







补充(一)
重启虚拟机后和mysql之后,发现数据库登陆不上,报错如下:

用无密码登陆进去后,执行showdatabases;发现默认数据库mysql消失了。
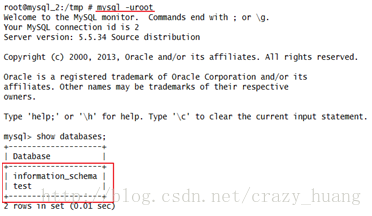
结合之前的操作,想到应该是给root附加remoteaccess权限的时候出了差错,之前User表中有4条数据,但只更改了1条,导致root用户已经没有了mysql的访问权限。
解决办法:
(1)用无权限方式重启mysql数据库
执行指令:/usr/local/etc/rc.d/mysql-serveronestop
执行指令:mysqld_safe--skip-grant-tables &

(2)重新进入mysql,并执行showdatabases;发现mysql数据库出现了,印证了问题的猜想
(3)切换到mysql数据库,清空user表
执行指令:usemysql
执行指令:deletefrom user;
(4)给user表中新增数据,并刷新权限
执行指令:insert into user set user='root',ssl_cipher='',x509_issuer='',x509_subject='';
执行指令:update user set Host='localhost',select_priv='y', insert_priv='y',update_priv='y',Alter_priv='y',delete_priv='y',create_priv='y',drop_priv='y',reload_priv='y',shutdown_priv='y',Process_priv='y',file_priv='y',grant_priv='y',References_priv='y',index_priv='y',create_user_priv='y',show_db_priv='y',super_priv='y',create_tmp_table_priv='y',Lock_tables_priv='y',execute_priv='y',repl_slave_priv='y',repl_client_priv='y',create_view_priv='y',show_view_priv='y',create_routine_priv='y',alter_routine_priv='y',create_user_priv='y'where user='root';
执行指令:updateuser set password=password('123'),host='%' where user='root';
执行指令: flush privileges;
(5)重启数据库
执行指令:/usr/local/etc/rc.d/mysql-server onestart
(6)再次登录,一切恢复正常。
主从同步原理
Mysql的 Replication 是一个异步的复制过程,从一个 Mysql instace(我们称之为 Master)复制到另一个 Mysql instance(我们称之 Slave)。在 Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql线程和IO线程)在 Slave 端,另外一个线程(IO线程)在 Master 端。
要实现 MySQL 的 Replication,首先必须打开 Master 端的Binary Log(mysql-bin.xxxxxx)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。打开 MySQL 的 Binary Log 可以通过在启动 MySQL Server 的过程中使用“—log-bin”参数选项,或者在 my.cnf 配置文件中的 mysqld 参数组([mysqld]标识后的参数部分)增加“log-bin”参数项。
