




👂 Seasons in the Sun - Westlife - 单曲 - 网易云音乐
索引下部分 -> Mysql进阶(中) -- 索引_千帐灯无此声的博客-CSDN博客
👈目录 -- 查看左栏
目录
ฅʕ•̫͡•ʔฅ关于[root@192~] 和 mysql>
来自黑马Mysql,只用作学习,链接 -> 11. 进阶-索引-结构-Btree_哔哩哔哩_bilibili
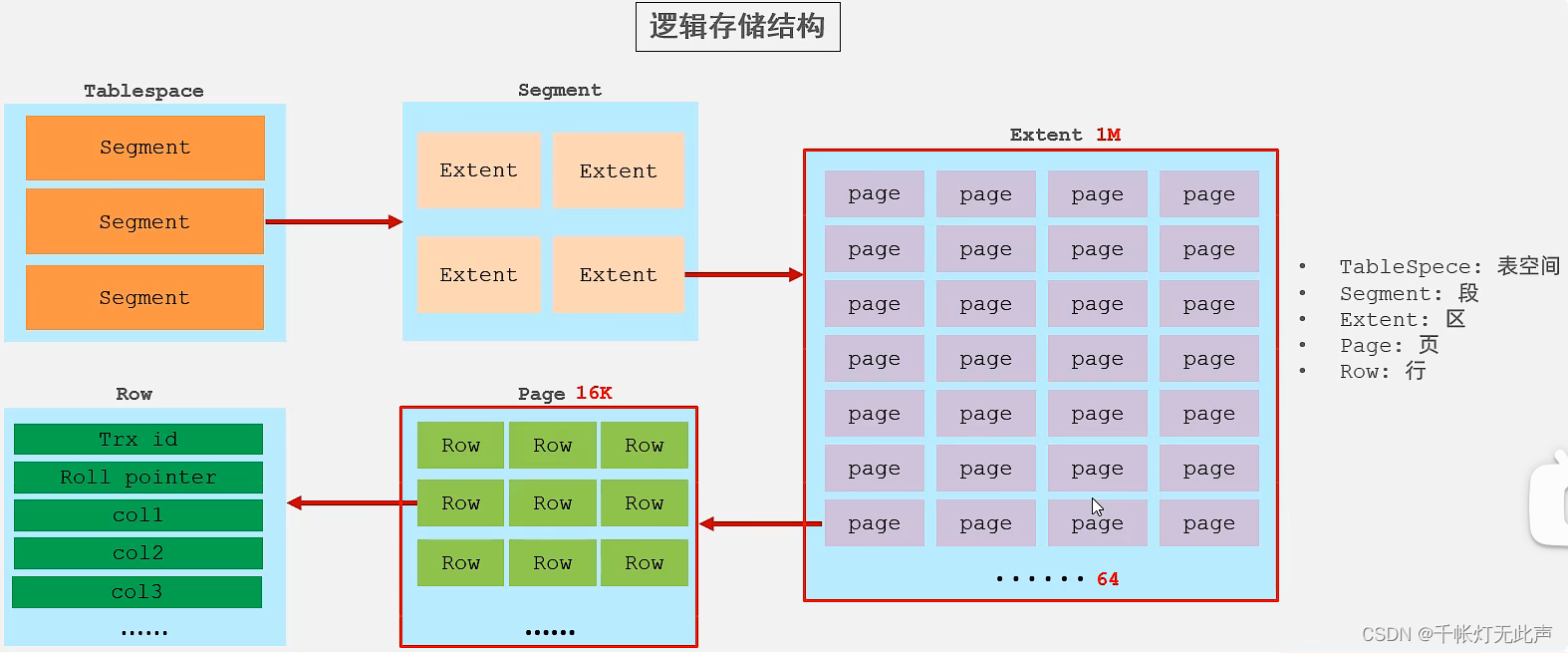
🐘存储引擎
🦁Mysql体系结构
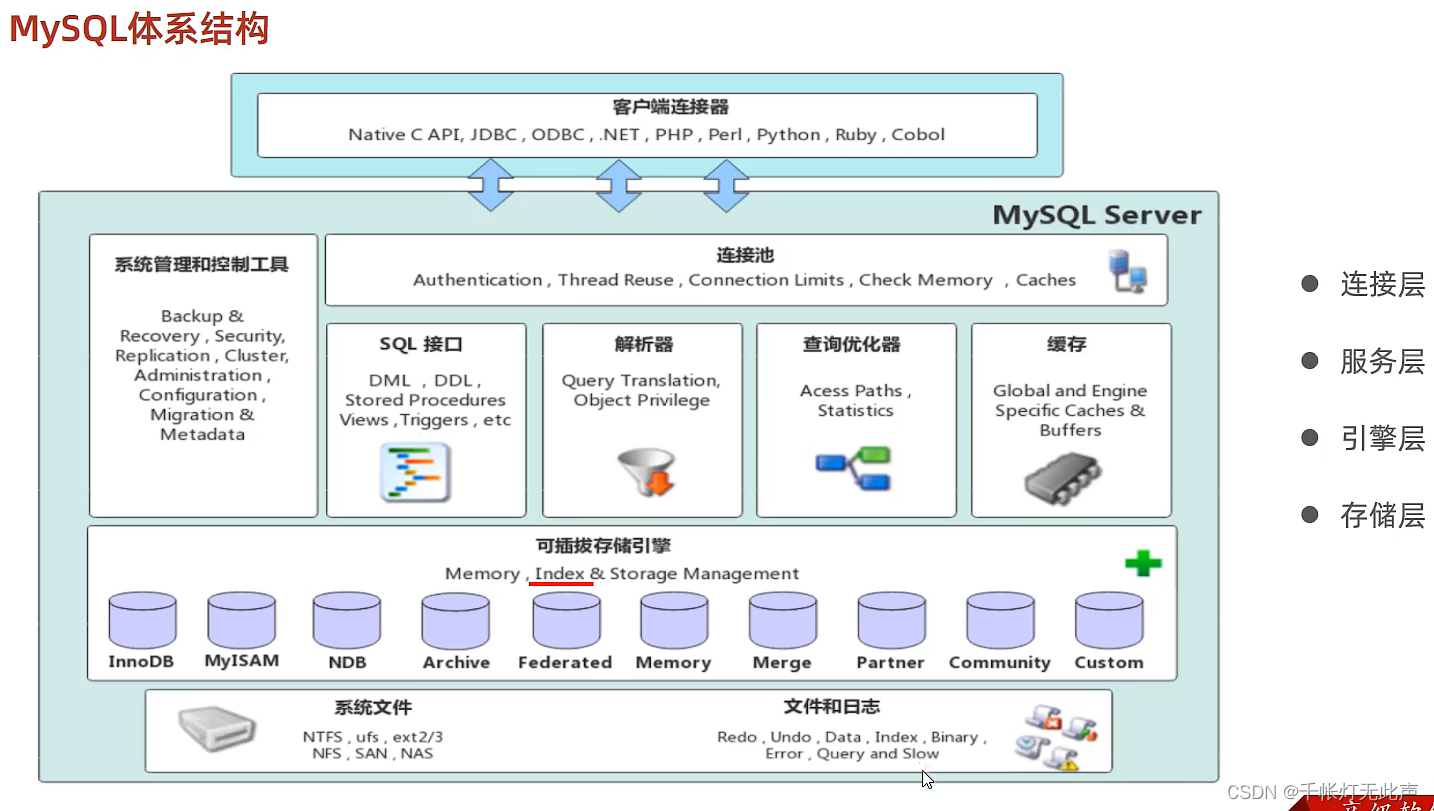

🦁简介


use itcast;
-- 查询建表语句 -- 默认存储引擎:InnoDB
show create table account;
-- 查询当前数据库支持的存储引擎
show engines;
-- 创建表 my_myisam,并指定MyISAM存储引擎
create table my_myisam(
id int,
name varchar(10)
) engine = MyISAM;
-- 创建表 my_memory,并指定Memory存储引擎
create table my_memory(
id int,
name varchar(10)
) engine = memory;🦁InnoDB介绍

-- 查看系统变量
show variables like 'innodb_file_per_table';🦁MyISAM和Memory
一道面试题👆,考察InnoDB和MySIAM的区别


