






全部 ppt 下载地址:https://pan.baidu.com/s/1eRHgUZK#list/path=/
本来这个文章应该在很早之前就写的,可惜一直没时间,写的时候断断续续。关键是这次 leader 拓展又见晓生,每次见到他都会提醒我,这总结居然还没有写。
下面就由小 V 来总结下我在这次 Qcon2017 究竟学了啥。两个关键字,大数据和泛智能,关键是能给大家一些启发。
先说大数据
在分层测试的概念里面,最后一环是发布运营,这是我们对于质量监控的延伸。而这种延伸其实就已经涉及到"大数据"了。这里我很喜欢一个概念,大数据 = 交易资料 互动资料 观察资料
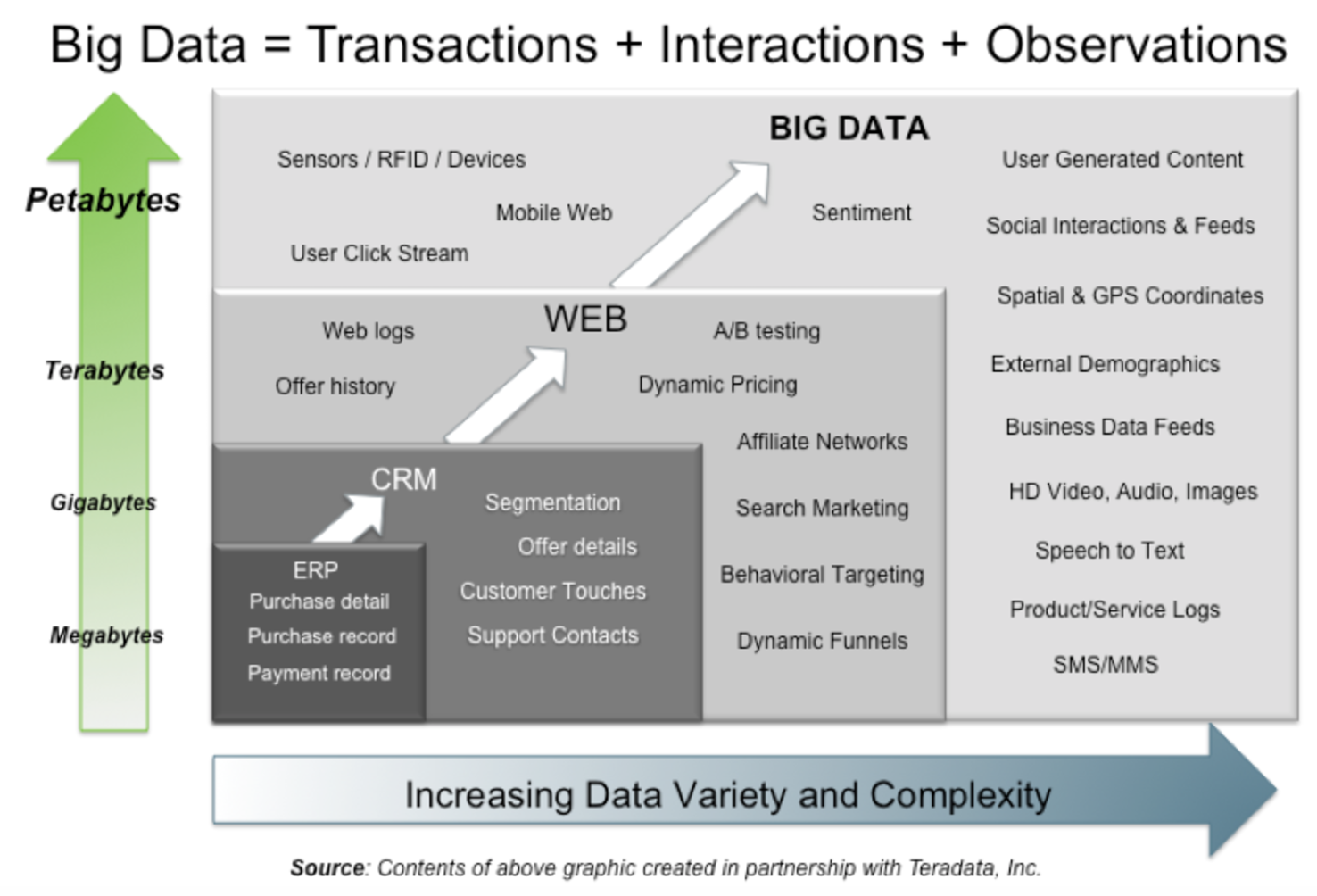
而在这几年,包括 APM,用户行为监控,其实都是在这上面做文章。对于专项测试而言,我们的 SNGAPM 的思路就是利用外网的大数据来提升专项质量的实践,包括 CT 树,触顶聚类。而同样来自我自己专题《[ 移动专项最佳实践][2]》的腾讯互娱的何老师的分享《[ 腾讯手游性能优化之路][3]》也介绍了互娱的 APM,其中一个比较有意思的实践就是利用(用户在地图的位置** 发现 GC的数据)**在 APM 后台展示王者荣耀的地图上聚类展示 GC 的点。
