







作者:nerfing
链接:http://www.zhihu.com/question/26901116/answer/39253382
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:http://www.zhihu.com/question/26901116/answer/39253382
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
我认为整理文献的主要目的就是:能够在任何条件下,
快速找到所需信息。任何好用的软件,都不如大批量多批次的文献阅读。
我的思路是: 轻整理,重搜索。轻整理,是指不对文献分类,或者只是对文献简单分类。重搜索,是指利用不同的搜索工具,快速定位到我需要的文献。我认为在现在搜索技术已经很强大的情况下,如果利用笔记等手段整理,反而容易造成条条框框,在对于一篇文献关注太长的时间,不利于提高效率。 在日常使用中, 除了在文献PDF上直接标注,我很少用其他的软件去记录我看过的文献。因为除了文献本身,其他还有什么载体能够那么直接方便地记录呢?所以整理文献问题就成了: 如何快速找出那篇有我笔记的PDF文献。以此为目的, 我建立了一套以文献PDF云同步为基础,辅以大量搜索工具的文献整理方案。
其实做过科研工作的人都会发现,其实真正需要把一篇文献从头到尾读完的情况是很少的。在大多数情况下,我们需要的其实是 大批量多轮次地阅读文献,因为在一个项目的不同阶段,哪怕是同一篇文献,所关注的点也是不一样的。 如果在项目初期,就对所有的文献,都投入同样的时间,阅读同样的深度,势必会浪费大量时间和做无用功。我曾经也走过文献整理的弯路,每阅读一篇文献,都会在Onenote上建立一个条目,按照文献题目,创新点,实验过程,个人感想等分别填空。但是文献读的多了之后,这个方法我觉得效率不高,用的频率也越来越少了。
我现在的主要方法是:以Mendeley建立电子文献索引为主,并以云端同步PDF文献为主要储存手段,通过Everything,Google Scholar,桌面搜索软件,Onenote笔记等多种搜索手段,快速找到自己所要的信息。
==================干货开始=====================
**重搜索部分**
在新项目(写一篇综述,开始一个新课题或者完成一份大作业)开始之前,我会在Mendeley中根据不同项目,建立一个新文件夹。
<img data-rawheight="1080" data-rawwidth="1807" src="https://pic2.zhimg.com/fc0350d25e20b73a00f2b9e6e8a116e5_b.jpg" class="origin_image zh-lightbox-thumb" width="1807" data-original="https://pic2.zhimg.com/fc0350d25e20b73a00f2b9e6e8a116e5_r.jpg">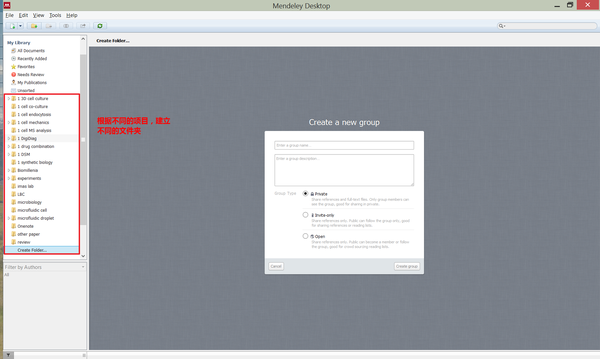
一个项目刚开始的时候,文件夹中没有文献,就需要先建立一份本地的文献原始积累。我习惯在Web of Science上根据关键词去找所需要的文献。
比如我现在想看一下微流控单细胞测序(microfluidic single cell sequencing)最近的进展时,就去WoS搜:
<img data-rawheight="950" data-rawwidth="1741" src="https://pic2.zhimg.com/086a4d1832dfe8101e0ae34fbed41f01_b.jpg" class="origin_image zh-lightbox-thumb" width="1741" data-original="https://pic2.zhimg.com/086a4d1832dfe8101e0ae34fbed41f01_r.jpg">总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。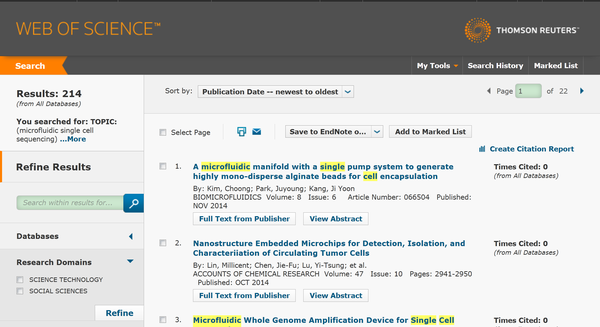 总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
