







马拉松赛事日历(2016)
通过python+scrapy获取在中国田协注册的马拉松赛事日历(2016) www.runchina.org.cn
环境配置
Windows
Python 2.7
PyMongo
Scrapy
爬取的规则
class Spider(CrawlSpider):
name = “marathon”
start_urls = [
“http://www.runchina.org.cn/portal.php?mod=calendar&ac=list&year=2016&month=01&project=0”
]
i = 2;
def parse(self,response):
if(self.i>13):
return
selector = Selector(response)
ul = selector.xpath(‘//ul[@class=”match-list”]/li’)
matchs = ul.xpath(‘div[@class=”match-item”]’)
#logger.info(‘====================== %s,%s ‘,len(ul),len(matchs))
for match in matchs:
marathon = RunchinaItem()
marathon[‘_id’] = str(ObjectId())
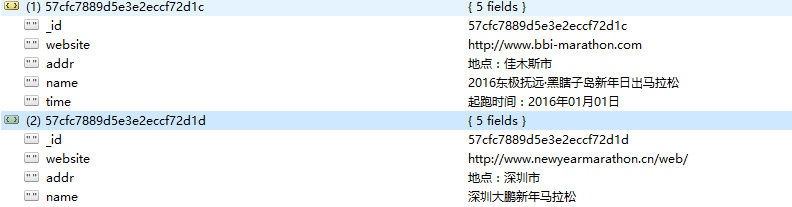
marathon[‘name’] = match.xpath(‘span[@class=”match-name text-omit”]/text()’).extract_first()
marathon[‘addr’] = match.xpath(‘span[@class=”match-info text-omit”]/text()’).extract_first()
marathon[‘time’] = match.xpath(‘span[@class=”match-info text-omit”][2]/text()’).extract_first()
marathon[‘website’] = time = match.xpath(‘span[@class=”match-info text-omit”]/a/@href’).extract_first()
#logger.info(‘========= addr ====== %s ‘,link)
yield marathon
if(self.i >= 10):
month = str(self.i)
else:
month = '0'+str(self.i)
next_month = "http://www.runchina.org.cn/portal.php?mod=calendar&ac=list&year=2016&month=%s&project=0" % month
if(next_month):
self.i += 1
yield Request(url=next_month,callback=self.parse)
代码
下载之后,直接运行 python run.py














 3872
3872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









