







元搜索引擎的研究和设计
计算技术研究所 李锐
colin719@126.com
摘要:论文简要介绍了元搜索引擎的相关知识,提出了一个元搜索引擎系统的设计构想。该系统采用了反馈机制,在用户察看结果时进行在线学习和调整。在系统设计中提出了搜索语法的设计、基于用户喜好的成员搜索引擎的自动调度机制、个性化服务的支持等,并给出了建立一个元搜索引擎系统的关键技术。最后分析了该系统的意义以及尚需解决的问题。
关键字:Internet 搜索引擎 元搜索引擎 信息检索 搜索语法
一. 引言
在互联网发展初期,网站相对较少,网页数量亦较少,因而信息查找比较容易。随着Internet的飞速发展,人们越来越依靠网络来查找他们所需要的信息,然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,以至于迷失在信息的海洋中不知所措,出现了我们所说的"信息丰富,知识贫乏"的奇怪现象。搜索引擎正是为了解决这个"迷航"问题而出现的技术。搜索引擎(Search Engine简称SE)以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。
现在,网上的搜索引擎有很多,比较著名的有Google,Yahoo,AltaVista,Dogpile,百度等。按照信息搜集方法和服务提供方式的不同,搜索引擎系统可以分为三大类:目录式搜索引擎,以Yahoo为代表(最近改为使用全文搜索技术);全文搜索引擎,以Google为代表;元搜索引擎,以Dogpile为代表。
二. 元搜索引擎概述
据信,一个单一搜索引擎的网络覆盖率最多只能覆盖到整个Internet资源的30-50%[3],因而查全率便无法保障;再加上任何搜索引擎的设计,均有其特定的数据库索引范围、独特的功能和使用方法,以及预期的用户群指向,导致同一个搜索请求,在不同搜索引擎中查询结果的重复率不足34%[5],因而查准率亦无法保证;因此,要想获得一个比较全面、准确的结果,就必须反复调用多个搜索引擎,并对返回结果进行比较、筛选和相互印证。元搜索引擎便应运而生。
2.1 定义
元搜索引擎(Meta Search Engine 简称MSE),是一种建立在独立搜索引擎基础上,调用其它独立搜索引擎的引擎,亦称"搜索引擎之母(The mother of search engines)"。在这里,"元"(Meta)为"总的"、"超越"之意,元搜索引擎就是对多个独立搜索引擎的整合、调用、控制和优化利用。相对于元搜索引擎,可被利用的独立搜索引擎称为"源搜索引擎"(Source Search Engine),或"成员搜索引擎"(Component Search Engine)。从功能上来讲,元搜索引擎像是一个过滤通道:以多个独立搜索引擎的输出结果作为输入,经过一番提取、剔除、萃取等操作,形成最终结果,然后将最终结果输出给用户。
2.2 元搜索引擎的典型工作过程可以归纳如下
① 用户通过统一的查询界面输入查询请求,元搜索引擎对查询进行一定的预处理。
② 元搜索引擎根据成员搜索引擎调度机制,选择若干成员搜索引擎。
③ 元搜索引擎根据选择的成员搜索引擎的查询格式,对原始查询请就进行本地化处理,转换为成员搜索引擎要求的查询格式串。
④ 向各个成员搜索引擎发送经过格式化的查询请求,等待返回结果。
⑤ 收集各个独立搜索引擎的返回结果。
⑥ 对返回结果进行综合处理,例如,消除重复链接,死链接等,形成最终结果。
⑦ 以一定的格式将最终结果返回给用户。
2.3 元搜索引擎的特点
元搜索引擎区别于独立搜索引擎,主要有这样一些特征:
① 不用设立庞大网页数据库,节省存储设备
② 提供了统一的外界模式,将一次查询提交到多个独立搜索引擎
③ 基于独立搜索引擎结果的二次加工
④ 标明结果记录的来源搜索引擎及其局部相关度,提供了全局相关度。