交互资料的建设上,比较有意思的是 [《网易乐得 "无埋点"数据采集实践之路》][4],他其实是用户行为上报的一种实践,通过"无埋点"可以解决很多数据上报的固有问题,如验证测试、需要人工配置的漏斗模型等等。在技术上,android 采用的 ASM 的方式进行静态插桩,iOS 通过 iOS Method Swizzing,主要是从控件角度来 hook,当然这里方案还有很多种,特别是 android 还有动态 hook 的方式,但是从现在 hook 方案对于 android art 的支持情况来看, ASM 确实是没有办法的办法了。比较值得推荐的原因是,1. 在分享中介绍了许多用这个技术面对的具体的坑,2. 对列表控件的行为上报的特殊理解,来挖掘用户对列表局部内容的关注度。
出了大数据的数据采集的维度,数据展示和数据分析也有一些不错的开源组件和对应的实践。这些开源组件包括:
1 . Kafka :硅谷大数据技术专题的《Apache Kafka:大数据的实时处理时代》
特点:无论在 APM 还多系统中都广泛使用的消息队列组件,分享中我影响比较深刻的是它数据的两种状态,出了众所周知的 KStream 还有 KTable。另外 Kafka ChangeLog 可以用来回溯和重建。
2 . Kudu:大数据应用专题的《基于 Impala 构建实时用户行为分析引擎》
特点:跟 HDFS,Hbase 不同的另外一种大数据存储的选择。
3 . Ambry:硅谷大数据技术专题的《分布式海量二进制文件存储系统》
特点:接口简单,I/O 性能出色,多中心同步
