







文章出处: http://blog.csdn.net/starstar1992/article/details/54913261
说明
KMP算法看懂了觉得特别简单,思路很简单,看不懂之前,查各种资料,看的稀里糊涂,即使网上最简单的解释,依然看的稀里糊涂。
我花了半天时间,争取用最短的篇幅大致搞明白这玩意到底是啥。
这里不扯概念,只讲算法过程和代码理解:
KMP算法求解什么类型问题
字符串匹配。给你两个字符串,寻找其中一个字符串是否包含另一个字符串,如果包含,返回包含的起始位置。
如下面两个字符串:
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";
- 1
- 2
str有两处包含ptr
分别在str的下标10,26处包含ptr。
“bacbababadababacambabacaddababacasdsd”;\

问题类型很简单,下面直接介绍算法
算法说明
一般匹配字符串时,我们从目标字符串str(假设长度为n)的第一个下标选取和ptr长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取str下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。这样的时间复杂度是O(n*m)。
KMP算法:可以实现复杂度为O(m+n)
为何简化了时间复杂度:
充分利用了目标字符串ptr的性质(比如里面部分字符串的重复性,即使不存在重复字段,在比较时,实现最大的移动量)。
上面理不理解无所谓,我说的其实也没有深刻剖析里面的内部原因。
考察目标字符串ptr:
ababaca
这里我们要计算一个长度为m的转移函数next。
next数组的含义就是一个固定字符串的最长前缀和最长后缀相同的长度。
比如:abcjkdabc,那么这个数组的最长前缀和最长后缀相同必然是abc。
cbcbc,最长前缀和最长后缀相同是cbc。
abcbc,最长前缀和最长后缀相同是不存在的。
**注意最长前缀:是说以第一个字符开始,但是不包含最后一个字符。
比如aaaa相同的最长前缀和最长后缀是aaa。**
对于目标字符串ptr,ababaca,长度是7,所以next[0],next[1],next[2],next[3],next[4],next[5],next[6]分别计算的是
a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀的长度。由于a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀是“”,“”,“a”,“ab”,“aba”,“”,“a”,所以next数组的值是[-1,-1,0,1,2,-1,0],这里-1表示不存在,0表示存在长度为1,2表示存在长度为3。这是为了和代码相对应。
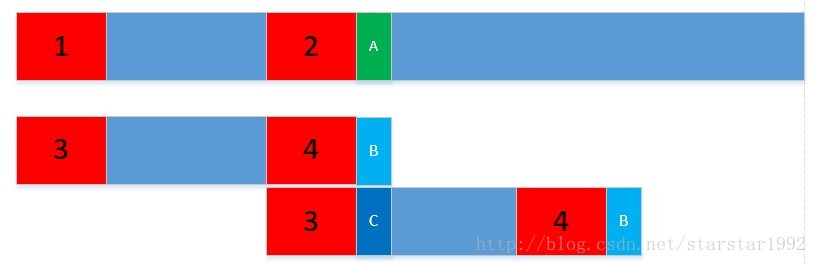
next数组就是说一旦在某处不匹配时(下图绿色位置A和B),移动ptr字符串,使str的对应的最大后缀(红色2)和ptr对应的最大前缀(红色3)对齐,然后比较A和C。
next数组的值,就是下次往前移动字符串ptr的移动距离。比如next中某个字符对应的值是4,则在该字符后的下一个字符不匹配时,可以直接移动往前移动ptr 5个长度,再次进行比较判别。

代码解析
void cal_next(char *str, int *next, int len)
{
next[0] = -1;//next[0]初始化为-1,-1表示不存在相同的最大前缀和最大后缀
int k = -1;//k初始化为-1
for (int q = 1; q <= len-1; q++)
{
while (k > -1 && str[k + 1] != str[q])//如果下一个不同,那么k就变成next[k],注意next[k]是小于k的,无论k取任何值。
{
k = next[k];//往前回溯
}
if (str[k + 1] == str[q])//如果相同,k++
{
k = k + 1;
}
next[q] = k;//这个是把算的k的值(就是相同的最大前缀和最大后缀长)赋给next[q]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
KMP
这个和next很像,具体就看代码,其实上面已经大概说完了整个匹配过程。
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
cal_next(ptr, next, plen);//计算next数组
int k = -1;
for (int i = 0; i < slen; i++)
{
while (k >-1&& ptr[k + 1] != str[i])//ptr和str不匹配,且k>-1(表示ptr和str有部分匹配)
k = next[k];//往前回溯
if (ptr[k + 1] == str[i])
k = k + 1;
if (k == plen-1)//说明k移动到ptr的最末端
{
//cout << "在位置" << i-plen+1<< endl;
//k = -1;//重新初始化,寻找下一个
//i = i - plen + 2;//i定位到找到位置处的下一个位置(这里默认存在两个匹配字符串可以部分重叠)
return i-plen+1;//返回相应的位置
}
}
return -1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
测试
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";
int a = KMP(str, 36, ptr, 7);
return 0;
- 1
- 2
- 3
- 4
注意如果str里有多个匹配ptr的字符串,要想求出所有的满足要求的下标位置,在KMP算法需要稍微修改一下。见上面注释掉的代码。
复杂度分析
next函数计算复杂度是(m),开始以为是O(m^2),后来仔细想了想,cal__next里的while循环,以及外层for循环,利用均摊思想,其实是O(m),这个以后想好了再写上。
一下是next数组的具体原理,看完后比以前明白了一些。
原文地址:http://www.cnblogs.com/c-cloud/p/3224788.html
next数组的求解思路
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模版字符串求出对应每一位的最大相同前后缀的长度。我先给出我的代码:

1 void makeNext(const char P[],int next[]) 2 { 3 int q,k;//q:模版字符串下标;k:最大前后缀长度 4 int m = strlen(P);//模版字符串长度 5 next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0 6 for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值 7 { 8 while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k 9 k = next[k-1]; //不理解没关系看下面的分析,这个while循环是整段代码的精髓所在,确实不好理解 10 if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1 11 { 12 k++; 13 } 14 next[q] = k; 15 } 16 }
现在我着重讲解一下while循环所做的工作:
- 已知前一步计算时最大相同的前后缀长度为k(k>0),即P[0]···P[k-1];
- 此时比较第k项P[k]与P[q],如图1所示
- 如果P[K]等于P[q],那么很简单跳出while循环;
- 关键!关键有木有!关键如果不等呢???那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个子串中最大相同前后缀,可能有同学要问了——为什么要求P[0]···P[k-1]的最大相同前后缀呢???是啊!为什么呢? 原因在于P[k]已经和P[q]失配了,而且P[q-k] ··· P[q-1]又与P[0] ···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了,那么我要找个同样也是P[0]打头、P[k-1]结尾的子串即P[0]···P[j-1](j==next[k-1]),看看它的下一项P[j]是否能和P[q]匹配。如图2所示
















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









