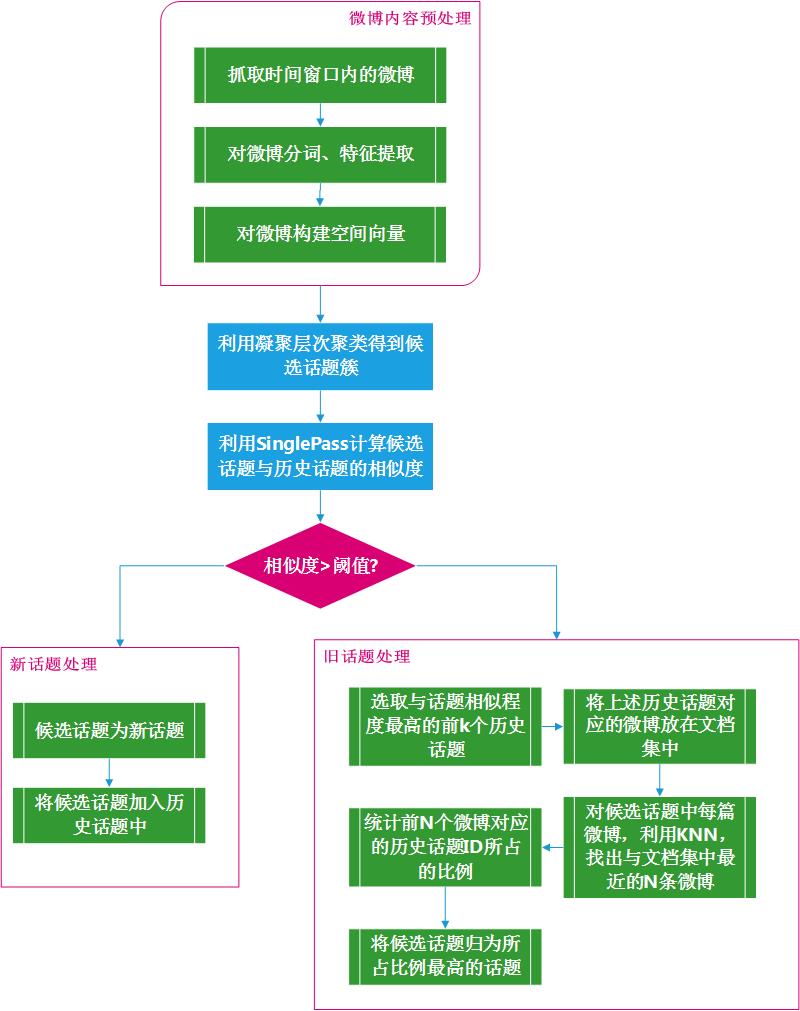
在微博流中加入一个时间窗,从时间窗开始处累计微博,直到时间窗的结尾,然后对这个时间窗内的微博进行特征抽取,得到能表示微博的词语,并转化为特征空间中的特征向量;然后利用凝聚式层次聚类算法对文档集合聚类,得到候选话题簇,然后利用 SinglePass 算法判断每个候选话题和历史话题的相似度,如果最大相似度小于阈值,则认为候选话题是一个新话题并把这个候选话题转换成新话题,然后把该话题加入到历史话题中以便后续跟踪;否则选取和候选话题相似度最高的前 K个历史话题,并把和这些历史话题相关的微博放到一个文档集合中,然后对该候选话题中的每一篇文档,利用 KNN 算法,得到每篇文档应该归入的历史话题ID,并把这些话题 ID 放入到话题集合中,然后统计每个历史话题 ID 所占的比率,并把该候选话题归入到所占比例最高的话题 ID 所对应的话题中,然后循环处理其他候选话题。
相关算法
层次聚类
层次聚类(Hierarchical Clustering)又叫树聚类算法,它通过某种文档相关性度量方法,将所有文档以树形结构的形式组织起来。树中叶子节点代表微博文档,非叶子节点为一个类簇,该类簇包含其下面的所有叶子节点所代表的微博文档。根据层次所形成的方式,层次聚类可以分为自底向上方法的凝聚法和自顶向下的分裂法。凝聚算法在进行聚类时,把每一篇微博文档初始化为一系列的单独类簇,然后对这些单独类簇进行两两合
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









