







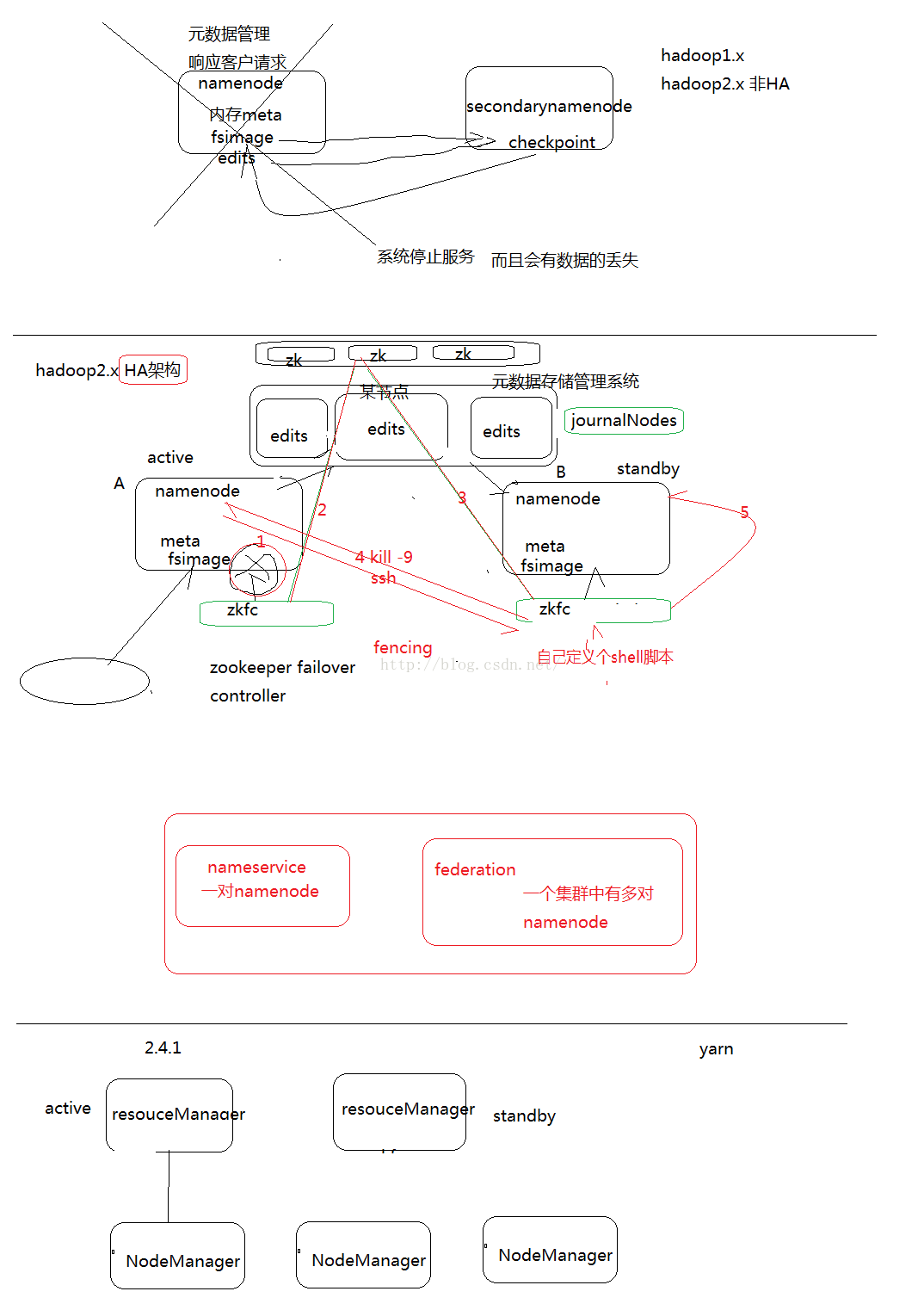
实际搭建框架图
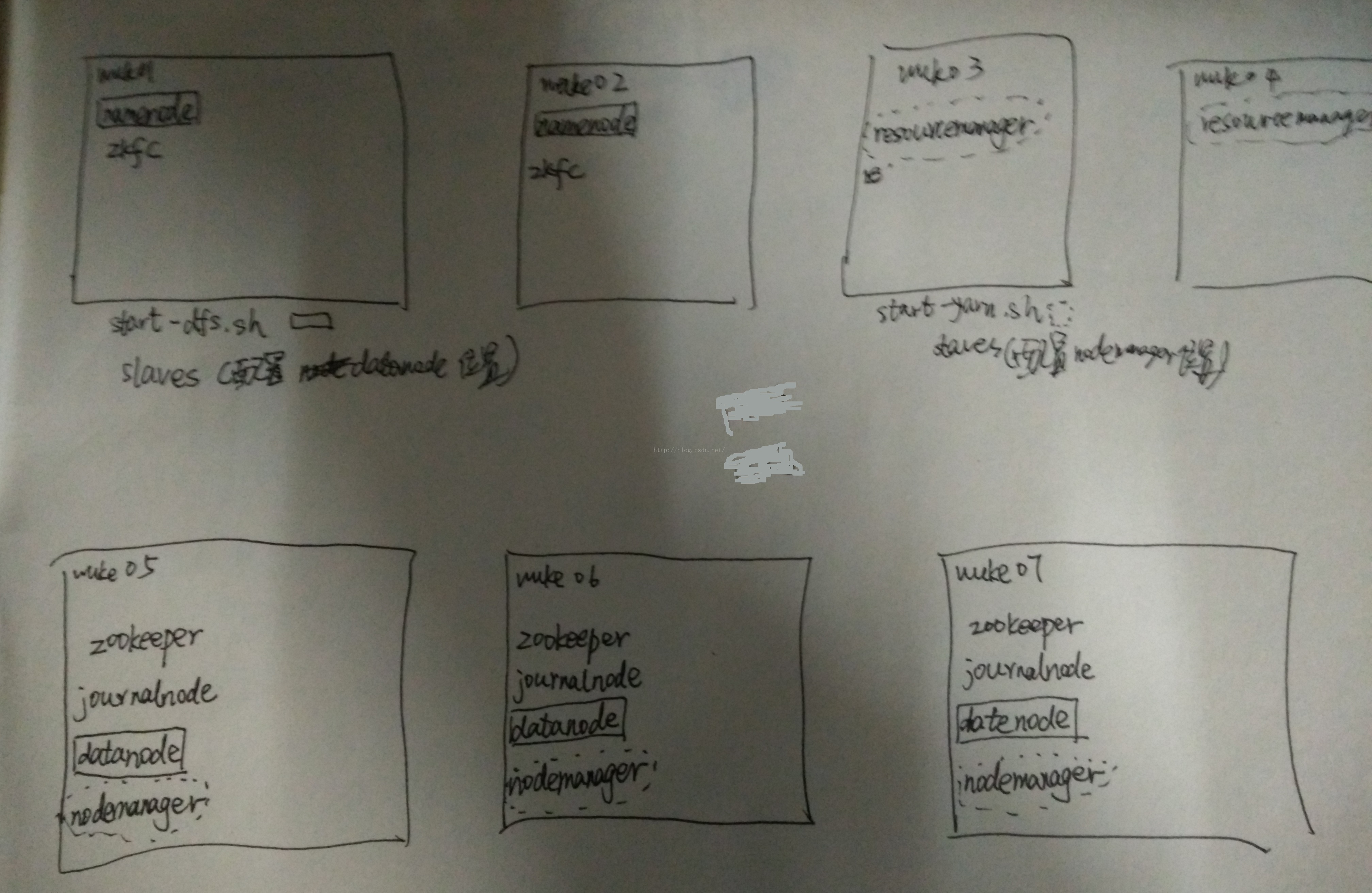
1配置文件
hadoop
core-site.xml
<configuration>
<!-- nameservice of hdfs is ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- temporary directory of hadoop-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/tmp</value>
</property>
<!-- directory of zookeeper-->
<property>
<name>ha.zookeeper.quorum</name>
<value>wuke05:2181,wuke06:2181,wuke07:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--nameservice of hdfs is ns1 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--ns1 has two nameNode,namely nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--RPC communication address of nn1 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>wuke01:9000</value>
</property>
<!--http communication address of nn1 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>wuke01:50070</value>
</property>
<!--RPC communication address of nn2 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>wuke02:9000</value>
</property>
<!--http communication address of nn2 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>wuke02:50070</value>
</property>
<!--where does namenode metadata place on JournalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://wuke05:8485;wuke06:8485;wuke07:8485/ns1</value>
</property>
<!--deposition of JournalNode place data-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/journaldata</value>
</property>
<!--turn namenode auto switch when it failed-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--configuration auto switch method-->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--configuration method of fencing -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--ssh out of login-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--timeout of fencing-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--timeout of datanode-->
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
<!--timeout of redundance datanode to delete -->