三. 元搜索引擎发展趋势
目前,元搜索引擎的研究、开发十分活跃。它要用到了信息检索、人工智能、数据库、数据挖掘、自然语言理解等领域的理论和技术,具有综合性和挑战性。又由于搜索引擎有大量的用户,由此衍射出许多商机,具有很好的经济价值,据估计现在已有几十亿美元的全球市场,所以引起了世界各国计算机科学界、信息产业界和商界的高度关注,已投入了不少的人力、物力,也取得了不俗的成绩。
一个理想的元搜索引擎应该具备以下功能要求:
① 涵盖较多的搜索资源,可随意选择和调用独立搜索引擎,还可根据一定调度策略进行自动调度。
② 具备尽可能多的可选择功能,如资源类型(网站、网页、新闻、软件、FTP、MP3、Flash、图像、影视等)选择、等待时间控制、返回结果数量控制、结果时段选择、过滤功能选择、结果显示方式选择等。
③ 强大的检索请求处理功能(如支持逻辑匹配检索、短语检索、自然语言检索等)和不同搜索引擎间检索语法规则、字符的转换功能(如对不支持"NEAR"算符的搜索引擎,可自动实现由"NEAR"向"AND"算符的转换等)。
④ 详尽全面的检索结果信息描述(如网页名称、URL、文摘、源搜索引擎、结果与用户检索需求的相关度等)。
⑤ 支持多种语言检索,比如提供中英文搜索等。
⑥ 可对结果进行自动分类,如按照域名、国别、资源类型、区域等进行分类整理。
⑦ 可以针对不同用户提供个性化服务。
目前Internet上面有很多元搜索引擎,良莠不齐。在功能实现上,各有侧重点,能做到"理想"的尚不多见。一些元搜索引擎在某些方面做得很好,但是在其他功能上却存在着缺陷或尚需改进:如大多数的元搜索引擎不支持自然语言检索,不支持中文检索等。元搜索引擎的功能受着源搜索引擎和元搜索技术的双重制约:一方面,源搜索引擎的各具特色的强大功能在元搜索引擎中受到限制而不能充分体现,而另一方面,任何一种元搜索技术都不能发掘和利用独立搜索引擎的全部功能。
随着新技术的不断涌现,会使元搜索引擎做得更好,取得更好的用户满意度,这些技术有:
1.提高搜索引擎对用户检索提问的智能理解,体现为对自然语言查询请求的支持。
2.确定搜索引擎信息搜集范围,提高搜索引擎的针对性,体现为主题搜索,多媒体搜索。
3.基于智能代理的信息过滤和个性化服务。
4.重视交叉语言检索的研究和开发[9],提供多语言检索的支持,提供本土化的搜索服务。
5.提高信息查询结果的精度,提高检索的有效性。
四. 一个元搜索引擎的设计构想
基于以上的研究,我们提出了一个元搜索引擎的设计构想。在这个构想中,我们采用了反馈机制,但我们并没有具体细化每一步,仅提供了一个整体框架,对于体系结构中的功能模块,我们对它们的功能和实现技术作了较为详细地分析,提供了若干可供选择的技术。在实现的时候可以选用其中的若干模块,以减少系统复杂性;也可以增加若干功能模块,以增加系统的功能,即这个设计构想具有良好的可伸缩性。
4.1 系统结构框架
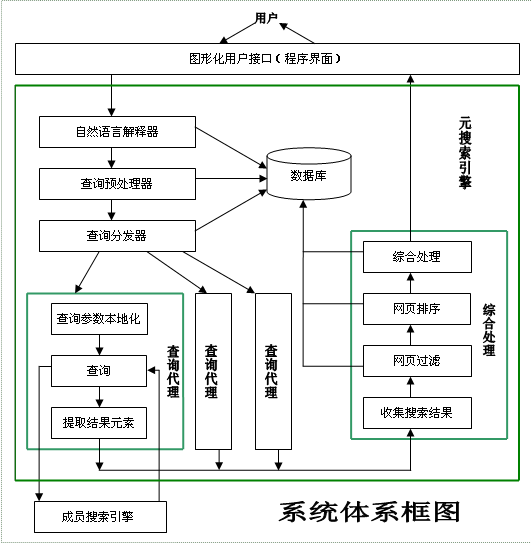
4.2 功能模块介绍
4.2.1 图形化用户接口(GUI)
这部分是程序和用户的交接面,主要用来接受用户的原始查询请求和将最终结果显示给用户。实现的时候可以采用若干界面,比如可以使用命令行方式,图形界面等。这部分不牵涉到数据的处理,可以很好地实现对一份数据的多个视图。实现是可以考虑多种人机交互技术,将用户的查询请求提交给系统即可。
在界面上可以让用户设定成员搜索引擎列表,每个成员搜索引擎的最长等待时间、返回结果数量等;以及结果显示方式、排序策略、分类方式等。这部分信息可以保存在客户端的用户cookie中,这样以来用户不必每次都输入自己的定制信息,也就提供了个性化的服务。Cookie当中也可以保存用户的搜索纪录,可以对搜索历史和搜索习惯等进行知识挖掘,用于模式发现等。
4.2.2 查询预处理器
