







跳跃表(Skip List),它是一种随机化的数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。
基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化的方式进行的,所以在列表中的查找可以快速的跳过部分列表,因此得名。所有操作都以对数随机化的时间进行。。他是一种多路查找的有序链表。所以他有几个特点:
1,顺序的链表
2,期望时间复杂度均为O(logn)
3,并发性能甚至好于红黑树,因为跳跃表在并发操作的时候只需要对局部加锁,而红黑树的平衡等操作本身就多耗费一些时间,在并发的情况下枷锁的范围还比较大(这个问题后续再研究)
跳跃表思想比较简单,下图(从别处找的)基本上就能说明跳跃表了。
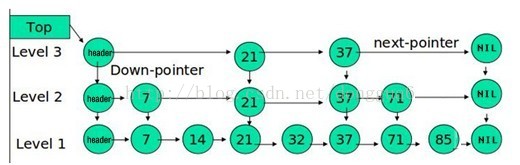
跳跃表的查找和删除都比较的简单。还是说一下插入操作,插入除了要插入到最低层链表中,还要确定该元素是否要出现在其他的高层,决定插入元素是否同时插入到上一层主要是根据50%的随机概率事件。当然用软件实现完成还不可能吧,下面的代码是参照jdk当中的ConcurrentSkipListMap的随机算法。
/**
伪随机算法(xorshift RNG)但是可以满足需求,其主要采用异或和移位来实现
参考文献http://www.jstatsoft.org/v08/i14/paper
*/private int randomLevel() {
int x = randomSeed;
x ^= x << 13;
x ^= x >>> 17;
randomSeed = x ^= x << 5;
if ((x & 0x8001) != 0) // test highest and lowest bits
return 0;
int level = 1;
while (((x >>>= 1) & 1) != 0) ++level;
return level;
}
详情可参照原著 A Skip List Cookbook
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.83.6776&rep=rep1&type=pdf














 2889
2889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