4 . Airflow :硅谷大数据技术专题的《Airbnb 的核心日志系统》
特点:工作流系统
5 . Superset :硅谷大数据技术专题的《Airbnb 的核心日志系统》
特点:跟我们的叮咚系统类似,但是功能和组件都非常丰富的开源的报表系统。

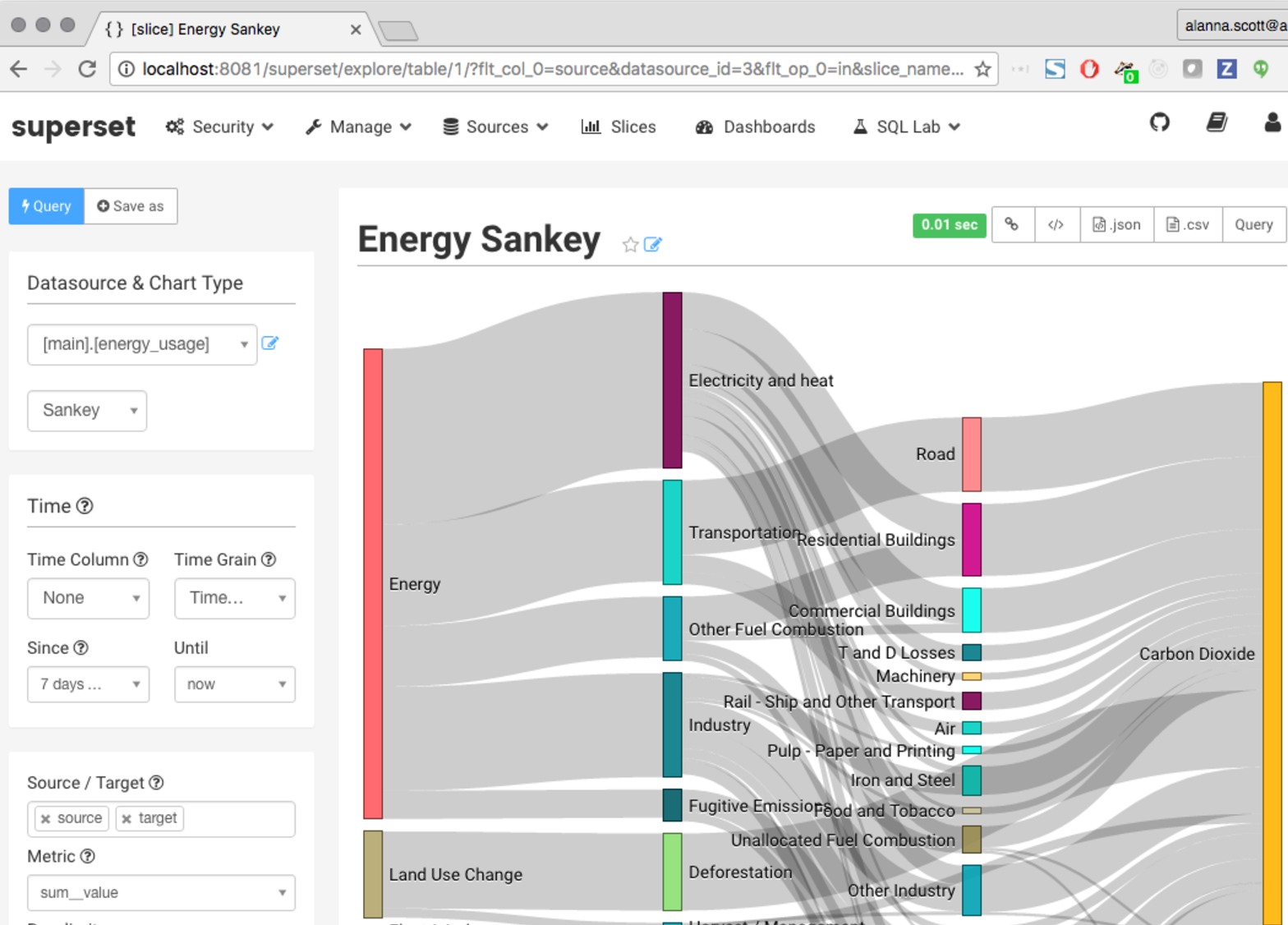
- 关于数据异常分析和展示的论文《Discovery driven Exploration of OLAP Data》,在 google 中可以下载。
(这个附带了一些感悟,国外的这些公司真的很热衷开源)
再说**泛智能**
有了"大"数据,经过数据清洗,训练,验证,落地应用就变成了现在说的机器学习。为什么说泛智能呢?因为,在整个 Qcon2017 确实大量充斥着"人工智能","机器学习",当然也不乏挂羊头卖狗肉和炫技,而不是为了解决问题。但是无论如何,这是趋势,什么东西都加上智能,运维智能,测试智能等等,我们也需要思考这里有什么东西,可以帮助我们解决问题。因此这里不论一些"智能"的落地效果,但是想法对于 app 质量提升上还是有启发的。

根据我现在知道的一些应用,我做的一些分类。主要按照监督和无监督类型来展开。
监督类
1. 生成用例:杨老师的《[ 用人工智能高效测试移动应用][8]》,爬 app,根据 app 的界面特征建模,生成测试用例。例如新的购物类 app,上传到网站上,就会自动生成购物流程的测试用例。