这部分接受GUI传来的原始查询请求,并对原始查询请求进行预处理,提供交叉语言检索和自然语言支持等功能。这部分需要用到查询语法和操作,在这里简要介绍一下我们设计的查询语法和操作规则。
我们设计的查询语法和操作规则如下:
布尔逻辑运算
包括AND、OR、NOT和()等,这是最基本、最常用的语法规则:
AND 表示搜索结果中会包含所有的关键词,可以使用‘+'(加号)和空格来代替。
OR 表示搜索结果中会包含至少一个关键词,可以使用‘,'(逗号)来代替。
NOT表示搜索结果中会排除NOT之后的关键词,可以使用‘-'(减号)或‘!'(感叹号)来代替。例如:搜索JFC NOT MFC,则结果中就只包含JFC,而不包含MFC。
() 用来限制优先级,作用和数学运算中的()运算符相似。
其他简单而又较为常用的语法规则
"" 用来支持短语搜索,搜索引擎会将""中的关键词或其组合作为一个整体性的短语进行搜索。例如:搜索有关search engine方面的信息,可输入"search engine",搜索引擎就把"search engine"当作一个短语来搜索。如果不用"",就会搜索到既包含search又包含engine的信息,显然其中有很多是你不需要的。
通配符 通配符用来代替若干字符组合,类似于正则表达式。通配符可为‘*',代表任意多个字符,‘?'代表当前位置上的字符可以是任意字符。
常用高级检索语法规则
near 可限定在一定区域范围内同时出现的关键词,这些关键词可能并不相邻,间隔越小的排列位置越靠前,其间隔用near/n控制,n为一具体数值,表示间隔最大不超过n个单词。
intitle 限定仅在标题中搜索关键字
inurl 限定仅在url中搜索关键字
insite 限定仅在给定的站点中搜索资源
用户的查询请求可以用以下几部分描述:要包含的关键字(include),不包含的关键字(exclude),可以有任何一个的关键字(any),要包含的短语或句子(all),查询的区域,领域,主题,位置等。对于从GUI送过来的原始查询串,作以下处理:
1.进行自然语言解析,查询数据库,若能找到相应解答,将解答返回给用户。
2.根据搜索语法规则,扫描查询串,形成格式化的查询串,即分开哪部分是全包含,哪部分是不包含的等等。
3.从数据库中读出"stop words",与格式化查询串中的信息进行比较,剔除那些明显不必要搜索的关键字词。
4.对格式化串中的关键字进行"stemming"处理。这一步可以交给各个成员搜索引擎去实现,以减少处理的复杂性。
5.根据关键字词的信息,形成此次查询的领域,主题、区域、位置等信息。
4.2.3 成员搜索引擎调度器
在程序启动的时候,根据以往的用户的搜索历史和习惯,默认设定了若干成员搜索引擎。用户不满意还可以自己设定成员搜索引擎列表。此外程序还有自己的搜索引擎自动调度机制,根据用户的查询主题、领域、区域等信息,以及在以往的搜索中成员搜索引擎的性能表现(响应时间、返回结果数量、用户满意度、领域针对性、支持哪些高级检索功能等),产生一个合适的成员搜索引擎列表。
由于成员搜索引擎的信息(特别是查询串的格式化信息)经常发生变化,如果将它们的代码固定在元搜索引擎得主程序中显然是不合理的,因此我们采用了成员搜索引擎描述文件,以xml进行描述,采用形式化描述,对于每个新加入的成员搜索引擎,只要按照这个形式为其建立一个描述文件,就很容易将其加入到系统中。
4.2.4 查询分发器
接收由成员搜索引擎调度器产生的成员搜索引擎调度列表,连接数据库,读取这些成员搜索引擎的信息,包括主机信息、连接信息、查询参数串格式化信息等等。根据这些信息,同步启动若干线程,分别进行连接相应的成员搜索引擎。向它们发送经查询预处理器处理过的查询信息。这部分的功能的很大一部分是进行数据库的连接,其实有些信息可以让查询代理进行连接数据库,但是为了减少数据库的连接次数,把这部分功能集中起来进行一次连接,多次处理、多次使用。
4.2.5 查询代理