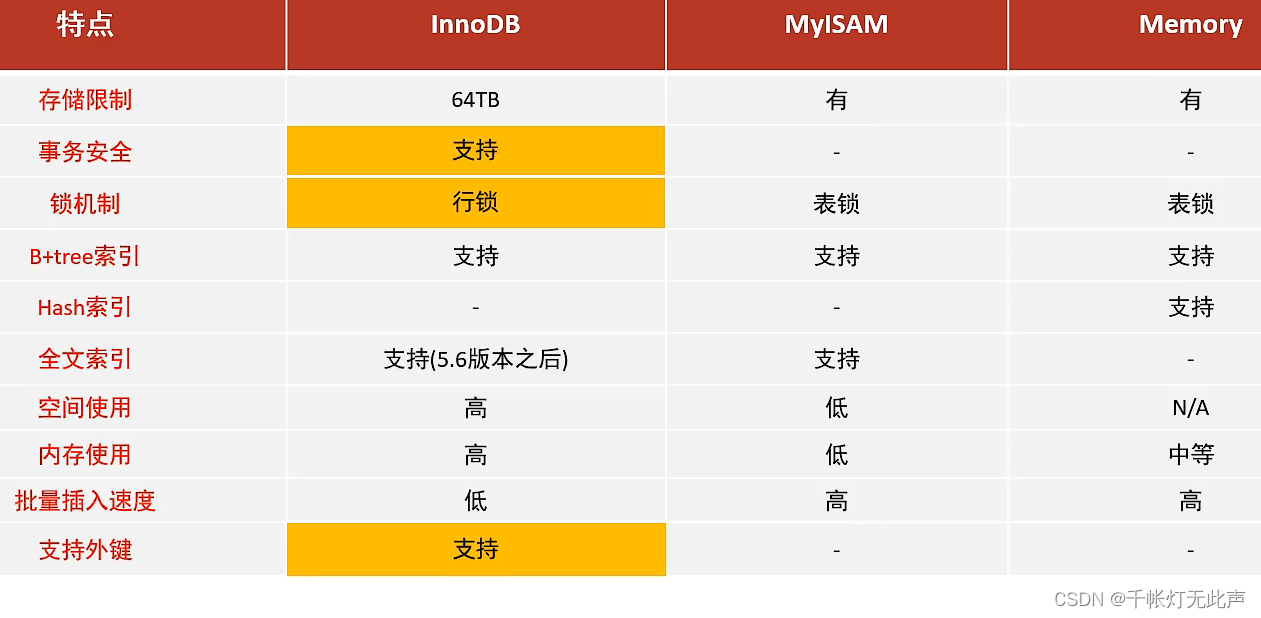
🦁选择
InnoDB是大多数开发的选择,而MyISAM和Memory被NoSQL系列的数据库替代了
具体的说,myisam被mongoDB取代了,Memory被Redis取代了

🦁小结

🐘Mysql安装(linux版本)
B站,Google,百度,GPT
翻烂了,才搞定这部分,放几个链接(虚拟机真的老大难,按着教程来一直有BUG,一个是有些细节没讲到,比如默认设置需要自己改,比如Centos7的版本和22年之前甚至22年的版本都不太一样.....不过摸索一次也是锻炼。以后要外网访问项目还可以买服务器,或者内网穿透)
ubuntu和centos教程B站有,其他的问gpt和goole,百度就行
安装了虚拟机,VMware里弄了Ubuntu和Centos
(1)
08. 进阶-MySQL安装(linux版本)_哔哩哔哩_bilibili
(2)
(1条消息) 《Linux篇》超详细安装FinalShell并连接Linux教程_finalshell连接linux_陈老老老板的博客-CSDN博客(3)
centos7如何查看ip信息(centos 6.5以前都可以用ifconfig 但是centos 7里面没有了,centos 7用什么查看?)_51CTO博客_centos7 查看IP
(4)
centos7怎么查看ip地址 - 掘金 (juejin.cn)
(5)
关于VM虚拟机(Finalshell的连接问题)_finalshell连接不上虚拟机_unique馒头的博客-CSDN博客
(6)

终于用finalshell连接上CentOS了....弄了一天.....
上面只弄了第1步,后续的比较简单,跟着视频就行👇

第5步,安装Mysql安装包
rpm -ivh mysql-community-common-8.0.26-1.e17.x86_64.rpm
rpm -ivh mysql-community-client-plugins-8.0.26-1.e17.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.26-1.e17.x86_64.rpm
rpm -ivh mysql-community-libs-compat-8.0.26-1.e17.x86_64.rpm
rpm -ivh mysql-community-devel-8.0.26-1.e17.x86_64.rpm
yum remove mysql-libs
...(12)DataGrip远程连接Mysql
关闭Linux的防火墙:步骤与必要性(关闭linux的防火墙)-数据库远程运维 (dbs724.com)
在Finalshell关闭Linux防火墙,才可以连接成功

🐘索引
🐅概述
索引是一种,高效获取数据,的数据结构
上述二叉树索引结构,只是示意图,并非真实索引结构👆
索引能提高 查 的效率,但是会降低 增删改 的效率,当然,对于大部分业务,查询占比大的多

