







1、Spark的左外连接解决方案之不使用letfOutJoin()
import org.apache.spark.{SparkConf, SparkContext}
object LeftOutJoinTest {
def main(args: Array[String]): Unit = {
//连接SparkMaster
val conf = new SparkConf().setAppName("Chenjie's first spark App").setMaster("local")
val sc = new SparkContext(conf)
//从HDFS中读取输入文件并创建RDD
val users = sc.textFile("hdfs://pc1:9000/input/users.txt")
val user_map = users.map(line=>Tuple2(line.split("\t")(0),Tuple2("L",line.split("\t")(1))))
val transactions = sc.textFile("hdfs://pc1:9000/input/transactions.txt")
val transaction_map = transactions.map(line=>Tuple2(line.split("\t")(2),Tuple2("P",line.split("\t")(1))))
val all = transaction_map.union(user_map)
val groupedRDD = all.groupByKey()
val productLocationsRDD = groupedRDD.flatMap{tuple=>
val pairs = tuple._2
var location = "UNKOWN"
val products = new scala.collection.mutable.ArrayBuffer[String]()
pairs.foreach{t2=>
if(t2._1.equals("L")){
location = t2._2
}
else{
products.+=(t2._2)
}
}
val kvlist = new scala.collection.mutable.ArrayBuffer[Tuple2[String,String]]()
for(product <- products){
kvlist.+=((new Tuple2(product,location)))
}
kvlist
}
productLocationsRDD.distinct().groupByKey().map{pair=>
val key = pair._1
val locations = pair._2