其他回答中提到了用Endnote。我用Mendeley而不是Endnote做文献索引,主要是因为:Mendeley是我用过所有的文献整理软件中,提取文章题目,发表年份和期刊等信息最准确和方便的软件。看到一篇有意思的文章,我只需要往Mendeley中一拖,它就会帮我自动提取文献信息建立条目,并将文件拷贝到指定文件夹中。其他的软件,要么是提取文献条目的准确度不高,要么就是建立文献条目非常麻烦,需要花大量的时间去建立条目,大大降低文献阅读效率。
我又将这个Mendeley的文件夹中所有文献用dropbox同步。之后我要看文献时,只从这个文件夹中打开文献。这样做的好处就是,把所有的文献和笔记信息全部集中化了,不会造成信息碎片。
<img data-rawheight="1080" data-rawwidth="1798" src="https://pic2.zhimg.com/1ca768ce7211c9b1244a453f923410a9_b.jpg" class="origin_image zh-lightbox-thumb" width="1798" data-original="https://pic2.zhimg.com/1ca768ce7211c9b1244a453f923410a9_r.jpg">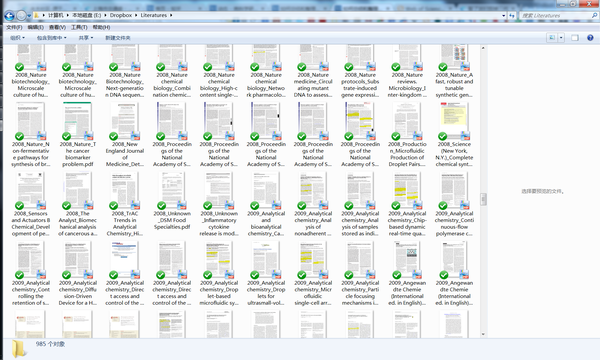
做笔记我也只在PDF上做,这样就不用另外开一个软件写笔记,并可以对自己感兴趣的信息直接标注,实现信息最大程度集中化。哪怕打印了纸版的文献,我在看完后也会把纸版上的笔记全部在PDF上标注,避免信息碎片化。
<img data-rawheight="910" data-rawwidth="1503" src="https://pic3.zhimg.com/a38091093da1705e57606cbc24171ab6_b.jpg" class="origin_image zh-lightbox-thumb" width="1503" data-original="https://pic3.zhimg.com/a38091093da1705e57606cbc24171ab6_r.jpg">
我看一篇文献,除了一些世界上的顶尖超级大牛,一般记不住作者的名字,但是我一般会对文章发表年份和所在期刊有很深的印象。而且一般题目又提供了文章中最主要的信息。所以我设置Mendeley自动根据文献的三个强信息: 发表年,发表期刊,和文章题目自动重命名,并结合everything,在本地实现文献的第一重搜索。
如果搜索目标很明确,比如我现在想找一篇之前在Nature Drug Review上看过的关于drug combination的文章,由于关键词很明确,用Everything直接就从本地找到了,耗时不超过3秒。
<img data-rawheight="661" data-rawwidth="951" src="https://pic2.zhimg.com/3022aaf6fb26feb701a814455215a475_b.jpg" class="origin_image zh-lightbox-thumb" width="951" data-original="https://pic2.zhimg.com/3022aaf6fb26feb701a814455215a475_r.jpg">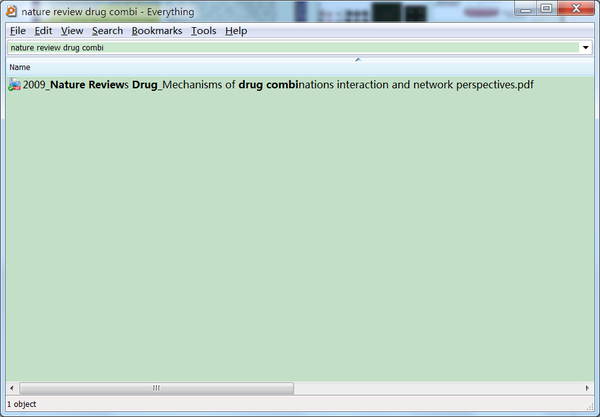
如果搜索目标不那么明确,比如题主说的,“总感觉有些文献读过就忘记了,想用的时候想不起来”;或者找找一些特定的问题,不确定本地文献有没有。这个时候我一般会把所有能想到的关键词输入,上Google Scholar搜索。
这个时候,可能会找到一些文献在本地是有的,那就可以根据文献名,用Everything快速在本地找到对应的文献。
<img data-rawheight="944" data-rawwidth="1760" src="https://pic4.zhimg.com/8e83868a7cd8d18c41102d025cc40093_b.jpg" class="origin_image zh-lightbox-thumb" width="1760" data-original="https://pic4.zhimg.com/8e83868a7cd8d18c41102d025cc40093_r.jpg">如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。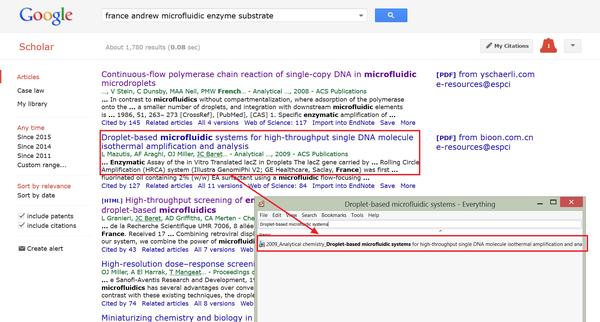 如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果想要搜索特定一句话,或者在写文章的时候想对一些说法进行佐证,就可以用Mendeley的搜索工具,