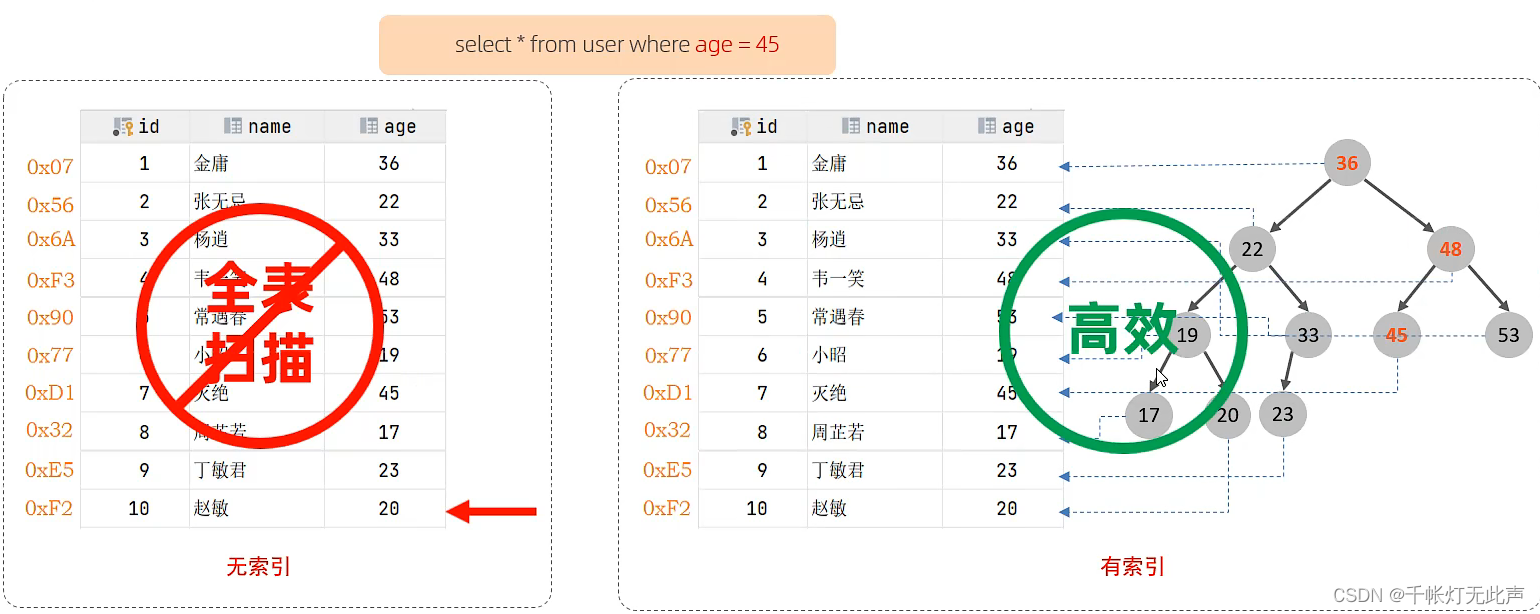

🐅结构 - 介绍
主要学习B+Tree,其次是Hash索引

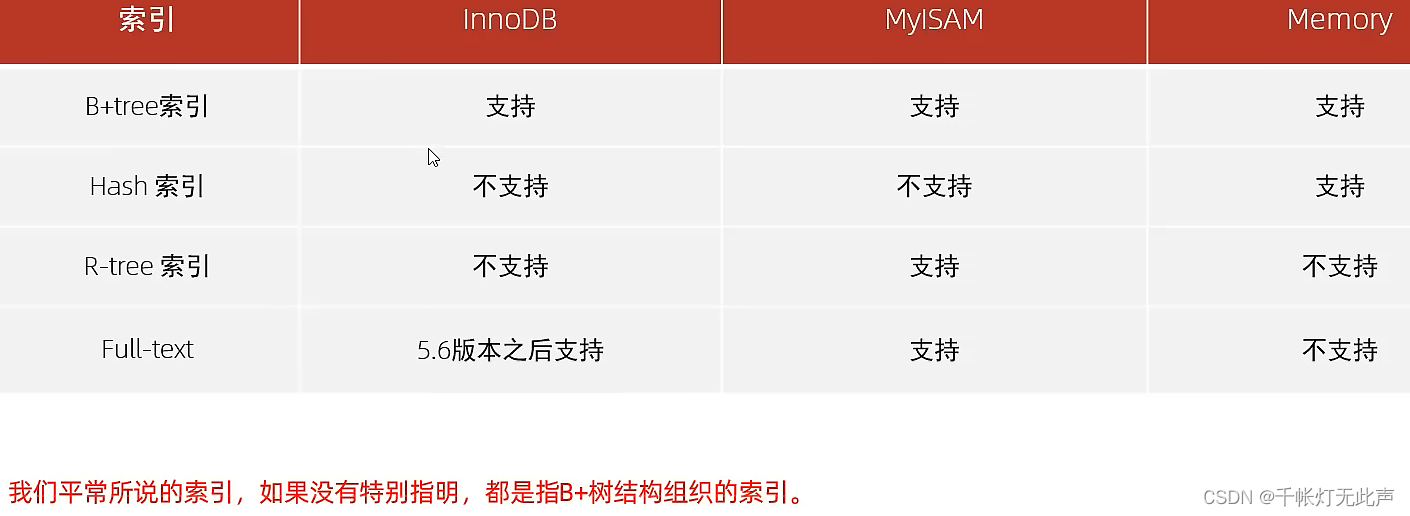
🐅结构 - Btree
左子树都小于根节点,右子树都大于根节点
同样是左小右大 ;
n个key,n + 1个指针
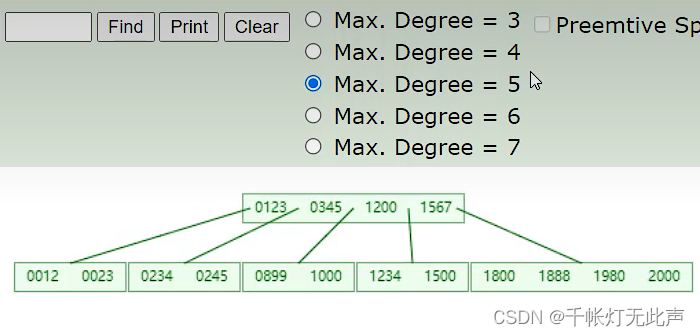
比如5阶的BTree,每个节点最多4个key
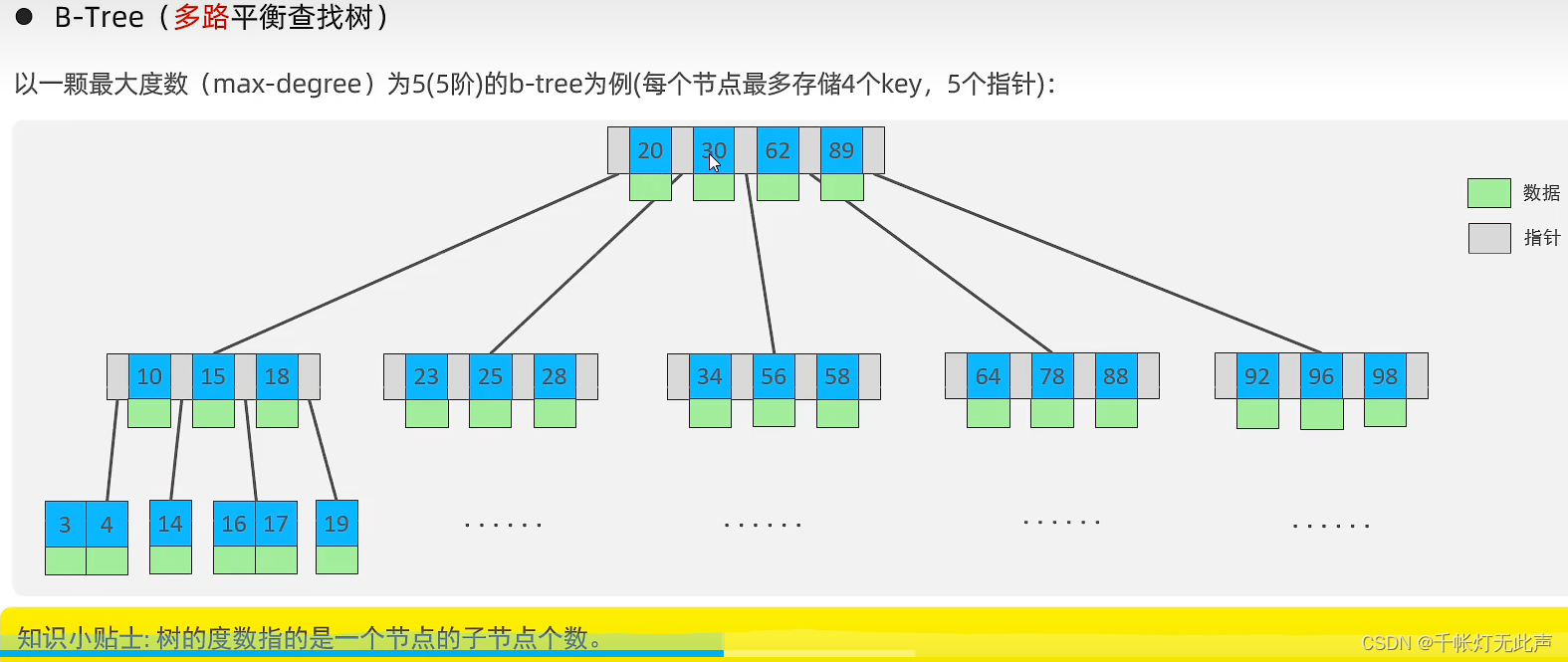
下面演示BTree构造的过程👇
黑马 -- 数据结构可视化链接:
B-Tree Visualization (usfca.edu) and Data Structure Visualization (usfca.edu)
或者用我之前推荐的:数据结构和算法动态可视化 (Chinese) - VisuAlgo
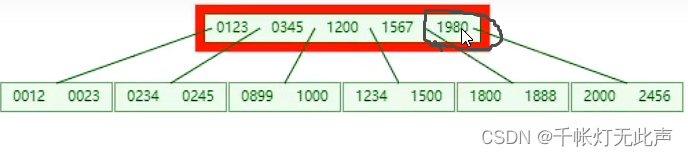
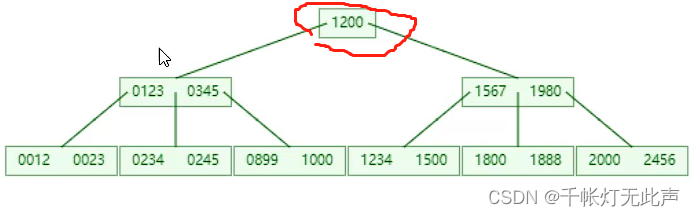
核心是,某个节点达到最大的key时,中间元素向上分裂
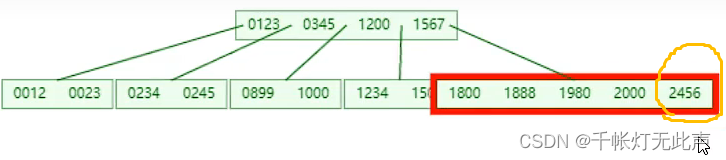
👆已经插入很多数据,下面演示再插入个2456的变化
(1)
(2)
(3)
这就是BTree的演变过程,每一个key下都会挂对应的数据