val length = locations.size
Tuple2(key,Tuple2(locations,length))
}.saveAsTextFile("hdfs://pc1:9000/output/leftoutjoin_1")
}
}
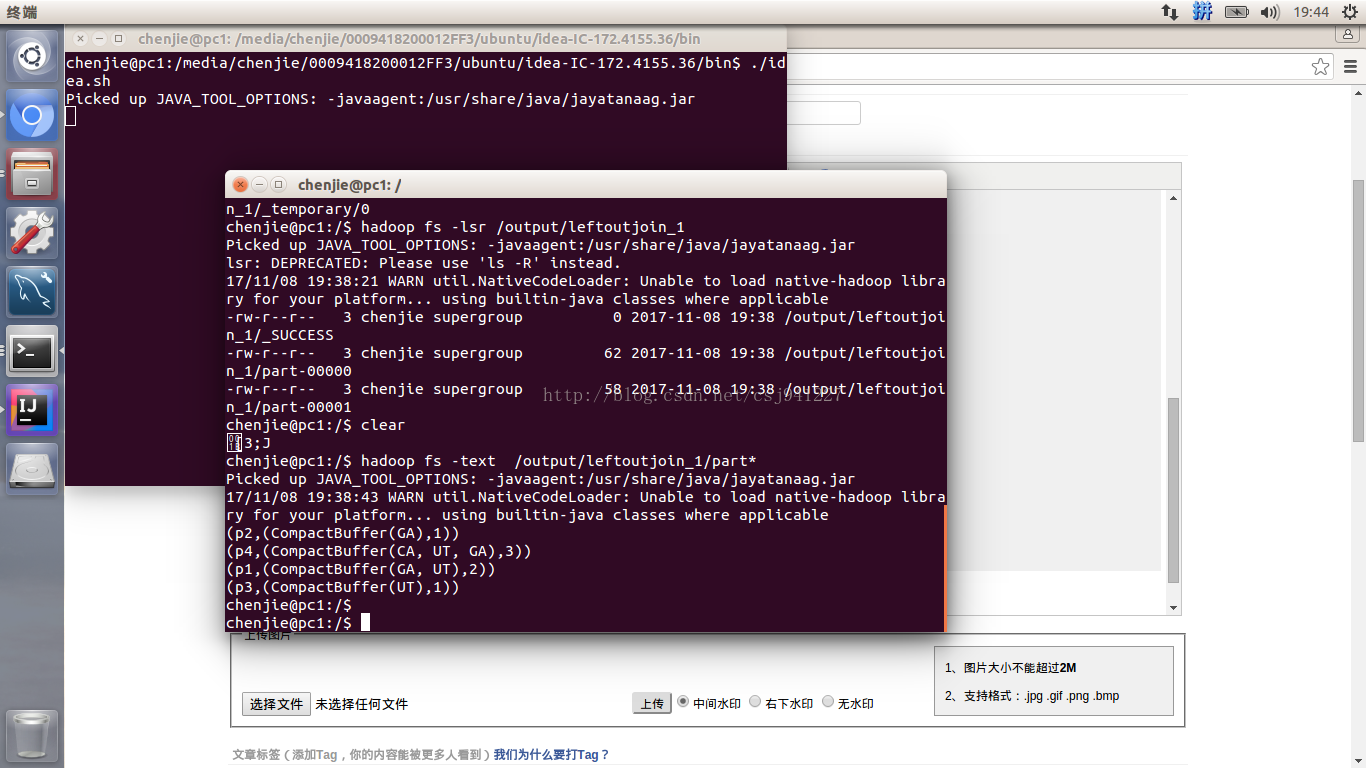
运行结果:
2、Spark的左外连接解决方案之使用letfOutJoin():避免标志位等麻烦
import org.apache.spark.{SparkConf, SparkContext}
object LeftOutJoinTest {
def main(args: Array[String]): Unit = {
//连接SparkMaster
val conf = new SparkConf().setAppName("Chenjie's first spark App").setMaster("local")
val sc = new SparkContext(conf)
//从HDFS中读取输入文件并创建RDD
val users = sc.textFile("hdfs://pc1:9000/input/users.txt")
val user_map = users.map(line=>Tuple2(line.split("\t")(0),line.split("\t")(1)))
val transactions = sc.textFile("hdfs://pc1:9000/input/transactions.txt")
val transaction_map = transactions.map(line=>Tuple2(line.split("\t")(2),line.split("\t")(1)))
val joined = transaction_map.leftOuterJoin(user_map)
joined.map(line=>Tuple2(line._2._1,line._2._2.get)).distinct().groupByKey().map{pair=>
val key = pair._1
val locations = pair._2
val length = locations.size
Tuple2(key,Tuple2(locations,length))
}.saveAsTextFile("hdfs://pc1:9000/output/leftoutjoin_2")
}
}
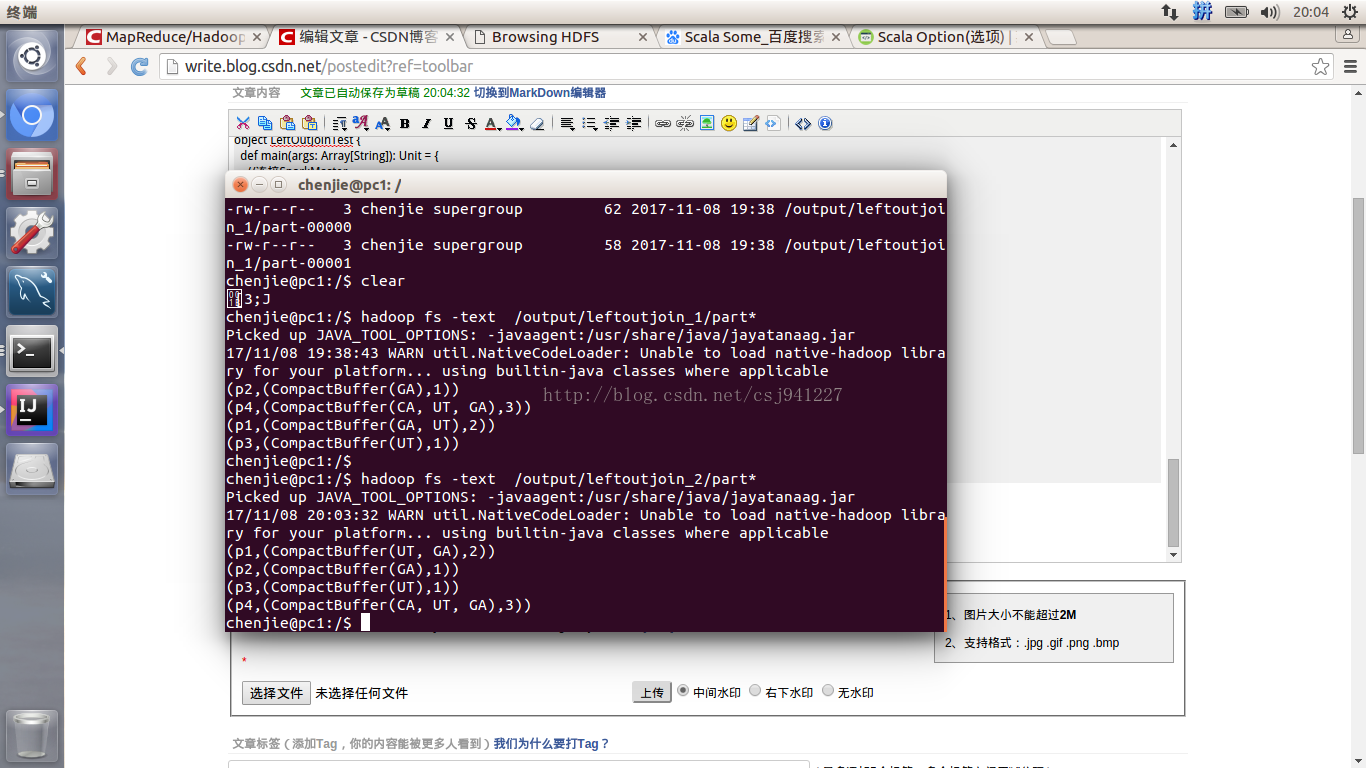














 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









