







 My subjective ML timeline (click for larger)
My subjective ML timeline (click for larger)
Since the initial standpoint of science, technology and AI, scientists following Blaise Pascal and Von Leibniz ponder about a machine that is intellectually capable as much as humans. Famous writers like Jules
Verne , Frank Baum (Wizard of OZ), Marry Shelly (Frankenstein), George Lucas (Star Wars) dreamed artificial beings resembling human behaviors or even more, swamp humanized skills in different contexts.
 Pascal's machine performing subtraction and summation - 1642
Pascal's machine performing subtraction and summation - 1642
Machine Learning is one of the important lanes of AI which is very spicy hot subject in the research or industry. Companies, universities devote many resources to advance their knowledge. Recent advances in the field propel very solid results for different tasks, comparable to human performance (98.98% at Traffic Signs - higher than human-).
Here I would like to share a crude timeline of Machine Learning and sign some of the milestones by no means complete. In addition, you should add "up to my knowledge" to beginning of any argument in the text.
First step toward prevalent ML was proposed by Hebb, in 1949, based on a neuropsychological learning formulation. It is called Hebbian Learning theory. With a simple explanation, it pursues correlations between nodes of a Recurrent Neural Network (RNN). It memorizes any commonalities on the network and serves like a memory later. Formally, the argument states that;
Let us assume that the persistence or repetition of a reverberatory activity (or "trace") tends to induce lasting cellular changes that add to its stability.… When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A's efficiency, as one of the cells firing B, is increased.[1]
 Arthur Samuel
Arthur Samuel
In 1952, Arthur Samuel at IBM, developed a program playingCheckers. The program was able to observe positions and learn a implicit model that gives better moves for the latter cases. Samuel played so many games with the program and observed that the program was able to play better in the course of time.
With that program Samuel confuted the general providence dictating machines cannot go beyond the written codes and learn patterns like human-beings. He coined “machine learning, ” which he defines as;
a field of study that gives computer the ability without being explicitly programmed.
 F. Rosenblatt
F. Rosenblatt
In 1957, Rosenblatt's Perceptron was the second model proposed again with neuroscientific background and it is more similar to today's ML models. It was a very exciting discovery at the time and it was practically more applicable than Hebbian's idea. Rosenblatt introduced the Perceptron with the following lines;
The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.[2]
After 3 years later, Widrow [4] engraved Delta Learning rule that is then used as practical procedure for Perceptron training. It is also known as Least Square problem. Combination of those two ideas creates a good linear classifier. However, Perceptron's excitement was hinged by Minsky[3] in 1969 . He proposed the famousXOR problem and the inability of Perceptrons in such linearly inseparable data distributions. It was the Minsky's tackle to NN community. Thereafter, NN researches would be dormant up until 1980s
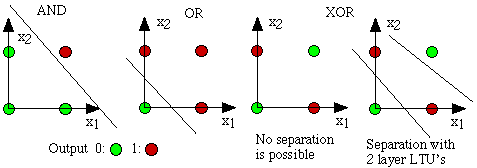 XOR problem which is nor linearly seperable data orientation
XOR problem which is nor linearly seperable data orientation
There had been not to much effort until the intuition ofMulti-Layer Perceptron (MLP) was suggested by Werbos[6]in 1981 with NN specific Backpropagation(BP) algorithm, albeit BP idea had been proposed before by Linnainmaa [5] in 1970 in the name "reverse mode of automatic differentiation". Still BP is the key ingredient of today's NN architectures. With those new ideas, NN researches accelerated again. In 1985 - 1986 NN researchers successively presented the idea of MLP with practical BPtraining (Rumelhart, Hinton, Williams [7] - Hetch, Nielsen[8])
![From Hetch and Nielsen [7]](http://www.erogol.com/wp-content/uploads/2014/05/Hetch_Nielsen_NN.png) From Hetch and Nielsen [8]
From Hetch and Nielsen [8]
At the another spectrum, a very-well known ML algorithm was proposed by J. R. Quinlan [9] in 1986 that we callDecision Trees, more specifically ID3 algorithm. This was the spark point of the another mainstream ML. Moreover, ID3 was also released as a software able to find more real-life use case with its simplistic rules and its clear inference, contrary to still black-box NN models.