🐅结构 - B+tree
(1)所有元素都会出现在叶子节点,上面的元素只是起到索引的作用
(2)叶子节点是单向链表的形式
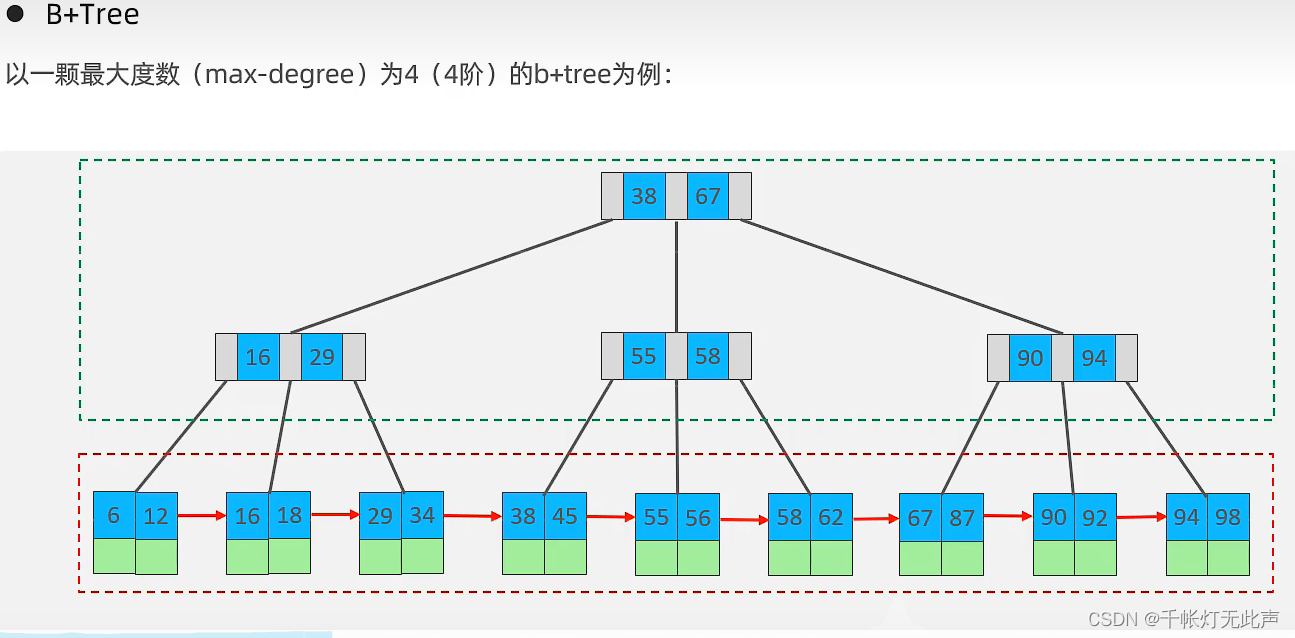
下面进行演示,B+ Tree Visualization (usfca.edu)
先准备一个5阶的B+Tree👇
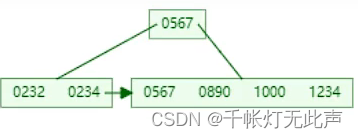
当我们插入890
(1)
(2)
中间元素567向上裂变时,叶子节点也会插入567(中间元素)
-------------------------
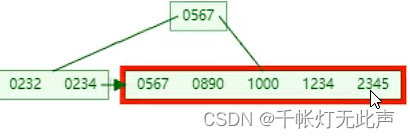
再举个例子,初始👇
插入2345
(1)
(2)
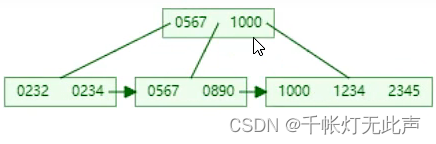
B+Tree与BTree区别👇
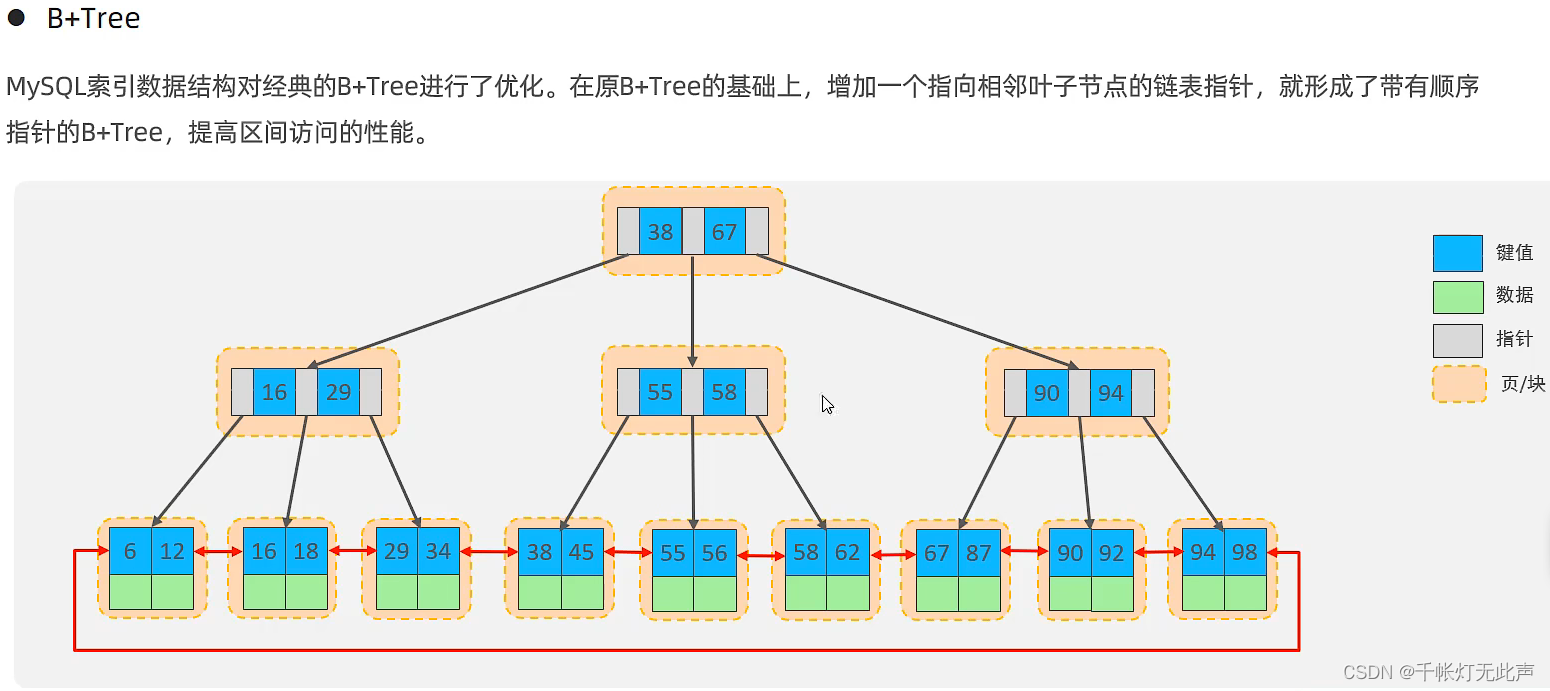
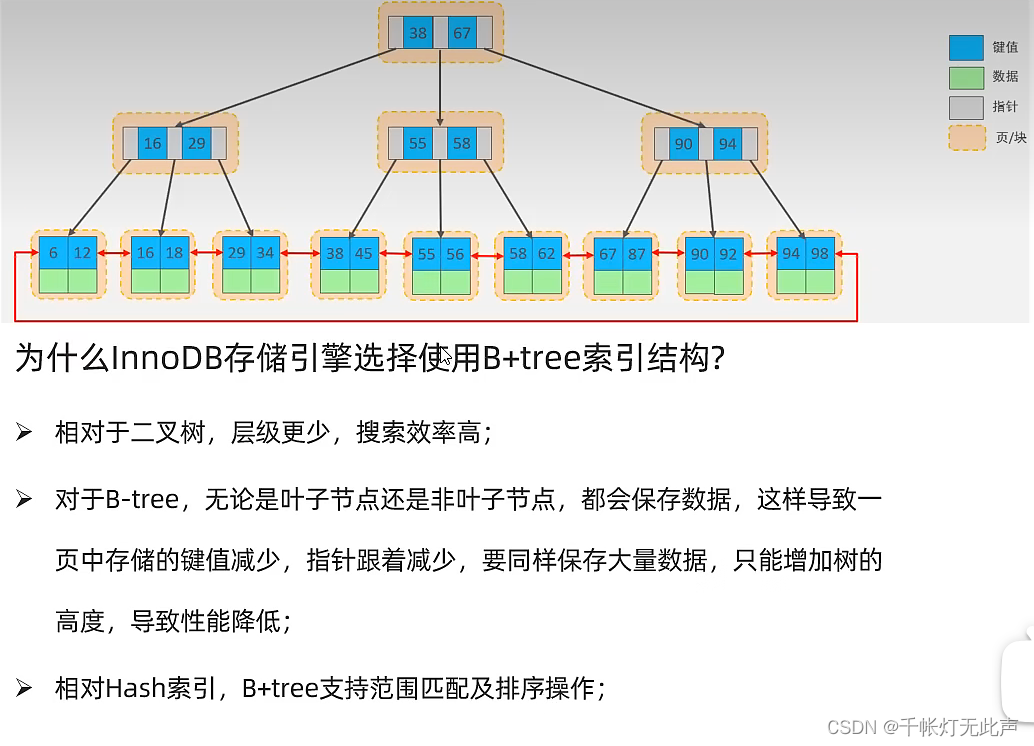
再看看Mysql中的B+Tree👇
叶子节点类似,双向循环链表。
注意,数据都存储在叶子节点
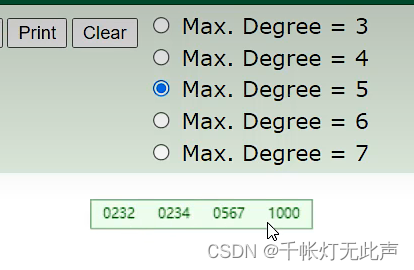
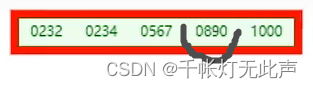
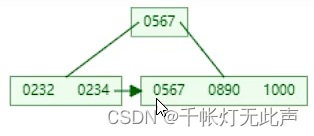