MySQL 复制的基本过程如下:
1. Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2. Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
3. Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
4. Slave 的 SQL 线程检测到 RelayLog 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
实际上,在老版本中,MySQL 的复制实现在 Slave 端并不是由 SQL 线程和 IO 线程这两个线程共同协作而完成的,而是由单独的一个线程来完成所有的工作。但是 MySQL 的工程师们很快发现,这样做存在很大的风险和性能问题,主要如下:
首先,如果通过一个单一的线程来独立实现这个工作的话,就使复制 Master 端的,Binary Log日志,以及解析这些日志,然后再在自身执行的这个过程成为一个串行的过程,性能自然会受到较大的限制,这种架构下的 Replication 的延迟自然就比较长了。
其次,Slave 端的这个复制线程从Master 端获取 Binary Log 过来之后,需要接着解析这些内容,还原成 Master 端所执行的原始 Query,然后在自身执行。在这个过程中,Master端很可能又已经产生了大量的变化并生成了大量的 Binary Log 信息。如果在这个阶段 Master 端的存储系统出现了无法修复的故障,那么在这个阶段所产生的所有变更都将永远的丢失,无法再找回来。这种潜在风险在Slave 端压力比较大的时候尤其突出,因为如果 Slave 压力比较大,解析日志以及应用这些日志所花费的时间自然就会更长一些,可能丢失的数据也就会更多。
所以,在后期的改造中,新版本的MySQL 为了尽量减小这个风险,并提高复制的性能,将 Slave 端的复制改为两个线程来完成,也就是前面所提到的 SQL 线程和 IO 线程。最早提出这个改进方案的是Yahoo!的一位工程师“Jeremy Zawodny”。通过这样的改造,这样既在很大程度上解决了性能问题,缩短了异步的延时时间,同时也减少了潜在的数据丢失量。
当然,即使是换成了现在这样两个线程来协作处理之后,同样也还是存在 Slave 数据延时以及数据丢失的可能性的,毕竟这个复制是异步的。只要数据的更改不是在一个事务中,这些问题都是存在的。
如果要完全避免这些问题,就只能用MySQL 的 Cluster 来解决了。不过 MySQL的 Cluster 知道笔者写这部分内容的时候,仍然还是一个内存数据库的解决方案,也就是需要将所有数据包括索引全部都 Load 到内存中,这样就对内存的要求就非常大的大,对于一般的大众化应用来说可实施性并不是太大。当然,在之前与 MySQL 的 CTO David 交流的时候得知,MySQL 现在正在不断改进其 Cluster 的实现,其中非常大的一个改动就是允许数据不用全部 Load 到内存中,而仅仅只是索引全部 Load 到内存中,我想信在完成该项改造之后的 MySQL Cluster 将会更加受人欢迎,可实施性也会更大。
主从部署
首先确认一下目前的状态:
两台mysql server,版本都是5.5.34
现欲做如下部署:
Master:192.168.143.240 hostname:mysql_1 server-id:240
Slave: 192.168.143.241 hostname:mysql_2 server-id:241
1、配置同步账号
(1)在Master端,配置Slave的同步账号。
执行指令:grant replication slave on *.* TO 'sync'@'192.168.143.241' identified by 'sync';
执行指令:flushprivileges;
执行指令:exit