<img data-rawheight="1080" data-rawwidth="1797" src="https://pic1.zhimg.com/09a4e1babe351f41497883586454b940_b.jpg" class="origin_image zh-lightbox-thumb" width="1797" data-original="https://pic1.zhimg.com/09a4e1babe351f41497883586454b940_r.jpg">或者还是上Google Scholar。。。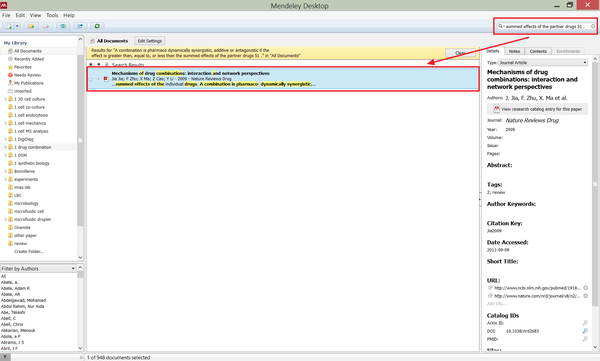 或者还是上Google Scholar。。。
或者还是上Google Scholar。。。
<img data-rawheight="951" data-rawwidth="1768" src="https://pic2.zhimg.com/1abd014e0b92442ae8a62b3c63e6ee65_b.jpg" class="origin_image zh-lightbox-thumb" width="1768" data-original="https://pic2.zhimg.com/1abd014e0b92442ae8a62b3c63e6ee65_r.jpg">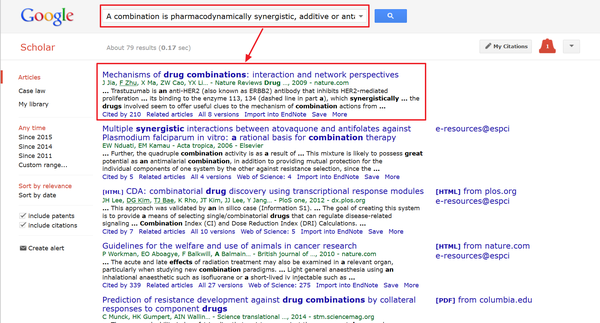
**轻整理部分**
之后随着时间的流逝,一个文件夹下的文献慢慢变多,这个时候就需要在Mendeley中建立子文件夹了(对于我来说,每个项目中前前后后需要阅读的文献大概在300篇左右),也就是传统意义上的整理。但是我不赞成把文献归类做的过细。对一个项目下简单分类,使每个子文件夹中的文献大概不超过50篇,再通过发表年份,期刊名,作者名等信息,也可以很容易找到所需的文章了。
但是我现在不会等文献很多了之后再去建立子文件夹,而是会在平时读文献的时候,根据一个项目下的不同问题,建立一些小的分类。在Mendeley中,同一篇文献是可以归属不同的文件夹的,所以在归文件夹的时候也不用那么纠结。
<img data-rawheight="1080" data-rawwidth="1807" src="https://pic3.zhimg.com/3169f44dc025aabdd98e0da52a2b217a_b.jpg" class="origin_image zh-lightbox-thumb" width="1807" data-original="https://pic3.zhimg.com/3169f44dc025aabdd98e0da52a2b217a_r.jpg">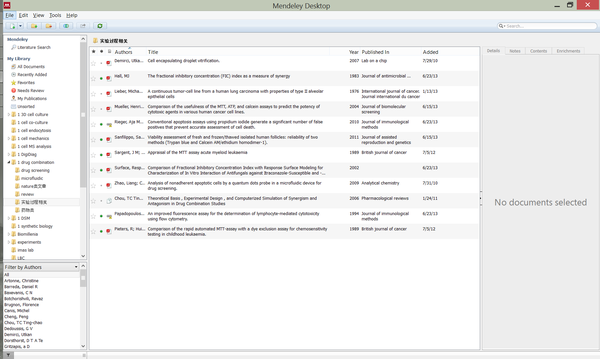
最后,我想说的是, 任何文献整理软件都不能代替人对文献的阅读,任何时候读文献中信息永远是第一位的。整理软件只能够帮助更加快速地找到所需的信息而已。
以上。
我的思路是: 轻整理,重搜索。轻整理,是指不对文献分类,或者只是对文献简单分类。重搜索,是指利用不同的搜索工具,快速定位到我需要的文献。我认为在现在搜索技术已经很强大的情况下,如果利用笔记等手段整理,反而容易造成条条框框,在对于一篇文献关注太长的时间,不利于提高效率。 在日常使用中, 除了在文献PDF上直接标注,我很少用其他的软件去记录我看过的文献。因为除了文献本身,其他还有什么载体能够那么直接方便地记录呢?所以整理文献问题就成了: 如何快速找出那篇有我笔记的PDF文献。以此为目的, 我建立了一套以文献PDF云同步为基础,辅以大量搜索工具的文献整理方案。
其实做过科研工作的人都会发现,其实真正需要把一篇文献从头到尾读完的情况是很少的。在大多数情况下,我们需要的其实是 大批量多轮次地阅读文献,因为在一个项目的不同阶段,哪怕是同一篇文献,所关注的点也是不一样的。 如果在项目初期,就对所有的文献,都投入同样的时间,阅读同样的深度,势必会浪费大量时间和做无用功。我曾经也走过文献整理的弯路,每阅读一篇文献,都会在Onenote上建立一个条目,按照文献题目,创新点,实验过程,个人感想等分别填空。但是文献读的多了之后,这个方法我觉得效率不高,用的频率也越来越少了。
我现在的主要方法是:以Mendeley建立电子文献索引为主,并以云端同步PDF文献为主要储存手段,通过Everything,Google Scholar,桌面搜索软件,Onenote笔记等多种搜索手段,快速找到自己所要的信息。
==================干货开始=====================