🐅结构 - hash
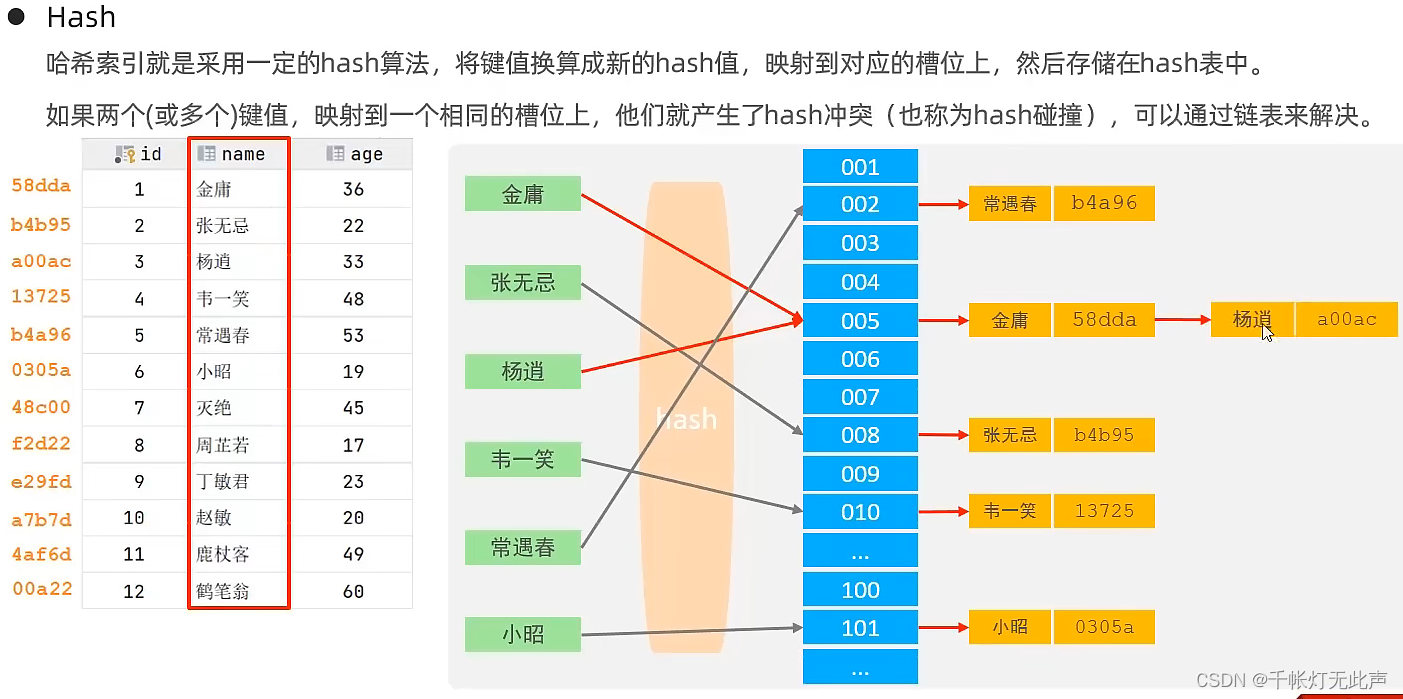

🐅索引 - 结构 - 面试题
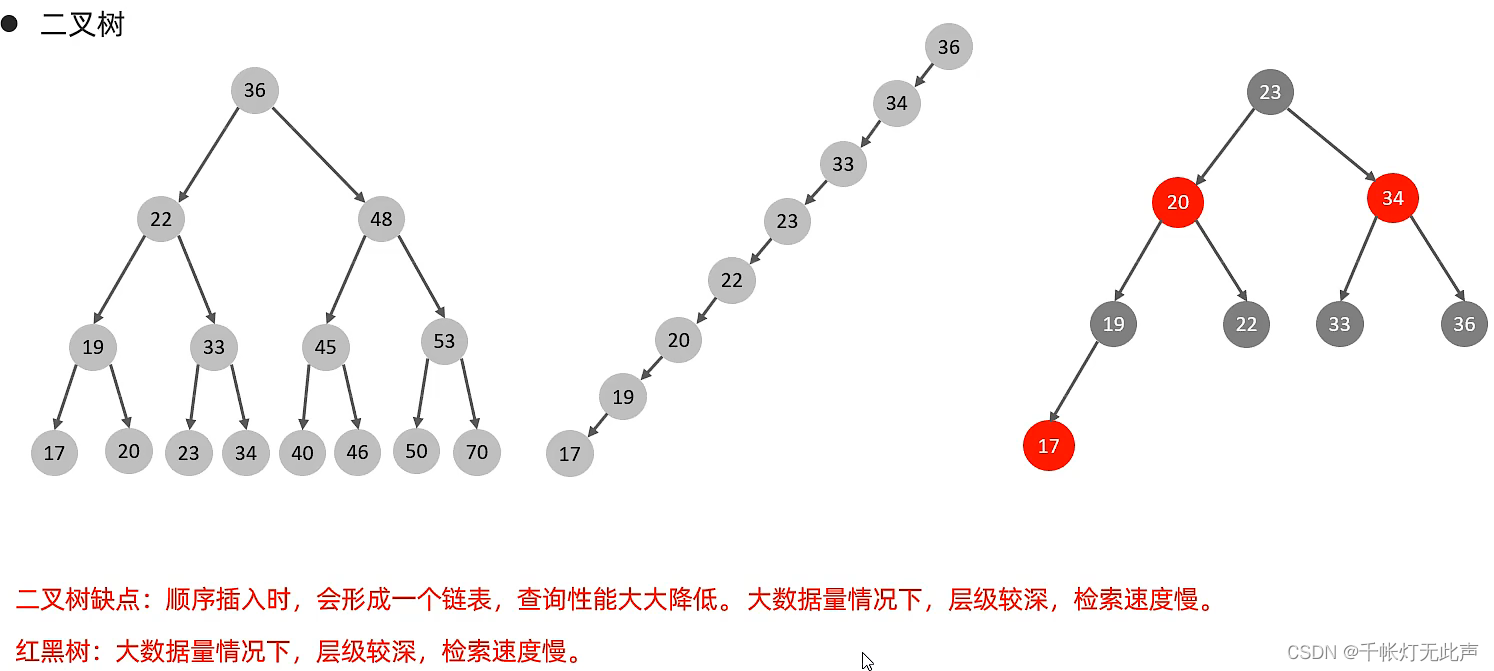
(1)为什么InnoDB存储引擎采取B+Tree,而不采取二叉树,红黑树?
因为二叉树在,顺序插入时,会形成一条链表,搜索时性能极低,红黑树本质也是二叉树
而B+Tree在插入元素时,某一节点达到最大的key后,中间元素会向上分裂,所以层级更少,效率更高
(2)为什么也不采取BTree呢?
---------------------------- 分界线
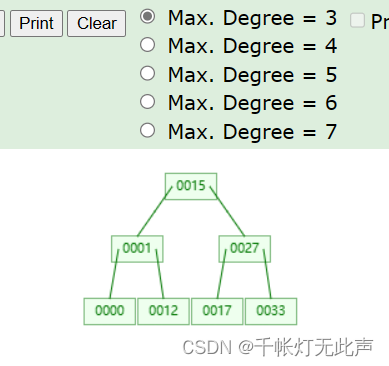
BTree可视化👇
B-Tree Visualization (usfca.edu)
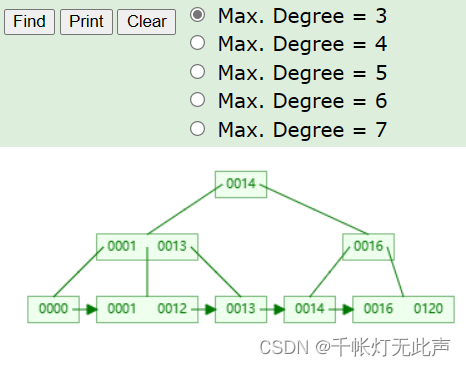
B+Tree可视化👇
B+ Tree Visualization (usfca.edu)
BTree与B+Tree区别👇
Difference between B tree and B+ tree - GeeksforGeeks
---------------------------- 分界线
这里作个区分,下面👇是B-Tree的,这个是B+Tree的👇
B-Tree和B+Tree的共同特点:
with the lowest value on the left and the highest value on the right
区别:
B+ tree eliminates the drawback B-tree used for indexing by storing data pointers only at the leaf nodes of the tree(B+ 树只在树的叶节点存储数据指针,消除了 B 树用于索引的缺点)
换言之,B-Tree非叶子节点也存放数据,但非叶子节点只起到了索引的效果(叶子节点会存放所有数据),而每个节点只能存放一页的数据,也就是16K,相同数据量,B-Tree的层级会更深
另外,B+Tree查找数据,只需要在叶子节点查找,搜索效率更稳定
