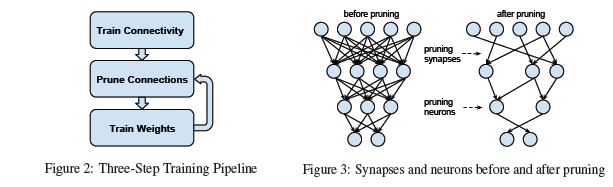
这是2015年斯坦福和英伟达的一篇论文。
转载自:http://blog.csdn.net/meanme/article/details/48713327 之前介绍的两篇关于神经网络压缩的文章都是以这篇文章为基础进行的神经网络压缩(3):Learning both Weights and Connections for Efficient Neural Network
最新推荐文章于 2023-01-15 11:51:59 发布

这是2015年斯坦福和英伟达的一篇论文。
转载自:http://blog.csdn.net/meanme/article/details/48713327 之前介绍的两篇关于神经网络压缩的文章都是以这篇文章为基础进行的 119
893
119
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言