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>10000</value>
<description>Determines block reporting interval in milliseconds</description>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1638M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx3277M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>819</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx3277m</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>CNSZ22VL3578:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>CNSZ22VL3578:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!--turn on HA of resourcemanager -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--RM cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!--name of resourcemanager -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--address of resourcemanager -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>wuke03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>wuke04</value>
</property>
<!--address of zookeeper -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>wuke05:2181,wuke06:2181,wuke07:2181</value>
</property>
<yarn logs enable aggregation>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<logs after aggregation saved dir in hdfs>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<!--method of dispatch datanode -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
注意:后来项目找不到yarn,我就改成单节点了:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bdpp02</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
还加入了资源配置
<!--yarn,一个节点的总内存 (mb)-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
</property>
<property><!--yarn,一个节点的cpu总核数 -->
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
<property><!--yarn,单个任务可申请最少内存,默认1024M-->
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
</property>
<!--yarn 允许历史log>
<property>
<name>yarn.log.server.url</name>
<value>http://CNSZ22VL3578:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property
在CNSZ22VL3578上提供历史日志查询功能
执行:hadoop_home/sbin/mr-jobhistory-daemon.sh start historyserver
slaves
wuke05
wuke06
wuke07
zookpeeper
zoo.cfg
dataDir=/home/hadoop/app/zookeeper-3.4.5/data
server.1=wuke05:2888:3888
server.2=wuke06:2888:3888
server.3=wuke07:2888:3888
在wuke05,wuke06,wuke07上新建文件/home/hadoop/app/zookeeper-3.4.5/data/myid,内容分别为1,2,3
2将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=xxxxx/java/jdk1.7.0_65
export HADOOP_HOME=/xxx/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
3格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
4启动hadoop
###注意:严格按照下面的步骤
2.5启动zookeeper集群(分别在wuke05、wuke06、wuke07上启动zk)
cd app/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.6启动journalnode(在journalnode节点上执行hadoop-daemon.sh这个脚本)hadoop-daemon.sh start journalnode
cd /app/hadoop-24.1
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,wuke05、wuke06、wuke07上多了JournalNode进程
2.7格式化HDFS
#在wuke01上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/app/hadoop-2.4.1/tmp,然后将/app/hadoop-2.4.1/tmp拷贝到wuke02的/app/hadoop-2.4.1/下。
scp -r tmp/ wuke02:/app/hadoop-2.4.1/
2.8格式化ZK(在wuke01上执行即可)
hdfs zkfc -formatZK
2.9启动HDFS(在wuke01上执行)
sbin/start-dfs.sh
2.10启动YARN(#####注意#####:是在wuke03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
如果要单独启动resourcemanager 也可用 yarn-daemon.sh start resourcemanager 命令来启动
5验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.1.101:50070 (HDFS管理界面)
http://192.168.1.101:8088 (MR管理界面)
6.配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
ssh-copy-id localhost
web 查看集群情况
http://wuke02:50070
http://wuke03:8088
查看node
http://wuke05:8042
Q&A:
1. Q:
执行stop-dfs.sh后无法停止namenodes、datanodes和secondary namenodes
A:这是因为集群启动后会生成每一个进程的pid文件放在$HADOOP_PID_DIR目录下,HADOOP_PID_DIR默认值是/tmp
,linux的tmpwatch,默认在30天内文件不被访问的情况下就会被清理,所以执行stop-dfs.sh的时候找不到对应的pid文件,就会出现no namenode to stop /no datanode to stop 的情况。解决办法是在hadoop-env.sh中修改HADOOP_PID_DIR的值。例如export HADOOP_PID_DIR=/app/hadoop-2.7.3,就是把pid文件放在hadoop的安装目录下面














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