补充,B+Tree叶子节点,会形成双向循环链表,便于范围搜索和排序
(3)为什么不用hash索引?
hash只支持等值匹配 (=, in),不支持范围匹配 (>=, <) 和排序操作
🐅分类
InnoDB存储引擎中,根据索引的存储形式👇可分为:
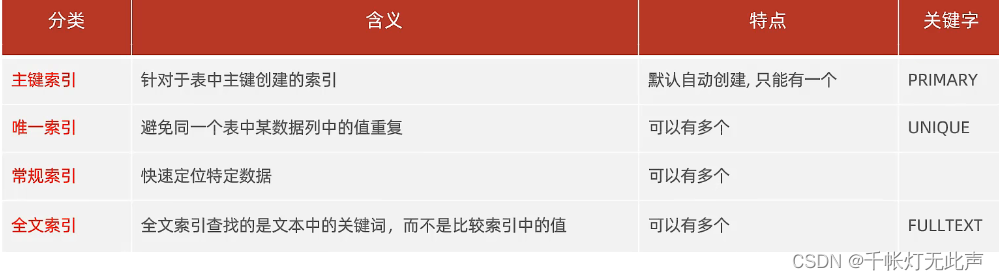
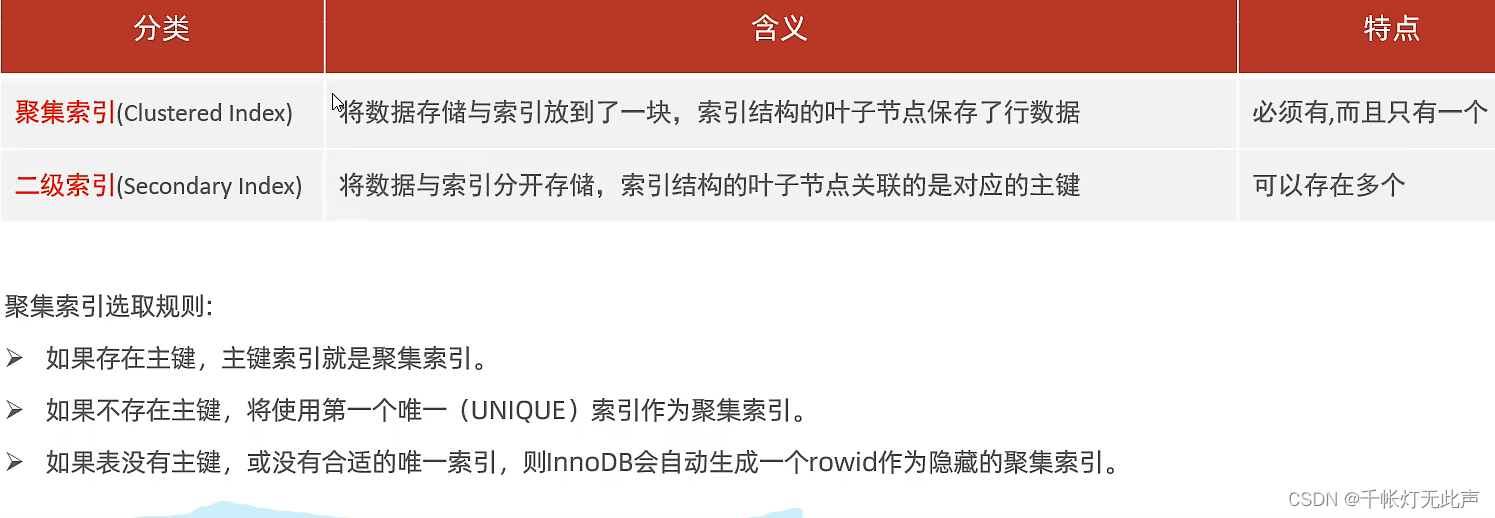
对聚集索引和二级索引的区分
有主键的话,主键索引就是聚集索引,而聚集索引叶子节点,下面挂的row就是所在行的数据
而二级索引,叶节点下挂的值,是所在行的 id 值
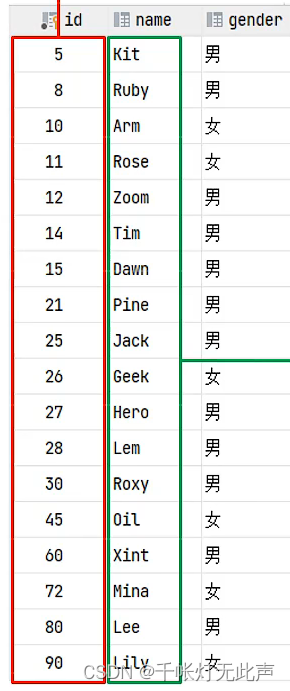
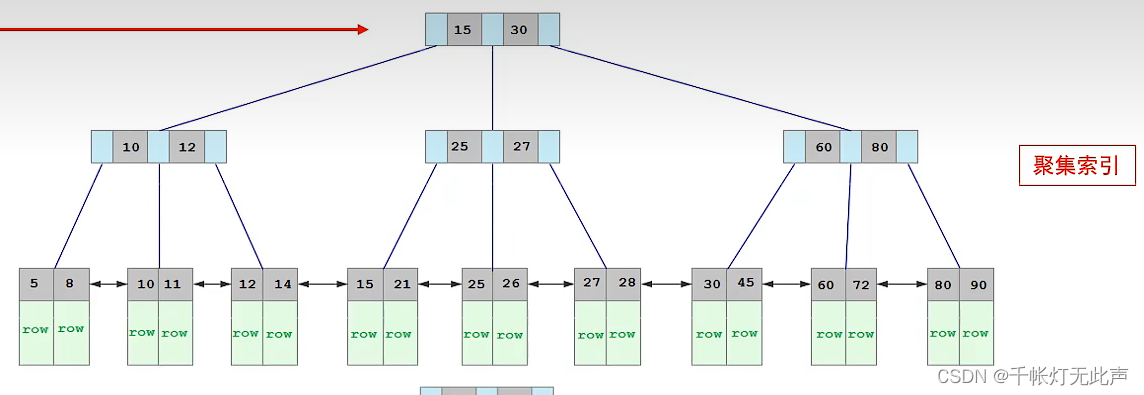
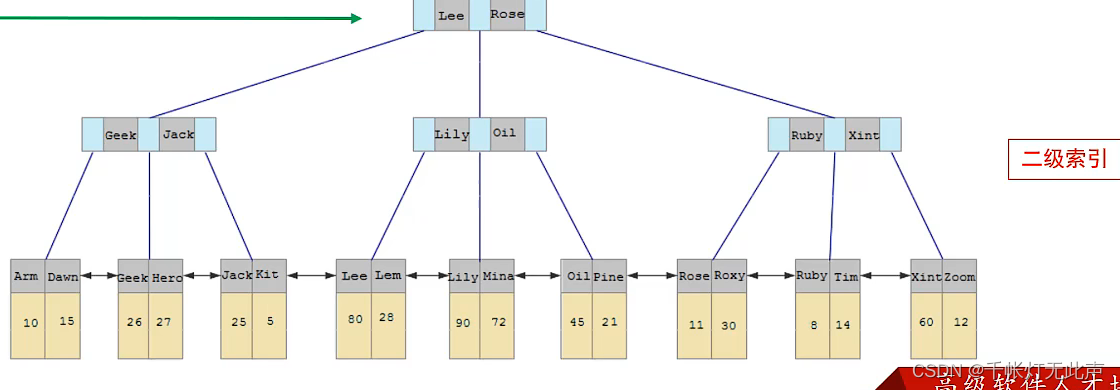
举例说明如何查询👇
select * from user where name = 'Arm';(1)先从二级索引开始,逐个对比,直到找到Arm,此时我们需要查找的是 *,需要输出整行的数据,根据Arm得到了这一行的 id 10
(2)然后到聚集索引,逐个对比,定位到10后,就拿到了这一行的数据👆
(1)和(2)的整个过程叫 --> “回表查询”
回表查询:先从二级索引找到对应的主键值,再根据主键值从聚集索引中,得到这一行的行数据
再次强调,聚集索引叶节点 --> 行数据,二级索引叶节点 --> id
🐅面试题
(1)以下SQL语句,哪个执行效率更高,为什么
备注:id为主键,name字段创建的有索引
1,根据 id = 10,直接到聚集索引中对比,就能查到 * ,只需要扫描1次
2,但是根据 name,得先到二级索引得到 id,再到聚集索引扫描1次,也就是需要回表查询
(2)InnoDB主键索引 B+Tree的高度为多少
InnoDB指针占用6字节空间,主键如果为int,占用4字节;如果为bigint,占用8字节
(我们假设主键为bigint)一个主键占用8字节
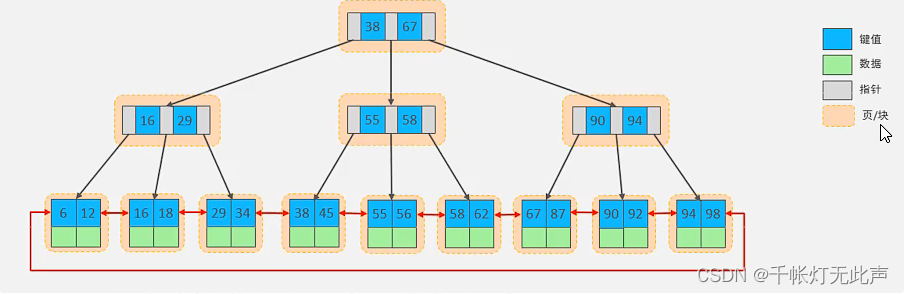

