







一、前言
我们经常在工作当中使用到集合,java当中的集合类较多,且自带有丰富方法可对集合中的元素进行灵活操作,我们在使用时不必考虑数据结构和算法实现细节,只需创建集合对象直接使用即可,这给我们带来了极大的便利。本文对日常工作中常用的集合遍历问题进行简单总结。
二、java集合类图
为了便于理解,这里贴一张 java 集合类图。(来自网络)
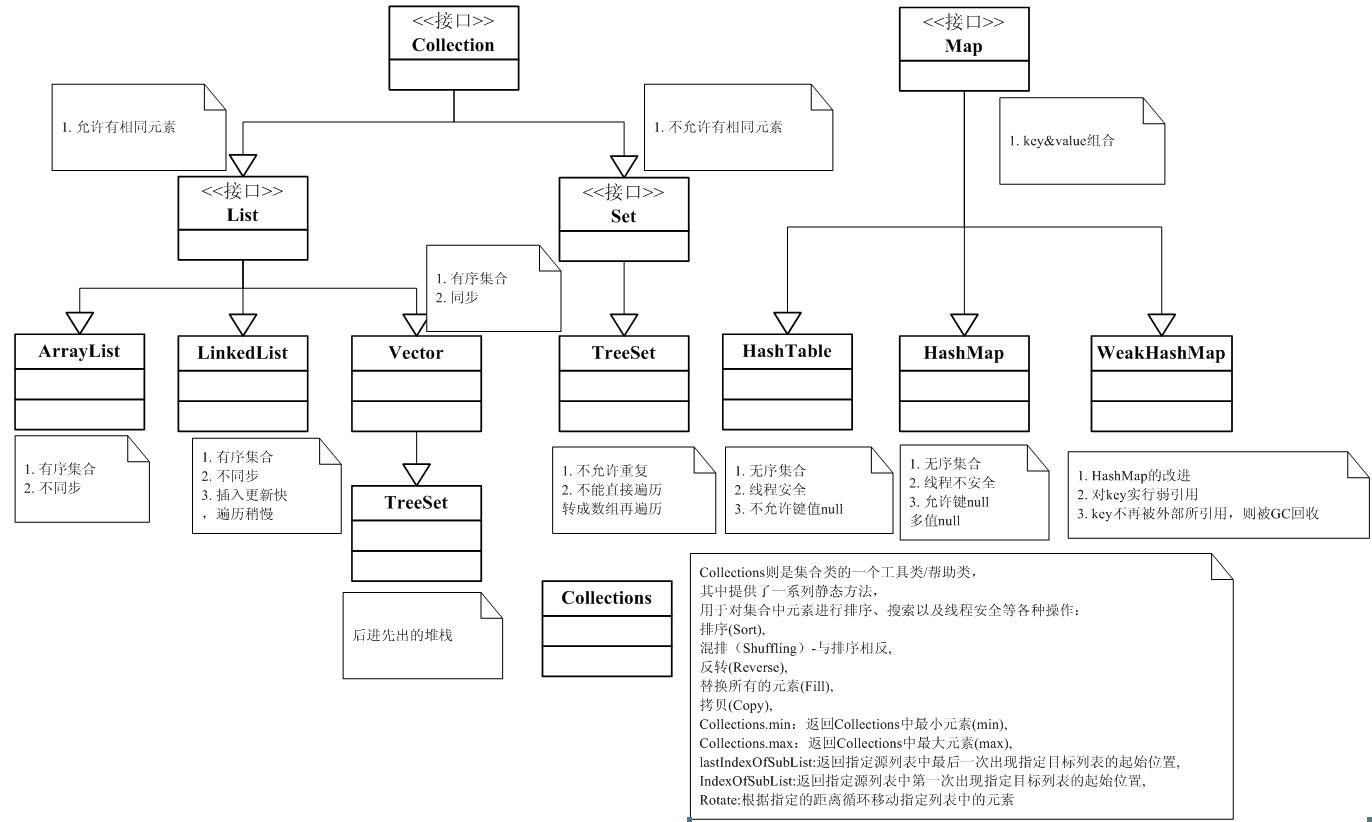
三、java常用集合遍历
java中的集合类众多,但我们常用的是ArrayList、HashMap、HashSet这几个类,本文就一这3个类分别作为 List、Map、Set 这3类集合遍历的例子。
1、ArrayList遍历
例1:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @desc 集合遍历测试
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) {
//初始化测试数据
List<String> dataList = new ArrayList<String>();
for(int i=0;i<10000000;i++){
dataList.add("data" + i);
}
//1、for循环遍历
int size = dataList.size();
long start_1 = System.currentTimeMillis();
for(int i=0; i<size ;i++){
String temp = dataList.get(i); //相关业务操作
}
long end_1 = System.currentTimeMillis();
//2、foreach遍历
long start_2 = System.currentTimeMillis();
for(String s:dataList){
String temp = s; //相关业务操作
}
long end_2 = System.currentTimeMillis();
//3、Iterator遍历
long start_3 = System.currentTimeMillis();
Iterator<String> iterator = dataList.iterator();
while(iterator.hasNext()){
String temp = iterator.next(); //相关业务操作
}
long end_3 = System.currentTimeMillis();
//输出
System.out.println("for循环遍历,耗时(ms)->" + (end_1 - start_1));
System.out.println("foreach遍历,耗时(ms)->" + (end_2 - start_2));
System.out.println("Iterator遍历,耗时(ms)->" + (end_3 - start_3));
}
}输出:
//第1次
for循环遍历,耗时(ms)->48
foreach遍历,耗时(ms)->47
Iterator遍历,耗时(ms)->50
//第2次
for循环遍历,耗时(ms)->55
foreach遍历,耗时(ms)->56
Iterator遍历,耗时(ms)->55
//第3次
for循环遍历,耗时(ms)->52
foreach遍历,耗时(ms)->57
Iterator遍历,耗时(ms)->54从上面结果可以初步发现:for循环方式使用方便一些,foreach方式的代码更简洁一些,Iterator方式的方法更灵活一些(如:其可以在集合遍历过程中 remove 元素);性能方面,对于 ArrayList 的遍历,3种方式的效率差不多,其中“for循环”遍历的方式略快一些。(注意:LinkedList 切勿用“for循环”方式,因为LinkedList数据结构决定了其获取指定节点的元素相对较慢。)
2、HashMap遍历
例2:
/**
* @desc 集合遍历测试
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) throws InterruptedException {
// 初始化测试数据
Map<String,Object> map = new HashMap<String, Object>();