2. 拟合算分:罗老师的《[ 直面音视频测试之痛][9]》,使用机器学习,把各个维度的客观数据与 MOS 分进行拟合。
3. 告警:《[ 智能运维里的时间序列][10]》,使用机器学习,预测时间推移的数据变化情况,如果跟预测的不同,触发告警,通过这种方式弥补传统阈值或者简单傅立叶变换导致的误报,进而提升外网发布运营在质量上的响应速度和敏感度,
4. 原因分析:这算是个我认为比较特别的用法,利用机器学习对数据生成"决策树",然后分析"决策树",分析触发问题的充分必要条件。这算是找问题原因的一个不错的方法。
无监督
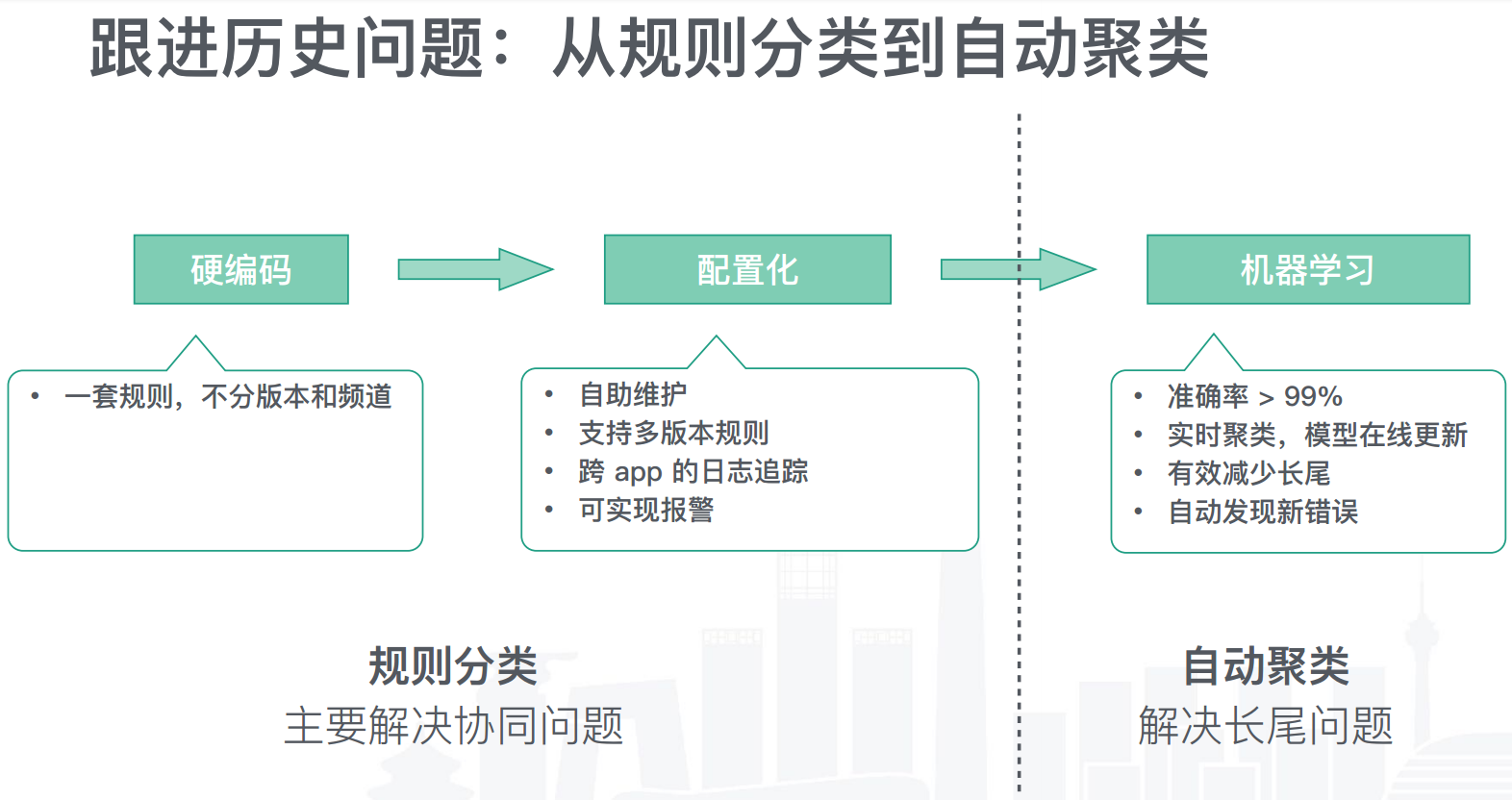
1. **解决长尾问题:**《美团 crash 监控分析系统优化之路:crash 率从千分位到万分位》,通过数据聚类,可以聚合同类问题,也可以帮助快速发现新增问题
类似的我们部门内的实践,在测试用例上,利用 k-means 聚类,减少重复用例,其实也是一种长尾问题通过聚合减少的应用。
2. 分析原因:这个是自己 yy 的,例如聚类高活跃的用户的用户行为,然后帮助更快地分析活跃的原因。
小结一下,可以看到机器学习其实可以给我们带来,聚类、分类、回归、预测、告警,大家也可以从这些方向想一下可以用来解决我们现在面对的什么问题。
其他
有诗和远方,也有眼前的苟且。除了高大尚的大数据,这里也附带分享也写我觉得不错的知识点。
《Oracle 和 MySQL 性能优化感悟》:

这个金字塔其实归纳得很好,做性能优化的时候,有一定的指导意义。
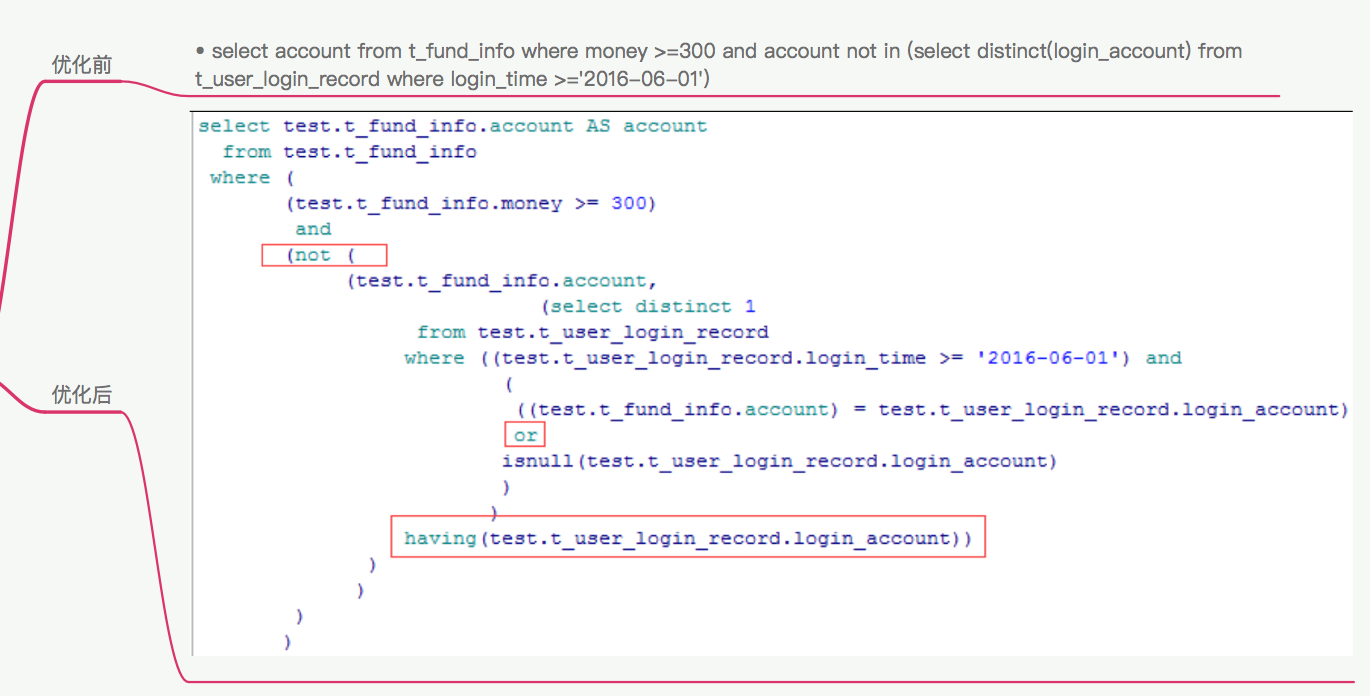
《Go 构建日请求千亿级为服务实践》:
利用对象池减少 GC,https://research.google.com/search.html?q=david lo stanford
《[Instagram 服务器性能优化实战与经验][15]》:
利用 cython 来编译 python,提升性能

python GIL 限制,不能有效地使用多线程,那么就用多进程,但是进程内存消耗大,work 进程不共享内存,内存浪费。他们利用 uWSGI 做共享内存 , uwsgi.cache_get 这个可以给 ct 入库使用。
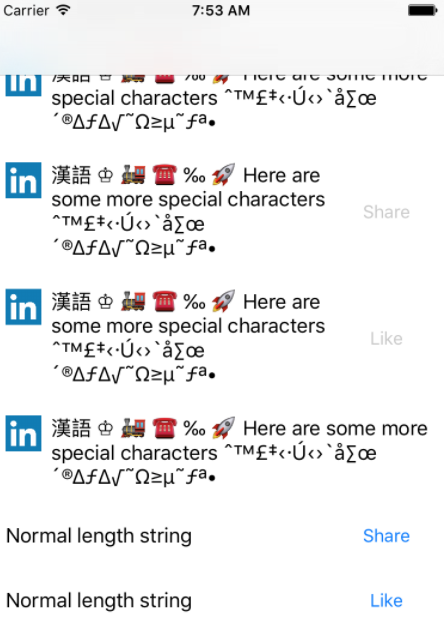
《**3 x 3:提速移动 App **交付》:
快速通过自动化做界面测试:https://github.com/linkedin/LayoutTest-iOS
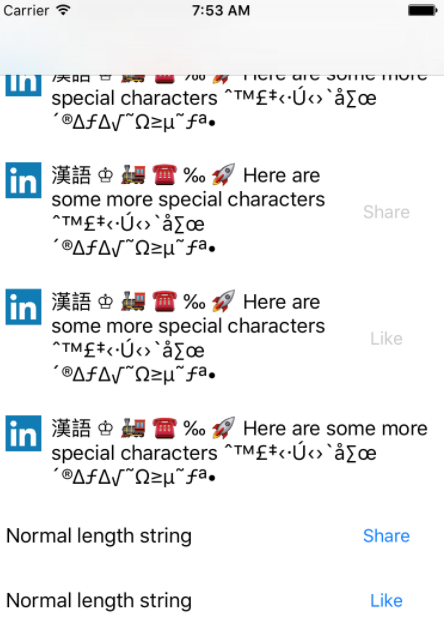
利用模拟器做自动化测试
https://github.com/linkedin/bluepill ,NewMonkey 已经在更早之前使用的类似的技术,关键的坑在启动模拟器的数量关键瓶颈在内存,大约 1 个模拟器耗费 1.5GB-2GB 的内存。