提供元搜索引擎和特定成员搜索引擎的交互接口。它首先接收从查询分发器送来的查询格式串。然后向查询分发器索取自己的查询参数化信息,再根据查询参数化信息,将查询格式串进行本地化,也就是转换成自己的要求格式。在这里有一个细节需要处理,就是有些成员搜索引擎肯定不支持这个元搜索引擎的部分高级检索功能,比如:不支持短语检索,通配符功能等。在处理的时候,删除原来的查询串中的这部分请求信息。
接下来就把本地化的查询请求发送到成员搜索引擎,等待返回结果。由于有时候有些服务不可用,所以可以先使用一个类似于ping命令的程序,先测试服务器是否可用,确定可用后再发送查询请求,开始连接后设置一个等待时间阀值,超时之后放弃。
接收到返回结果后,使用html解析器从结果页面中提取检索结果,需要包含以下若干信息:链接信息、得到此链接的成员搜索引擎、在成员搜索引擎中的排序信息、目标页面的站点信息、目标页面的描述信息、锚记文字等。
4.2.6 综合处理模块
这是元搜索引擎实现的核心模块,一个元搜索引擎的执行效率的好坏与这个模块的实现紧密联系在一起,它需要使用若干功能模块,具体实现技术请参考4.3节:
结果收集模块负责同步接收成员搜索引擎的返回结果,并将最先得到的成员搜索引擎的返回结果呈现给用户,以减少用户的等待时间。
网页过滤模块根据重复结果的评判标准去除返回结果中的重复链接,根据用户的资源要求、时间限制、领域限制等信息,去除冗余的链接信息。
网页排序模块是根据一定的结果融合技术对检索结果进行融合处理。
综合处理模块负责将最终结果提交给GUI,由GUI把结果呈现给用户。此模块还负责使用搜索评价机制对此次搜索进行评价,并在客户端的cookie中记录此次搜索。
4.2.7 数据库
这里的数据库是一个比较笼统的概念,既包括实际的数据库,也包括一些配置文件和设置信息等,用来保存系统运行中需要使用的数据。这些信息包括:有关于自然语言问题的解答,成员搜索引擎的信息(主机信息、功能信息、参数化信息、检索性能信息),用户信息(搜索历史信息、个性化设置信息、个人信息等),禁止词表,词汇表(同义词,反义词,翻译信息,领域信息、主题信息等)。在具体实现时,有些信息可以放在客户端,以减少服务器的存储压力。
4.3 实现中的关键技术
重复结果的评判标准[12]
搜索结果中的链接(hyperlink)、锚记(anchor)、描述(description)等可以用来判断两个结果是否重复。我们基于下面的策略进行判断:
1.首先判断两个结果的hyperlink是否相同,若相同则认为是同一结果。
2.比较URL的相似性,如果主机IP地址、路径、文件名完全相同,也认为是同一结果。
3.比较文档的元信息,比如标题、作者、摘要、大小等信息,超过相似程度阀值的结果认为是相同的。对于这一条,为了提高系统的响应速度,可以不予实现。
结果融合技术[6,13,14]
从元搜索引擎的工作原理可以看出,结果融合技术是至关重要的,因此人们也提出了很多种方法来实现。较为简单的方法有:将响应速度最快的搜索引擎的结果呈现给用户;分别显示各个搜索引擎的返回结果,不做任何处理。较为复杂一些的就是根据一定的策略来实现结果融合了。
在文献[13]中,张卫丰等人给出了4种合成算法。在文献[14]中,J.P.Callan 等人针对不同的情况也给出了4种典型的合成算法。具体请参考相关文献。结果融合的实质是对检索结果的重新排序的过程。我们提出技术基于这样的认知:一个检索结果的重要程度取决于3个方面:检索到它的成员搜索引擎的个数,它在检索到各个成员搜索引擎中的排序位置,检索到它的成员搜索引擎的性能评价。假设有m个成员搜索引擎检索到它,它在第i个成员搜索引擎的排列位置是ri,第i个成员搜索引擎的性能评价是wi,那么这条结果的最终权值p是:
p = ∑(ri * wi) i=1...m