for (int i = 0; i < 10000000; i++) {
map.put("key" + i, i);
}
//1、map.Entry()遍历
long start_1 = System.currentTimeMillis();
for(Map.Entry<String, Object> entry : map.entrySet()){
//相关业务操作
//System.out.println(entry.getKey() + ":" + entry.getValue());
}
long end_1 = System.currentTimeMillis();
//2、Iterator遍历
long start_2 = System.currentTimeMillis();
Iterator<Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
//相关业务操作
//System.out.println(entry.getKey() + ":" + entry.getValue());
}
long end_2 = System.currentTimeMillis();
//3、map.keySet()遍历
long start_3 = System.currentTimeMillis();
for(String key:map.keySet()){
//相关业务操作
//System.out.println(key + ":" + map.get(key));
}
long end_3 = System.currentTimeMillis();
//4、map.values()遍历获取 value
long start_4 = System.currentTimeMillis();
for (Object value : map.values()) {
//相关业务操作
//System.out.println(":" + value);
}
long end_4 = System.currentTimeMillis();
//输出
System.out.println("Map.Entry遍历,耗时(ms)->" + (end_1 - start_1));
System.out.println("Iterator遍历,耗时(ms)->" + (end_2 - start_2));
System.out.println("map.keySet()遍历,耗时(ms)->" + (end_3 - start_3));
System.out.println("map.values()遍历获取 value,耗时(ms)->" + (end_4 - start_4));
}
}输出:
//第1次
Map.Entry遍历,耗时(ms)->195
Iterator遍历,耗时(ms)->203
map.keySet()遍历,耗时(ms)->236
map.values()遍历获取 value,耗时(ms)->237
//第2次
Map.Entry遍历,耗时(ms)->187
Iterator遍历,耗时(ms)->192
map.keySet()遍历,耗时(ms)->225
map.values()遍历获取 value,耗时(ms)->215
//第3次
Map.Entry遍历,耗时(ms)->182
Iterator遍历,耗时(ms)->199
map.keySet()遍历,耗时(ms)->214
map.values()遍历获取 value,耗时(ms)->213从上面结果可以初步发现:Map.Entry方式遍历效率相对最高;Iterator方式的优点还是灵活;map.keySet()、map.values()这2种方式可分别对Map中所有的 key、value进行遍历,其中map.keySet()方式可通过遍历获取的 key 再次取值获取相应 value(这种方式获取key、value的效率较低),这2种方式代码更简洁些,适用于仅需遍历所有 key 或所有 value 的场景。
3、HashSet遍历
例3:
import java.util.HashSet;
import java.util.Iterator;
/**
* @desc 集合遍历测试
*
* @author xiaojiang
*
*/
public class CollectionTest {
