







 这篇博客详细介绍了如何在本地环境中搭建并创建一个基本的Storm程序。通过使用Maven创建hello_storm项目,然后将App.java重命名为HelloTopology.java,并在此文件中编写包含spout和bolt的静态类,简化了Example中的TestWordSpout,移除了日志代码并调整了私有变量的命名约定。
这篇博客详细介绍了如何在本地环境中搭建并创建一个基本的Storm程序。通过使用Maven创建hello_storm项目,然后将App.java重命名为HelloTopology.java,并在此文件中编写包含spout和bolt的静态类,简化了Example中的TestWordSpout,移除了日志代码并调整了私有变量的命名约定。
本文将在本地开发环境创建一个storm程序,力求简单。
首先用mvn创建一个简单的工程hello_storm
mvn archetype:generate -DgroupId=org.csfreebird -DartifactId=hello_storm -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false编辑pom.xml,添加dependency
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.csfreebird</groupId>
<artifactId>hello_storm</artifactId>
<version>0.9.5</version>
<packaging>jar</packaging>
<name>hello_storm</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${project.version}</version>
<!-- keep storm out of the jar-with-dependencies -->
<scope>provided</scope>
</dependency>
</dependencies>
</project>provided 表示storm-core的jar包只作为编译和测试时使用,在集群环境下运行时完全依赖集群环境的storm-core的jar包。
然后重命名App.java为HelloTopology.java文件,开始编码。模仿之前的Example, 这里将所有的spout/bolt类都作为静态类定义,就放在HelloTopology.java文件。
功能如下
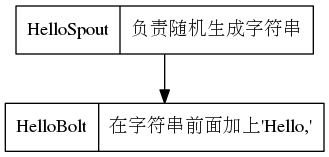
编写HelloTopology.java代码,spout代码来自于TestWordSpout,去掉了log的代码,改变了_引导的成员变量命名方法
package org.csfreebird;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.testing.TestWordSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import backtype.storm.spout.SpoutOutputCollector;
import java.util.Map;
import java.util.TreeMap;
import java.util.Random;
public class HelloTopology {
public static class HelloSpout extends BaseRichSpout {
boolean isDistributed;
SpoutOutputCollector collector;
public HelloSpout() {
this(true);
}
public HelloSpout(boolean isDistributed) {
this.isDistributed = isDistributed;
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
public void close() {
}
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"china", "usa", "japan", "russia", "england"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
this.collector.emit(new Values(word));
}
public void ack(Object msgId) {
}
public void fail(Object msgId) {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
if(!this.isDistributed) {
Map<String, Object> ret = new TreeMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 1);
return ret;
} else {
return null;
}
}
}
public static class HelloBolt extends BaseRichBolt {
OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
this.collector.emit(tuple, new Values("hello," + tuple.getString(0)));
this.collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("a", new HelloSpout(), 10);
builder.setBolt("b", new HelloBolt(), 5).shuffleGrouping("a");
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
String test_id = "hello_test";
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(test_id, conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(test_id);
cluster.shutdown();
}
}
}
编译成功
mvn clean compile为了能够在本地模式运行,需要在pom.xml中添加如下:
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>${storm.topology}</mainClass>
</configuration>
</plugin>
</plugins>
</build>然后运行命令
mvn compile exec:java -Dstorm.topology=org.csfreebird.HelloTopology 
















 2163
2163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