当树的高度 = 2
已知,指针比key多一个,假设主键n个
n * 8 + (n + 1) * 6 即key和指针所占用的总空间,又1页的大小16k,1k = 1024字节
n * 8 + (n + 1) * 6 = 16 * 1024,所以n ≈ 1170
因为一个节点放在磁盘上,最多存放1页的数据
所以一个节点,最多存放1170个key,1171个指针,而每个指针都指向一个子节点
所以有1171个叶节点,每个叶节点占用1页,也就是,高度为2的树,最多存储1171页的数据
注意,B+Tree非叶子节点是不存储数据的
1页16k,16(k) * 1171(页) = 18736k的数据,因为1行1k的数据,也就是18736行
当高度为3:高度为2时,1171个叶节点,而每个叶节点可以存放1171个指针,
所以 1171 * 1171 * 16 约等于 2200万 条记录
也就是2200万条记录,InnoDB存储引擎中,树的高度也才3层
如果数据量再大,还可考虑分库分表
🐅语法
下面的表需要手动创建,这里是代码👇
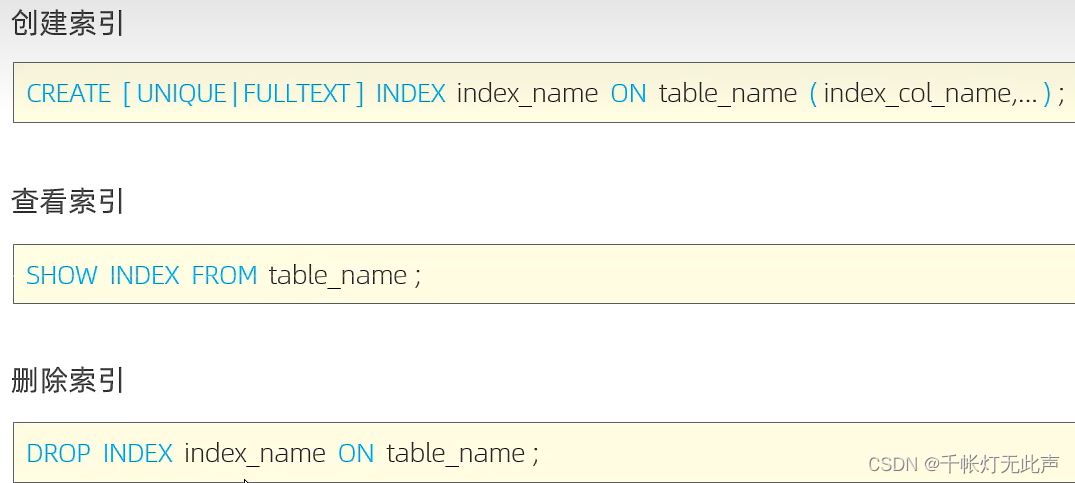
敲了一个小时.....可恨的是没有源码
create database itcast;
use itcast; #注意先打开虚拟机上CentOS
create table tb_user(
id int primary key auto_increment comment '主键ID',
name varchar(10) default null comment '姓名',
phone char(11) default null comment '手机号',
email varchar(50) check (email like '%@%'), #固定格式...@...
profession varchar(10),
age int default null comment '年龄',
gender char(1) default null comment '1: 男 , 2: 女',
status tinyint unsigned default '1' comment '状态',
createtime datetime
) comment '员工表';
insert into tb_user
values (1, '吕布', 17799990000, 'lvbu666@163.com', '软件工程', 23, '1', 6, '2001-02-02 00:00:00'),
(2, '曹操', 17799990001, 'caocao666@qq.com', '通讯工程', 33, '1', 0, '2001-03-05 00:00:00'),
(3, '赵云', 17799990002, '17799990@139.com', '英语', 34, '1', 2, '2002-03-02 00:00:00'),
(4, '孙悟空', 17799990003, '17799990@sina.com', '工程造价', 54, '1', 0, '2001-07-02 00:00:00'),
(5, '花木兰', 17799990004, '19980729@sina.com', '软件工程', 23, '2', 1, '2001-04-22 00:00:00'),
(6, '大乔', 17799990005, 'daqiao666@sina.com', '舞蹈', 22, '2', 0, '2001-02-07 00:00:00'),
(7, '露娜', 17799990006, 'luna_love@sina.com', '应用数学', 24, '2', 0, '2001-08-02 00:00:00'),
(8, '程咬金', 17799990007, 'chengyaojin@163.com', '化工', 38, '1', 5, '2001-05-23 00:00:00'),
(9, '项羽', 17799990008, 'xiaoyu666@qq.com', '金属材料', 43, '1', 0, '2001-09-18 00:00:00'),
(10, '白起', 17799990009, 'baiqi666@sina.com', '机械工程及其自动化', 27, '1', 2, '2001-08-16 00:00:00'),
(11, '韩信', 17799990010, 'hanxin520@163.com', '无机非金属材料工程', 27, '1', 0, '2001-06-12 00:00:00'),
(12, '荆轲', 17799990011, 'jinke123@163.com', '会计', 29, '1', 0, '2001-05-11 00:00:00'),
(13, '兰陵王', 17799990012, 'lvbu666@163.com', '工程造价', 44, '1', 1, '2001-04-10 00:00:00'),
(14, '狂铁', 17799990013, 'lvbu666@163.com', '应用数学', 43, '1', 2, '2001-02-12 00:00:00'),
(15, '貂蝉', 17799990014, 'lvbu666@126.com', '软件工程', 40, '2', 3, '2001-01-30 00:00:00'),
(16, '妲己', 17799990015, 'lvbu666@163.com', '软件工程', 31, '2', 0, '2001-05-03 00:00:00'),
(17, '芈月', 17799990016, 'lvbu666@163.com', '工业经济', 35, '2', 0, '2000-08-08 00:00:00'),
(18, '嬴政', 17799990017, 'lvbu666@163.com', '化工', 38, '1', 1, '2001-03-12 00:00:00'),
(19, '狄仁杰', 17799990018, 'lvbu666@126.com', '国际贸易', 30, '1', 0, '2007-08-15 00:00:00'),
(20, '安琪拉', 17799990019, 'lvbu666@163.com', '城市规划', 51, '2', 0, '2001-04-12 00:00:00'),
(21, '典韦', 17799990020, 'lvbu666@163.com', '城市规划', 52, '1', 2, '2000-07-18 00:00:00'),
(22, '廉颇', 17799990021, 'lvbu666@139.com', '土木工程', 19, '1', 3, '2002-08-10 00:00:00'),
(23, '后裔', 17799990022, 'lvbu666@163.com', '城市园林', 20, '1', 0, '2002-5-26 00:00:00'),
(24, '姜子牙', 17799990023, 'lvbu666@139.com', '工程造价', 29, '1', 4, '2003-02-02 00:00:00');
use itcast;
show index from tb_user;
select * from tb_user;然后finalshell链接上VMware的CentOS的Linux
在finalshell中输入👇
mysql -u root -p;
********
use itcast;
show tables;
select * from tb_user;
注意插入后,还需要更新,否则show index后,cardinality显示的一直是0
analyze table tb_user;
show index from tb_user\G;
create index idx_user_name on tb_user(name);
create unique index idx_user_phone on tb_user(phone);
create index idx_user_pro_age_sta on tb_user(profession,age,status);
create index idx_user_eamil on tb_user(eamil);
drop index idx_user_eamil on tb_user;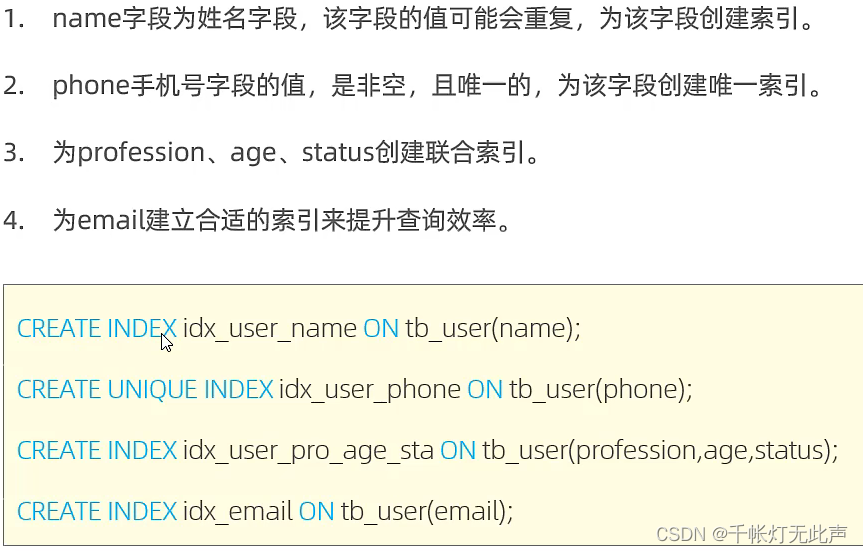
学到这,已经有点懵了,索引是啥? --> 提高数据库查询性能的数据结构
🐻性能分析 - 查看执行频次
--> 要做SQL优化,首先得进行SQL性能分析
--> 而SQL优化中,优化的主要部分是select(查询语句)
--> 而优化查询语句时,索引优化占据了主导地位
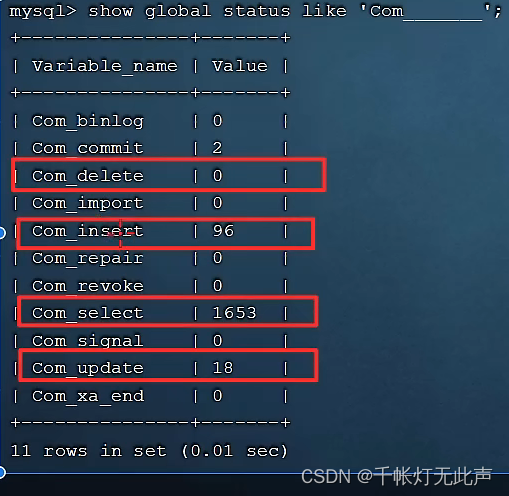
global是全局,session是当前会话
每查询一次,Com_select | 300,查询次数这里就会多一次,通过这个语句,可以看到当前使用次数最多的是select --> 为后续优化提供依据