public static void main(String[] args) throws InterruptedException {
// 初始化测试数据
HashSet<String> set = new HashSet<String>();
for (int i = 0; i < 10000000; i++) {
set.add("data" + i);
}
// 1、foreach遍历
long start_1 = System.currentTimeMillis();
for (String s : set) {
// 相关业务操作
String temp = s;
}
long end_1 = System.currentTimeMillis();
// 2、Iterator遍历
long start_2 = System.currentTimeMillis();
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
// 相关业务操作
String temp = iterator.next();
}
long end_2 = System.currentTimeMillis();
// 3、先转换成数组,再遍历
long start_3 = System.currentTimeMillis();
Object array[] = set.toArray();
for (int i = 0; i < array.length; i++) {
// 相关业务操作
String temp = (String)array[i];
}
long end_3 = System.currentTimeMillis();
// 输出
System.out.println("foreach遍历,耗时(ms)->" + (end_1 - start_1));
System.out.println("Iterator遍历,耗时(ms)->" + (end_2 - start_2));
System.out.println("先转换成数组,再遍历,耗时(ms)->" + (end_3 - start_3));
}
}输出:
//第1次
foreach遍历,耗时(ms)->171
Iterator遍历,耗时(ms)->201
先转换成数组,再遍历,耗时(ms)->279
//第2次
foreach遍历,耗时(ms)->191
Iterator遍历,耗时(ms)->194
先转换成数组,再遍历,耗时(ms)->284
//第3次
foreach遍历,耗时(ms)->197
Iterator遍历,耗时(ms)->194
先转换成数组,再遍历,耗时(ms)->287由以上可知 HashSet 的的遍历和 ArrayList 的遍历方法相近(ArrayList 其实也可以先转成数组再遍历),均可通过 foreach 遍历、Iterator遍历,但 HashSet 不可通过“for循环”的方式遍历,因为其没有根据索引号获取元素的方法。
四、总结
1、遍历集合前需检查集合是否为空,若为空会抛 java.lang.NullPointerException 异常。
2、在集合遍历时,经常会涉及的一个问题是线程安全问题,如:
a、Vector和ArrayList相比,两者功能类似,都继承了AbstractList类,但Vector效率没有ArrayList高,所以通常我们都使用ArrayList,而感觉Vector较陌生,不过,Vector是线程安全的而ArrayList是非线程安全的,所以,当多线程需要线程安全时,我们可以用Vector。
b、Hashtable 和 HashMap 也是功能相似,但Hashtable 是线程安全的而HashMap是非线程安全的,所以当需要线程安全时,可以用Hashtable 。
当然,ArrayList、HashMap也是可以通过Collections类中的Collections.synchronizedList(list)、Collections.synchronizedMap(m) 方法操作来达到线程安全的目的。
3、List、Map、Set等集合类的功能丰富,使用也常见,且灵活运用可给开发带来较大的便利。
4、虽然理论上集合可以存储大量数据(只要内存够),但是也需尽量避免集合中的数据量过大,以避免JVM发生长时间GC的问题。














 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