《[ 移动 App 性能监测实践][18]》:
很多人会错误使用 Method Swizzling,具体可见:http://petersteinberger.com/blog/2014/a-story-about-swizzling-the-right-way-and-touch-forwarding/
《[Software Performance Analysts: Past, Present and Future][19]》
这设计到后台性能调优,后台的性能,其实涉及到软件和硬件,就像一个数据库的调优,可以涉及 Bios,操作系统参数,数据库本身的参数调整,如何获取最优的参数组合,会有一些工具与方法论,例如 Auto-Tuning
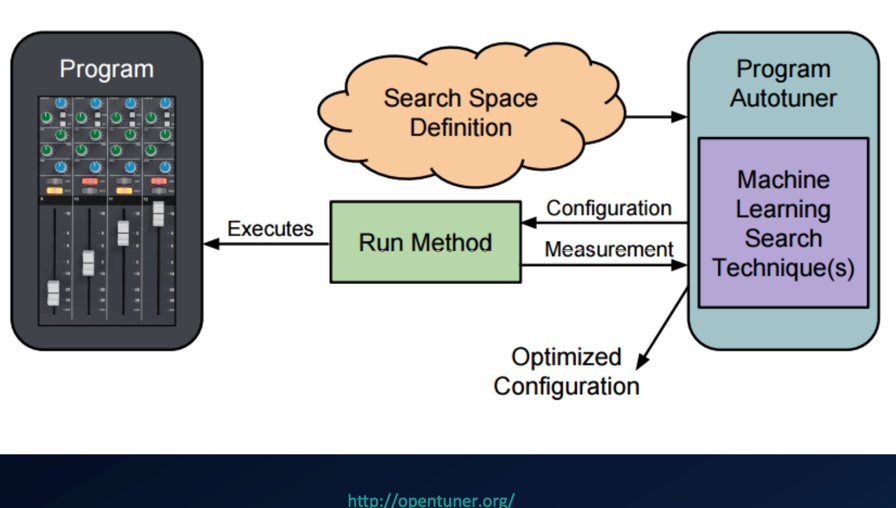
很多时候,在各大公司的后台服务中,其实 CPU 利用率其实并不高,从一些论文里面会有不少研究解决方案的。例如: Google Papers David oStanford 的论文,利用给应用分为后台类应用和前台快速响应类应用来充分利用 cpu,甚至深入到 CPU 如何保证前台快速响应类应用的 Cache。
其实大家不妨定期阅读一些论文,说不定真能拓展思路。














 8643
8643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