After ID3, many different alternatives or improvements have been explored by the community (e.g. ID4, Regression Trees, CART ...) and still it is one of the active topic in ML.
![From Quinlan []](http://www.erogol.com/wp-content/uploads/2014/05/Quinlan_ID3.png) From Quinlan [9]
From Quinlan [9]
One of the most important ML breakthrough was Support Vector Machines (Networks) (SVM), proposed by Vapnik and Cortes[10] in 1995 with very strong theoretical standing and empirical results. That was the time separating the ML community into two crowds as NN or SVM advocates. However the competition between two community was not very easy for the NN side after Kernelized version of SVM by near 2000s.(I was not able to find the first paper about the topic), SVM got the best of many tasks that were occupied by NN models before. In addition, SVM was able to exploit all the profound knowledge of convex optimization, generalization margin theory and kernels against NN models. Therefore, it could find large push from different disciplines causing very rapid theoretical and practical improvements.
![From Vapnik and Cortes [10]](http://www.erogol.com/wp-content/uploads/2014/05/SVM_Vapnik.png) From Vapnik and Cortes [10]
From Vapnik and Cortes [10]
NN took another damage by the work of Hochreiter's thesis [40] in 1991 and Hochreiter et. al.[11] in 2001, showing the gradient loss after the saturation of NN units as we apply BP learning. Simply means, it is redundant to train NN units after a certain number of epochs owing to saturated units hence NNs are very inclined to over-fit in a short number of epochs.
Little before, another solid ML model was proposed byFreund and Schapire in 1997 prescribed with boosted ensemble of weak classifiers called Adaboost. This work also gave the Godel Prize to the authors at the time. Adaboost trains weak set of classifiers that are easy to train, by giving more importance to hard instances. This model still the basis of many different tasks like face recognition and detection. It is also a realization of PAC (Probably Approximately Correct) learning theory. In general, so called weak classifiers are chosen as simple decision stumps (single decision tree nodes). They introduced Adaboost as ;
The model we study can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting...[11]
Another ensemble model explored by Breiman [12] in 2001that ensembles multiple decision trees where each of them is curated by a random subset of instances and each node is selected from a random subset of features. Owing to its nature, it is called Random Forests(RF). RF has also theoretical and empirical proofs of endurance against over-fitting. Even AdaBoost shows weakness to over-fitting and outlier instances in the data, RF is more robust model against these caveats.(For more detail about RF, refer tomy old post.). RF shows its success in many different tasks like Kaggle competitions as well.
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large[12]
As we come closer today, a new era of NN called Deep Learning has been commerced. This phrase simply refers NN models with many wide successive layers. The 3rd rise of NN has begun roughly in 2005 with the conjunction of many different discoveries from past and present by recent mavens Hinton, LeCun, Bengio, Andrew Ng and other valuable older researchers. I enlisted some of the important headings (I guess, I will dedicate complete post for Deep Learning specifically) ;
- GPU programming
- Convolutional NNs [18][20][40]
- Deconvolutional Networks [21]
- Optimization algorithms
- Stochastic Gradient Descent [19][22]
- BFGS and L-BFGS [23]
- Conjugate Gradient Descent [24]
- Backpropagation [40][19]
- Rectifier Units
- Sparsity [15][16]
- Dropout Nets [26]
- Maxout Nets [25]
- Unsupervised NN models [14]
- Deep Belief Networks [13]
- Stacked Auto-Encoders [16][39]
- Denoising NN models [17]
With the combination of all those ideas and non-listed ones, NN models are able to beat off state of art at very different tasks such as Object Recognition, Speech Recognition, NLP etc. However, it should be noted that this absolutely does not mean, it is the end of other ML streams. Even Deep Learning success stories grow rapidly , there are many critics directed to training cost and tuning exogenous parameters of these models. Moreover, still SVM is being used more commonly owing to its simplicity. (said but may cause a huge debate














 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









