






十步优化SQL Server中的数据访问

图 2 使用SQL Server管理工作台创建索引
第二步:创建适当的覆盖索引
假设你在Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty)的外键列(ProductID)上创建了一个索引,假设ProductID列是一个高选中性列,那么任何在where子句中使用索引列(ProductID)的select查询都会更快,如果在外键上没有创建索引,将会发生全部扫描,但还有办法可以进一步提升查询性能。
假设Sales表有10,000行记录,下面的SQL语句选中400行(总行数的4%):
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
--> SELECT SalesDate, SalesPersonID FROM Sales WHERE ProductID = 112
我们来看看这条SQL语句在SQL执行引擎中是如何执行的:
1)Sales表在ProductID列上有一个非聚集索引,因此它查找非聚集索引树找出ProductID=112的记录;
2)包含ProductID = 112记录的索引页也包括所有的聚集索引键(所有的主键键值,即SalesID);
3)针对每一个主键(这里是400),SQL Server引擎查找聚集索引树找出真实的行在对应页面中的位置;
SQL Server引擎从对应的行查找SalesDate和SalesPersonID列的值。
在上面的步骤中,对ProductID = 112的每个主键记录(这里是400),SQL Server引擎要搜索400次聚集索引树以检索查询中指定的其它列(SalesDate,SalesPersonID)。
如果非聚集索引页中包括了聚集索引键和其它两列(SalesDate,,SalesPersonID)的值,SQL Server引擎可能不会执行上面的第3和4步,直接从非聚集索引树查找ProductID列速度还会快一些,直接从索引页读取这三列的数值。
幸运的是,有一种方法实现了这个功能,它被称为“覆盖索引”,在表列上创建覆盖索引时,需要指定哪些额外的列值需要和聚集索引键值(主键)一起存储在索引页中。下面是在Sales 表ProductID列上创建覆盖索引的例子:
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
--> CREATE INDEX NCLIX_Sales_ProductID -- Index name
ON dbo.Sales(ProductID) -- Column on which index is to be created
INCLUDE(SalesDate, SalesPersonID) -- Additional column values to include
应该在那些select查询中常使用到的列上创建覆盖索引,但覆盖索引中包括过多的列也不行,因为覆盖索引列的值是存储在内存中的,这样会消耗过多内存,引发性能下降。
创建覆盖索引时使用数据库调整顾问
我们知道,当SQL出问题时,SQL Server引擎中的优化器根据下列因素自动生成不同的查询计划:
1)数据量
2)统计数据
3)索引变化
4)TSQL中的参数值
5)服务器负载
这就意味着,对于特定的SQL,即使表和索引结构是一样的,但在生产服务器和在测试服务器上产生的执行计划可能会不一样,这也意味着在测试服务器上创建的索引可以提高应用程序的性能,但在生产服务器上创建同样的索引却未必会提高应用程序的性能。因为测试环境中的执行计划利用了新创建的索引,但在生产环境中执行计划可能不会利用新创建的索引(例如,一个非聚集索引列在生产环境中不是一个高选中性列,但在测试环境中可能就不一样)。
因此我们在创建索引时,要知道执行计划是否会真正利用它,但我们怎么才能知道呢?答案就是在测试服务器上模拟生产环境负载,然后创建合适的索引并进行测试,如果这样测试发现索引可以提高性能,那么它在生产环境也就更可能提高应用程序的性能了。
虽然要模拟一个真实的负载比较困难,但目前已经有很多工具可以帮助我们。
使用SQL profiler跟踪生产服务器,尽管不建议在生产环境中使用SQL profiler,但有时没有办法,要诊断性能问题关键所在,必须得用,在http://msdn.microsoft.com/en-us/library/ms181091.aspx有SQL profiler的使用方法。
使用SQL profiler创建的跟踪文件,在测试服务器上利用数据库调整顾问创建一个类似的负载,大多数时候,调整顾问会给出一些可以立即使用的索引建议,在http://msdn.microsoft.com/en-us/library/ms166575.aspx有调整顾问的详细介绍。
第三步:整理索引碎片
你可能已经创建好了索引,并且所有索引都在工作,但性能却仍然不好,那很可能是产生了索引碎片,你需要进行索引碎片整理。
什么是索引碎片?
由于表上有过度地插入、修改和删除操作,索引页被分成多块就形成了索引碎片,如果索引碎片严重,那扫描索引的时间就会变长,甚至导致索引不可用,因此数据检索操作就慢下来了。
有两种类型的索引碎片:内部碎片和外部碎片。
内部碎片:为了有效的利用内存,使内存产生更少的碎片,要对内存分页,内存以页为单位来使用,最后一页往往装不满,于是形成了内部碎片。
外部碎片:为了共享要分段,在段的换入换出时形成外部碎片,比如5K的段换出后,有一个4k的段进来放到原来5k的地方,于是形成1k的外部碎片。
如何知道是否发生了索引碎片?
执行下面的SQL语句就知道了(下面的语句可以在SQL Server 2005及后续版本中运行,用你的数据库名替换掉这里的AdventureWorks):
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
--> SELECT object_name (dt. object_id ) Tablename,si.name
IndexName,dt.avg_fragmentation_in_percent AS
ExternalFragmentation,dt.avg_page_space_used_in_percent AS
InternalFragmentation
FROM
(
SELECT object_id ,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats ( db_id ( ' AdventureWorks ' ), null , null , null , ' DETAILED '
)
WHERE index_id <> 0 ) AS dt INNER JOIN sys.indexes si ON si. object_id = dt. object_id
AND si.index_id = dt.index_id AND dt.avg_fragmentation_in_percent > 10
AND dt.avg_page_space_used_in_percent < 75 ORDER BY avg_fragmentation_in_percent DESC
执行后显示AdventureWorks数据库的索引碎片信息。
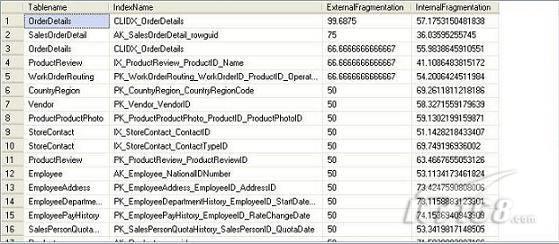
图 3 索引碎片信息
使用下面的规则分析结果,你就可以找出哪里发生了索引碎片:
1)ExternalFragmentation的值>10表示对应的索引发生了外部碎片;
2)InternalFragmentation的值<75表示对应的索引发生了内部碎片。
如何整理索引碎片?
有两种整理索引碎片的方法:
1)重组有碎片的索引:执行下面的命令
ALTER INDEX ALL ON TableName REORGANIZE
2)重建索引:执行下面的命令
ALTER INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=90,ONLINE=ON)
也可以使用索引名代替这里的“ALL”关键字重组或重建单个索引,也可以使用SQL Server管理工作台进行索引碎片的整理。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









