







本节课分为四个部分:
- Markov Processes(MP)
- Markov Reward Processes(MRP)
- Markov Decision Processes(MDP)
- MDP扩展
上节课在讲完全可观察环境的时候有提到MDP,几乎所有的增强学习问题都可以简化为MDP问题。那么MDP是什么呢?首先谈一下Markov的性质:“The future is independent of the past given the present”,也就是给定当前状态,未来怎么样,从当前状态就可以得出——当前状态包含了历史的所有信息。
以下是MP、MRP和MDP的比较
| 比较 | MP | MRP | MDP |
|---|---|---|---|
| 定义 | 无记忆的随机过程,也就是一系列具有Markov性质的状态 | 具有价值的MP | 带有决策的MRP |
| tuple | ⟨S,P⟩ | ⟨S,P,R,γ⟩ | ⟨S,P,A,R,γ⟩ |
| 备注 |
S
是状态的有限集合 P 是状态转移概率矩阵 Pss′=P[St+1=s′|St=s] |
γ
是折扣因子,
γ∈[0,1]
Rs=E[Rt+1|St=s] |
A
是行动的有限集合 |
| 价值函数 | state-value function v(s)=E[Gt|St=s]=E[Rt+1+γv(St+1)|St=s] | state-value function vπ(s)=Eπ[Gt|St=s] action-value function qπ(s,a)==Eπ[Gt|St=s,At=a] |
其中
Gt
是在时间t的总的带折扣的奖励值:
MRP的价值函数可以用矩阵表示:
v=R+γPv
即 v=(I−γP)−1R
对于n个状态,复杂度是 O(n3) ,当状态较少时,这个可以用,但是当状态较多时,计算量就很大。
MDP和MRP的价值函数略有不同,MDP增加了行动-价值函数
q
,并且MDP的价值函数与策略相关。
策略
一个策略能够完全定义智能体的行为,因此:
MDP利用bellman方程计算得到的两个价值函数(Bellman Expectation Equation):
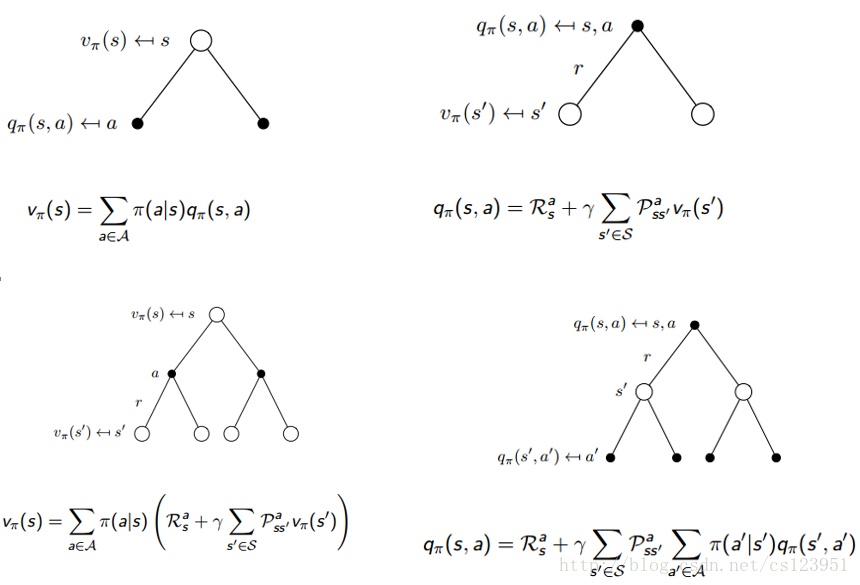
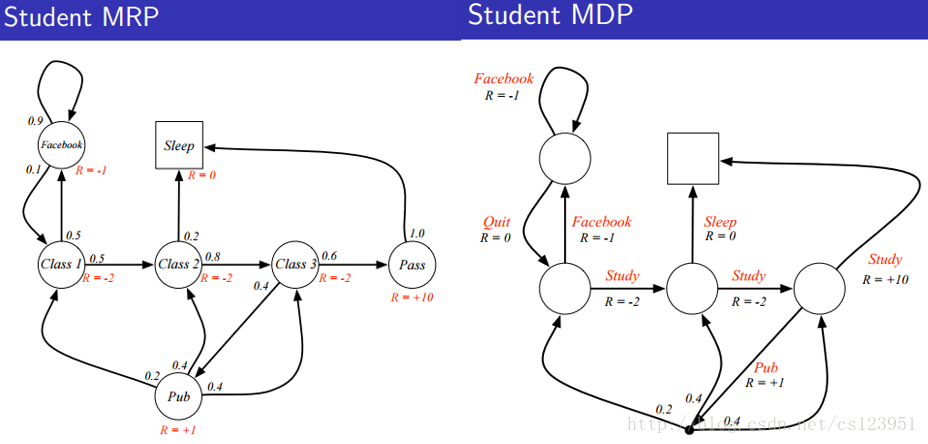
以下分别是MRP和MDP的例子:
接下来讨论最优价值函数:
q∗(s,a)=maxπqπ(s,a)
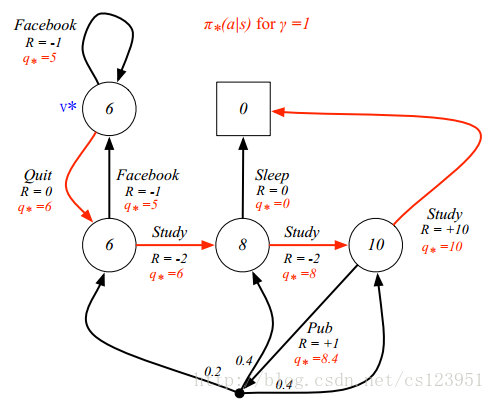
定义最优策略 π :
通过 找到最大化 q∗(s,a) 对应的行动,可以找到最优策略,得到最优方程(Bellman Optimality Equation)。
v∗(s)=maxa(Ras+γ∑s′∈SPass′v∗(s′))
q∗(s,a)=Ras+γ∑s′∈SPass′q∗(s′,a′)
Bellman Expectation Equation和Bellman Optimality Equation在后面会多次用到。














 9926
9926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