🐻性能分析 - 慢查询日志
这一节很麻烦!建议视频和文章一起看!19. 进阶-索引-性能分析-慢查询日志_哔哩哔哩_bilibili
当Mysql中出现慢查询到的SQL时,就需要我们去优化

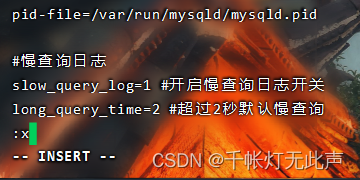
一,慢查询配置👇
此时slow_query_log 是关闭的👇
这里涉及到Linux的 vi 编辑器👇
回车,按G切换到末尾,按 i 切换到插入
注意是输入完 =2后,按"esc"退出插入模式,然后回车
输入 ":x"(Vim编辑器的保存并退出命令),回车
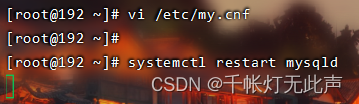
重启👇
再次打开左侧标签,再次执行👇


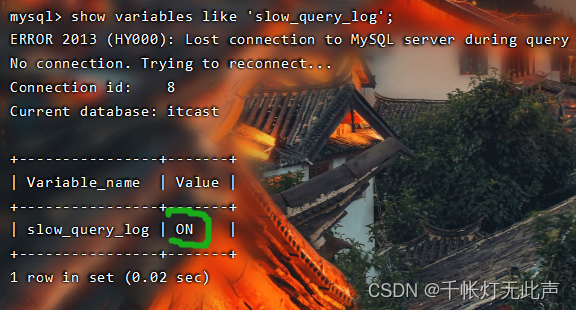
二,慢查询查看👇
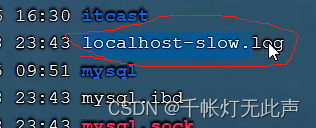
我们需要看到这个文件名
如果没有,输入这个👇
可以看到,第3行右边那个value,就是你要 cat 的
版本8.0.26,端口3306
tail -f 监视MySQL慢查询日志文件的更新,并将新内容输出到终端👇
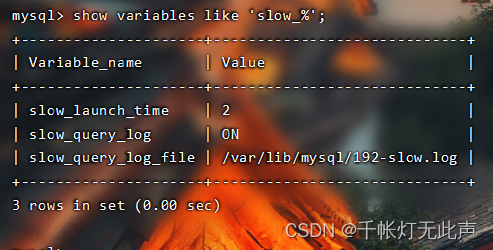


不超过2秒的话,右边root处慢日志查询那里,就不会显示👇
三,导入1000万数据👇
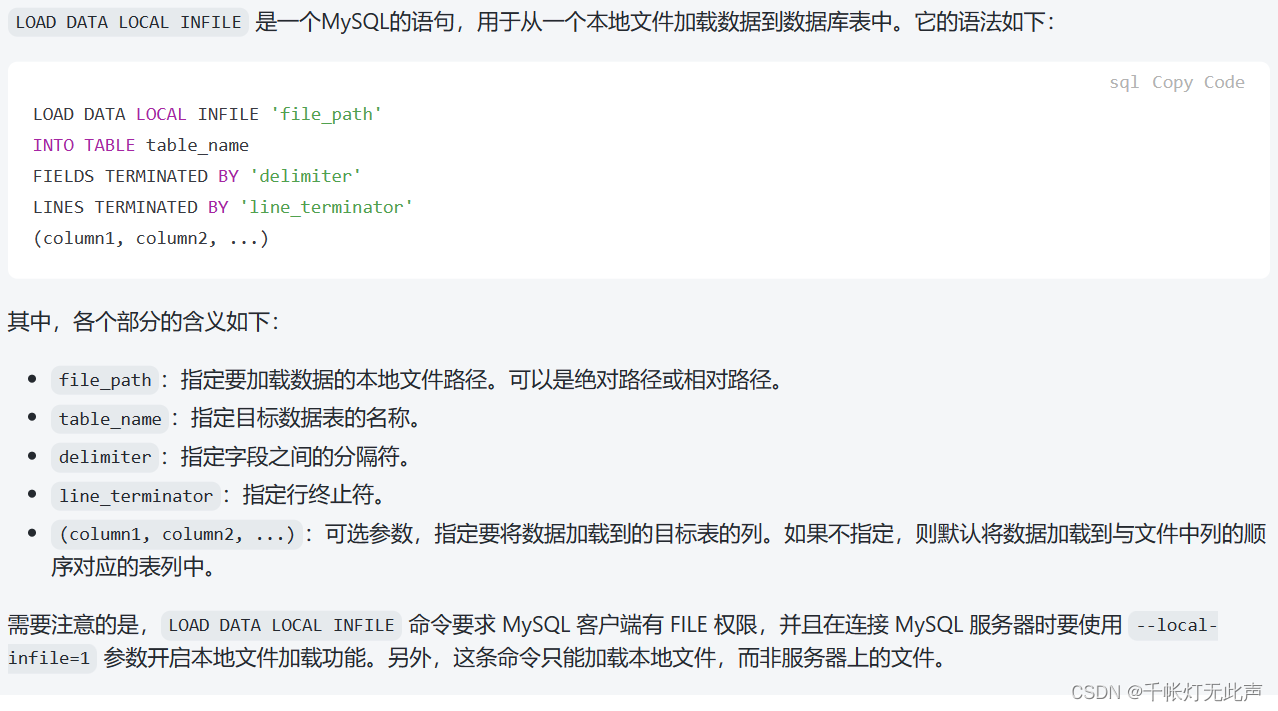
下一步,需要从本地导入1000万的数据到Mysql
(1)先建表
CREATE TABLE `tb_sku` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`sn` varchar(100) NOT NULL COMMENT '商品条码',
`name` varchar(200) NOT NULL COMMENT 'SKU名称',
`price` int(20) NOT NULL COMMENT '价格(分)',
`num` int(10) NOT NULL COMMENT '库存数量',
`alert_num` int(11) DEFAULT NULL COMMENT '库存预警数量',
`image` varchar(200) DEFAULT NULL COMMENT '商品图片',
`images` varchar(2000) DEFAULT NULL COMMENT '商品图片列表',
`weight` int(11) DEFAULT NULL COMMENT '重量(克)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`category_name` varchar(200) DEFAULT NULL COMMENT '类目名称',
`brand_name` varchar(100) DEFAULT NULL COMMENT '品牌名称',
`spec` varchar(200) DEFAULT NULL COMMENT '规格',
`sale_num` int(11) DEFAULT '0' COMMENT '销量',
`comment_num` int(11) DEFAULT '0' COMMENT '评论数',
`status` char(1) DEFAULT '1' COMMENT '商品状态 1-正常,2-下架,3-删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
(2)再插入
先把Windows解压后的5个文件上传到Linux👇
回车
输入重启mysql
然而...还是无法导入....无语了....
按这个再来一下
【数据分析】MySQL之不能导入本地文件“Loading local data is disable;” - 新治 - 博客园 (cnblogs.com)
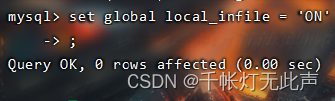
搞定!成功导入,修改ON后不要重启,直接load语句,但是重启完又会恢复OFF
但是....
最后200万数据死活插不进去,应该是内存满了
耗时12秒,属于慢查询了



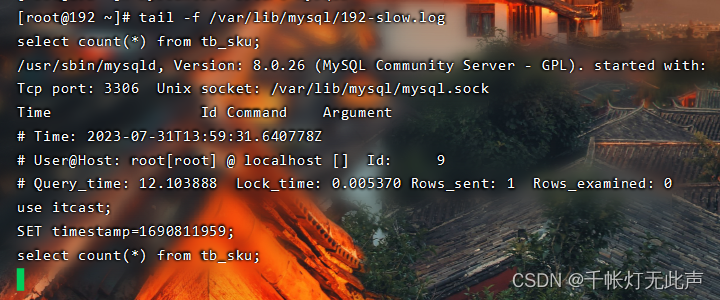
四,再次查询👇
接下来,再次用 tail -f 慢查询
成功记录!
那么过一段时间,来看慢查询日志,就知道哪些SQL语句查询效率低,进而优化它
ฅʕ•̫͡•ʔฅ关于[root@192~] 和 mysql>
[root@192~]是Linux系统中以root用户身份登录到主机时的命令提示符
mysql>是MySQL数据库命令行客户端的命令提示符(1)root
执行系统级别的操作和管理任务,如修改系统配置文件、安装软件包等。root用户具有最高的权限,能够对系统进行全面的管理
(2)mysql
通过命令行或终端登录到MySQL服务器时,会看到
mysql>提示符。在这个提示符下,你可以执行与MySQL相关的命令,如创建数据库、执行查询语句、修改表结构


















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











