







beautifulsoup库是解析、遍历、维护“标签树”的功能库
安装,在命令提示符中输入
pip install beautifulsoup4一般使用方法是(下面的代码环境均在idle中进行)
from bs4 import BeautifulSoup注意B和S的大写
如果需要对需要对BeautifulSoup中的片量进行查看,也可以
import bs4他的作用是来代表标签树的类型,html<=>标签树<=>BeautifulSoup
功能:BeautifulSoup对应一个HTML/XML文档的全部内容
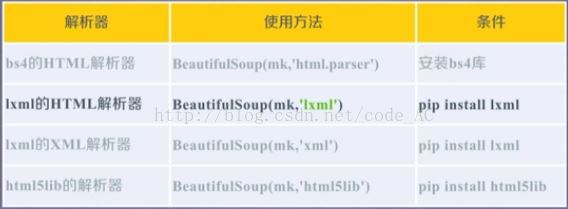
1、bs4的解析器种类
2、BeautifulSoup类的基本元素

下面进行具体的解释
(1),Tag
import requests
from bs4 import BeautifulSoup
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
soup = BeautifulSoup(demo,"html.parser")
soup.title
tag = soup.a
tag<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>继续输入如下代码
soup.a.name
soup.a.parent.name
soup.a.parent.parent.name(3)、Attributes
继续输入如下代码
tag=soup.a
tag.attrs
tag.attrs['class'](4)、NavigableString
继续输入如下代码
soup.p
soup.p.string(5)、Comment
输入如下代码
newsoup=BeautifulSoup("<b><!--this is a commment--></b><p>this is not a comment</p>","html.parser")
newsoup.b.string
type(newsoup.b.string)
newsoup.p.string
type(newsoup.p.string)3、标签树的遍历,分为下行遍历、上行遍历、平行遍历;
(1)下行遍历

查看结点时,不仅仅包括标签结点,也包括字符串结点
遍历儿子结点:
for child in soup.body.children:
print(child)

需要注意的是:
1、html的父亲标签是自己。soup的父亲标签没有
下面给出实例代码,对a标签的所有先辈的名字进行打印
import requests
from bs4 import BeautifulSoup
r=requests.get("http://python123.io/ws/demo.html")
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)(3)\标签树的平行遍历(4个属性)

标签树平行遍历的条件:遍历必须发生在同一个父亲结点下
平行标签的下一个标签可能是字符串
soup.prettify()













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