根据用户的设定,还可以对检索结果作进一步的处理:检测目标页面是否存在,以消除死链接;取回结果的目标页面,做文本分析,以提供更高的相关度判断和提供网页快照;对处理后的结果进行分类,可以按照领域、主题、站点等进行分类。
有效信息提取技术
在接收到成员搜索引擎的返回结果后,很重要的一个技术就是如何从结果页面中提取所需要的检索结果。由于成员搜索引擎间使用的技术不同,结构也相差很大,能否正确提取结果便是一个十分棘手的问题。基于这样的一个认知:搜索的结果都是动态生成的,因此所需要的结果必定是被包装起来的,也就是可以找到一个头和一个尾,在头和尾之间的内容便是我们所需要的内容。现在的办法是使用人工的方式,寻找这个头和尾,然后在配置信息里面告诉系统,由查询代理负责根据这些信息提取所需要的结果。
现在也有这样的实现方法,就是基于统计的方法,使用人工智能技术,让系统具有自学习的功能,这样以来就不用人工的干预,可以自主形成成员搜索引擎的在结果提取方面的信息。
现在像Google提供了web services,可以直接提取相应信息(检索结果、响应时间、结果数量、文档相关度等),但是只有作为注册用户才可以无限制使用。这可能是一个更好的解决办法,因为独立搜索服务提供商更清楚自己的系统和使用的技术,也可以更直接的提供我们所需要的结果信息。
成员搜索引擎调度机制和性能评价机制[3,12]
成员搜索引擎调度技术是元搜索引擎的技术核心,即决定将用户查询发送到哪些成员搜索引擎上,可以收到好的检索效果。元搜索引擎下的每个成员搜索引擎都有自己的由一系列文档所组成的文本数据库,成员搜索引擎调度技术就是为每个查询提供最可能包含有用文档的成员搜索引擎列表,这对元搜索引擎的执行效率是至关重要的。在文献[12]中提到了四种方法:朴素算法、定性方法、定量方法和基于学习的方法。
为了实现成员搜索引擎的自动调度,我们使用用户的反馈信息,实现基于学习的调度机制,这样就需要一个成员搜索引擎的性能评价机制。
评价的依据是多次检索活动的记录数据,包括响应时间、返回数量等,其中主要部分是文档相关度,这部分知识可以通过用户提交(这是最好的方法,但是一般来讲,用户只是使用,而不进行反馈),也可以通过跟踪用户的点击链接活动来获得。评价是分层次来进行的:基于单条检索结果的评价、基于一次检索活动的评价、基于检索词的评价、基于检索领域的评价、整体检索性能的评价。
对于用户给出的搜索请求,如果系统中有各搜索引擎关于请求关键词的评价数据,则选择对这个关键词评价数据最优的一些搜索引擎进行检索;否则进行判断搜索请求是属于哪个领域,并且系统中有各成员搜索引擎在该领域的评价数据,则选择该领域最优的一些搜索引擎进行检索;否则选择整体检索性能最优的一些搜索引擎进行检索;若用户设定了使用相应速度最快或者返回结果最多等方式,则选用相应指标靠前的一些搜索引擎进行检索。
五. 浅析搜索引擎在电子商务中的应用
搜索引擎在电子商务中也可以大展伸手,现在就有很多的网站依靠Google的竞价排名服务来开展业务,这也是一些搜索服务提供商的盈利渠道之一。另外,根据用户的注册信息、搜索历史信息、搜索关键字所属领域、搜索习惯、访问记录等,可以发掘出用户的潜在购买欲望和感兴趣的商品等,这些信息可以被电子商务站点用来发现它们的潜在客户,可以给它们的客户定期发送它们感兴趣的商品更新列表等等。
六. 总结
Internet是一个庞大的信息源,它正处在急剧膨胀的时期,人们现在逐渐倾向于在网络上查找自己需要的信息。为了方便地利用Internet上的丰富资源,人们借助于相关学科的研究成果开发各种工具,搜索引擎便是其中最为常用的工具。