**重搜索部分**
在新项目(写一篇综述,开始一个新课题或者完成一份大作业)开始之前,我会在Mendeley中根据不同项目,建立一个新文件夹。
<img data-rawheight="1080" data-rawwidth="1807" src="https://pic2.zhimg.com/fc0350d25e20b73a00f2b9e6e8a116e5_b.jpg" class="origin_image zh-lightbox-thumb" width="1807" data-original="https://pic2.zhimg.com/fc0350d25e20b73a00f2b9e6e8a116e5_r.jpg">
一个项目刚开始的时候,文件夹中没有文献,就需要先建立一份本地的文献原始积累。我习惯在Web of Science上根据关键词去找所需要的文献。
比如我现在想看一下微流控单细胞测序(microfluidic single cell sequencing)最近的进展时,就去WoS搜:
<img data-rawheight="950" data-rawwidth="1741" src="https://pic2.zhimg.com/086a4d1832dfe8101e0ae34fbed41f01_b.jpg" class="origin_image zh-lightbox-thumb" width="1741" data-original="https://pic2.zhimg.com/086a4d1832dfe8101e0ae34fbed41f01_r.jpg">总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
其他回答中提到了用Endnote。我用Mendeley而不是Endnote做文献索引,主要是因为:Mendeley是我用过所有的文献整理软件中,提取文章题目,发表年份和期刊等信息最准确和方便的软件。看到一篇有意思的文章,我只需要往Mendeley中一拖,它就会帮我自动提取文献信息建立条目,并将文件拷贝到指定文件夹中。其他的软件,要么是提取文献条目的准确度不高,要么就是建立文献条目非常麻烦,需要花大量的时间去建立条目,大大降低文献阅读效率。
我又将这个Mendeley的文件夹中所有文献用dropbox同步。之后我要看文献时,只从这个文件夹中打开文献。这样做的好处就是,把所有的文献和笔记信息全部集中化了,不会造成信息碎片。
<img data-rawheight="1080" data-rawwidth="1798" src="https://pic2.zhimg.com/1ca768ce7211c9b1244a453f923410a9_b.jpg" class="origin_image zh-lightbox-thumb" width="1798" data-original="https://pic2.zhimg.com/1ca768ce7211c9b1244a453f923410a9_r.jpg">
做笔记我也只在PDF上做,这样就不用另外开一个软件写笔记,并可以对自己感兴趣的信息直接标注,实现信息最大程度集中化。哪怕打印了纸版的文献,我在看完后也会把纸版上的笔记全部在PDF上标注,避免信息碎片化。
<img data-rawheight="910" data-rawwidth="1503" src="https://pic3.zhimg.com/a38091093da1705e57606cbc24171ab6_b.jpg" class="origin_image zh-lightbox-thumb" width="1503" data-original="https://pic3.zhimg.com/a38091093da1705e57606cbc24171ab6_r.jpg">
我看一篇文献,除了一些世界上的顶尖超级大牛,一般记不住作者的名字,但是我一般会对文章发表年份和所在期刊有很深的印象。而且一般题目又提供了文章中最主要的信息。所以我设置Mendeley自动根据文献的三个强信息: 发表年,发表期刊,和文章题目自动重命名,并结合everything,在本地实现文献的第一重搜索。
如果搜索目标很明确,比如我现在想找一篇之前在Nature Drug Review上看过的关于drug combination的文章,由于关键词很明确,用Everything直接就从本地找到了,耗时不超过3秒。