2、修改/etc/my.cnf
执行指令:cp /etc/my.cnf/etc/my.cnf.bak
(2)修改:找到[mysqld]选项卡
★修改server-id为240
★去除log-bin前面的#号
★添加一行:binlog-ignore-db=mysql (表示默认数据库不同步)如图

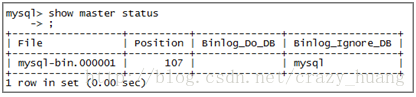
3、重启Master
(1)重启Master端,检查Master端的状态。下图表示正常。
4、修改Slave端配置文件
(1)同样先备份my.cnf,然后修改:
(2)找到[mysqld]选项卡
★修改server-id为241
★去除log-bin前面的#号

5、重启Slave端
1)重启Server端,然后再server端配置master的信息
执行指令:CHANGE MASTER TO MASTER_HOST='192.168.143.240',MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107;
其中,MASTER_HOST是Master的IP地址,MASTER_USER和MASTER_PASSWORD是在Master端新建的同步账号和密码,MASTER_LOG_FILE和MASTER_LOG_POS在master执行show master status可以找到。
(2)启动slave端
执行指令:startslave;
(3)检查Slave端的状态:
执行指令:showslave status \G
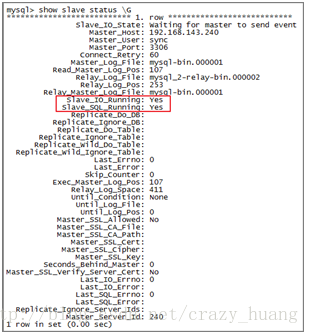
一般来说,Slave_IO_Running和Slave_SQL_Running两个值为YES,基本就成功了,之后再做一次同步测试即可。
主从同步测试
(1) 在master新增一个数据库,在数据库中添加一张表,并增加若干条记录,检查slave端是否有相应的数据。
(2) 在master删除该数据库,检查slave端对应的数据也已经删除。
主从切换
这章的主从切换,介绍了怎么手工进行主备切换,后续会借助HA软件和脚本实现自动切换。
(1)分别检查主从的状态,确保两边同步已经完成。
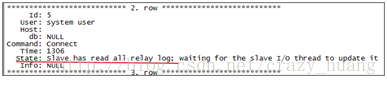
执行指令:show processlist;
出现“has read all relay log”字样,表示已经完成,可以进行切换
(2)从库操作
执行指令:STOP SLAVE IO_THREAD;
执行指令:showslave status \G.
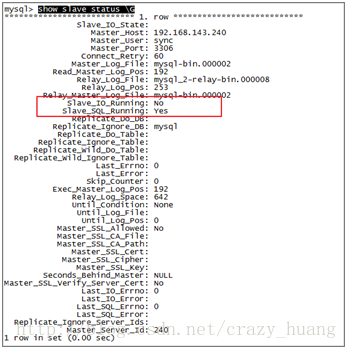
(3)从库变主库
执行指令:STOP SLAVE;
执行指令:RESET MASTER;
执行指令:RESET SLAVE;
同时,从库应该增加同步账户:grantreplication slave on *.* TO 'sync'@'192.168.143.240' identified by 'sync';
(4)主库变从库
执行指令:RESET MASTER;
执行指令:RESET SLAVE;
执行指令:CHANGEMASTER TO MASTER_HOST='192.168.143.241',MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=107;
(参数值需要按照实际情况填写)
执行指令:startslave;
(5)分别重启主从库
(6)检查状态,如果有异常,在根据错误进行处理。
互为主备
现在的情况是241的机器是主机,而240的机器是备机,配置互为主备,实际就是在当前情况下,按照第二章节,把240作为主机,241作为备机在配置一遍。
在240上reset master;
在241上,先stop slave,然后CHANGE MASTER TOMASTER_HOST='192.168.143.240',MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000003',MASTER_LOG_POS=107;(注意参数需要按照实际情况填写),最后start slave。
检查两边的状态,showmaster status,showslave status,showprocesslist(此时processlist里应该同时包含master和slave的信息)。
在测试一遍主从同步即可,无论在哪边操作数据,都会同步到另外一个数据库。
同步故障
如果主从数据不一致
如果出现(比如在slave上误删了数据)需要手动同步,大概步骤如下:
1.锁住master 的表,防止有新的数据插入
执行指令:flush tableswith read lock;
2.将master的数据导出
执行指令:mysqldump -uroot-p -hlocalhost > mysql.bak.sql(命令行执行)
3.把mysql.bak.sql传到slave端/tmp下
执行指令:scpmysql.bak.sql root@192.168.143.241:/tmp/
4.重置slave端数据,并将master的数据导入
执行指令:stop slave;
执行指令:source /tmp/mysql.bak.sql
执行指令:CHANGE MASTER TOMASTER_HOST='192.168.143.240',MASTER_USER='sync',MASTER_PASSWORD='sync',MASTER_LOG_FILE='mysql-bin.000003',MASTER_LOG_POS=107;(注意参数需要按照实际情况填写)
执行指令:startslave;
备机状态出现错误
此类错误一般是由于事件回滚不一致导致,错误形态,一般如下:
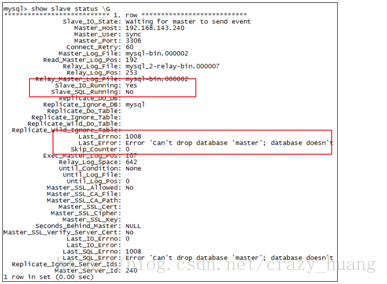
解决方法,手动跳过这个错误:
执行指令:stop slave;
执行指令:set globalsql_slave_skip_counter =1; (这个是偏移量,可以是1,也可以是n,原理参考主从同步原理)
执行指令:startslave;














 3319
3319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