在已有的独立搜索引擎的基础上建立一个高效的元搜索引擎能够扩展独立搜索引擎的处理能力,提高检索的查全率,并且有可能进一步提高查准率。但是各个成员搜索引擎的自治性引起了集成的困难,困难主要来自:检索界面的差异、文档索引方法的不同、相关函数的差异、查询参数的不同、检索功能的强弱等。我们设计的系统吸收了一些成功系统的优点,同时也具有自己的特点:给出了自己的搜索语法;对搜索引擎检索效果的评价机制;成员搜索引擎的自动调度机制;设计了搜索引擎描述文件方法,使系统具有良好的可扩展性;给出了自己的结果融合算法;可以更踪用户的使用,接受用户反馈进行自主学习和调整,使系统具有自适应性。
七. 后续工作
我们选用了JAVA作为实现系统的程序设计语言工具,我们已经利用面向对象的软件工程理论分析此系统结构,并用java实现了其中的部分类的功能,定义了若干接口。接下来的工作是实现整个系统,对其中的部分算法作进一步的优化和改进。还可以根据需要,增加若干功能模块,使系统功能更加强大,系统更健壮。
[参考文献]
[1] Lawrence S.,Giles C.L. Accessibility of infomation on the Web[J]. Nature,1999,400(7):7-109
[2] Barker J. Meta-search Engines. Teaching Library Internet Workshops University of California[EB/OL]. http://www.lib.berkeley.edu/TeachngLib/Guides/Internet/MetaSearch.html,Berkeley,April 2000
[3] 基于Agent的元搜索引擎的研究与设计 陈俊杰,薛云,宋翰涛,陆玉昌,余雪丽。
计算机工程与应用,2003,Vol.10
[4] 集成搜索引擎与元搜索引擎 邢志宇 http://www.sowang.com/zhuanjia/xzhy.htm
[5] 元搜索引擎研究 张卫丰,徐宝文,周晓宇,李东,许蕾 计算机科学 2001 Vol.28
[6] 元搜索引擎系统合成算法的约束条件 阳小华,刘振宇, 谭敏生, 刘 杰, 张敏捷。
软件学报 2002 Vol.14 No.7
[7] 搜索引擎技术及趋势 李晓明,刘建国。
[8] Yang M.H.,Yang C.C.,Chung Y.M. A Natural Language Proccessing Based Internet Agent[J]. System man and Cybernetics IEEE,1997(1):100-105
[9] 交叉语言信息检索研究进展 张永奎,王树锋 计算机工程与应用 2002 Vol.19
[10] Building Efficient and Effective Metasearch Engines ACM Computing Surveys, Vol.34,No.1, March 2002
[11] 搜索引擎与Internet信息获取 薛洪明 盐城师范学院
[12] ISeeker——一个高效的元搜索引擎 彭洪汇,林作铨 计算机工程 2003 Vol.29 NO.10
[13] 元搜索引擎结果生成技术的研究 张卫丰,徐宝文,周晓宇,许蕾,李东
小型微型计算机系统 Vol.24 NO.1
[14] Callan, J.P., Lu, Z., Croft, W.B. Searching distributed collections with inference networks. In: Fox, E.A., Ingwersen, P., Fidel, R.,eds. Proceedings of the 18th International Conference on Research and Development in Information Retrieval. ACM Press, 1995.21~28.















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