<img data-rawheight="661" data-rawwidth="951" src="https://pic2.zhimg.com/3022aaf6fb26feb701a814455215a475_b.jpg" class="origin_image zh-lightbox-thumb" width="951" data-original="https://pic2.zhimg.com/3022aaf6fb26feb701a814455215a475_r.jpg">
如果搜索目标不那么明确,比如题主说的,“总感觉有些文献读过就忘记了,想用的时候想不起来”;或者找找一些特定的问题,不确定本地文献有没有。这个时候我一般会把所有能想到的关键词输入,上Google Scholar搜索。
这个时候,可能会找到一些文献在本地是有的,那就可以根据文献名,用Everything快速在本地找到对应的文献。
<img data-rawheight="944" data-rawwidth="1760" src="https://pic4.zhimg.com/8e83868a7cd8d18c41102d025cc40093_b.jpg" class="origin_image zh-lightbox-thumb" width="1760" data-original="https://pic4.zhimg.com/8e83868a7cd8d18c41102d025cc40093_r.jpg">如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果想要搜索特定一句话,或者在写文章的时候想对一些说法进行佐证,就可以用Mendeley的搜索工具,
<img data-rawheight="1080" data-rawwidth="1797" src="https://pic1.zhimg.com/09a4e1babe351f41497883586454b940_b.jpg" class="origin_image zh-lightbox-thumb" width="1797" data-original="https://pic1.zhimg.com/09a4e1babe351f41497883586454b940_r.jpg">或者还是上Google Scholar。。。
或者还是上Google Scholar。。。
<img data-rawheight="951" data-rawwidth="1768" src="https://pic2.zhimg.com/1abd014e0b92442ae8a62b3c63e6ee65_b.jpg" class="origin_image zh-lightbox-thumb" width="1768" data-original="https://pic2.zhimg.com/1abd014e0b92442ae8a62b3c63e6ee65_r.jpg">
**轻整理部分**
之后随着时间的流逝,一个文件夹下的文献慢慢变多,这个时候就需要在Mendeley中建立子文件夹了(对于我来说,每个项目中前前后后需要阅读的文献大概在300篇左右),也就是传统意义上的整理。但是我不赞成把文献归类做的过细。对一个项目下简单分类,使每个子文件夹中的文献大概不超过50篇,再通过发表年份,期刊名,作者名等信息,也可以很容易找到所需的文章了。
但是我现在不会等文献很多了之后再去建立子文件夹,而是会在平时读文献的时候,根据一个项目下的不同问题,建立一些小的分类。在Mendeley中,同一篇文献是可以归属不同的文件夹的,所以在归文件夹的时候也不用那么纠结。
<img data-rawheight="1080" data-rawwidth="1807" src="https://pic3.zhimg.com/3169f44dc025aabdd98e0da52a2b217a_b.jpg" class="origin_image zh-lightbox-thumb" width="1807" data-original="https://pic3.zhimg.com/3169f44dc025aabdd98e0da52a2b217a_r.jpg">
最后,我想说的是, 任何文献整理软件都不能代替人对文献的阅读,任何时候读文献中信息永远是第一位的。整理软件只能够帮助更加快速地找到所需的信息而已。
以上。
转载自:http://www.zhihu.com/question/26901116














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









