









HashMap是基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。
HashMap可以理解成是数组和链表的结合。当新建一个HashMap时,会自动创建一个长度为16的数组(Entry[] table);一个key-value对(即Entry)放入HashMap中时,首先通过hashCode()获得该key的hash码,通过hash码决定该Entry的存储位置;如果当前存储位置有元素,则比较两个key是否相等(如果有多个元素,则循环迭代比较),相等就用新value替换原有的value,如果不相等,新的Entry和原有的Entry组合形成链(链表结构),新的Entry的next指向原有Entry。
HashMap的性能和“初始容量、加载因子”有关。
- 容量:是哈希表中数组的长度,初始容量只是哈希表在创建时的容量。
- 加载因子:是哈希表在其容量自动增加之前可以达到多满的一种尺度。
默认情况下,初始容量为16,加载因子为0.75,在容量不变的情况下,随着key-value对越来越多,hash冲突加剧,导致性能越来越差(需要循环链表进行比较)。所以当HashMap中的条目数超出了加载因子与当前容量的乘积时,则要对该HashMap进行rehash操作(即重建内部数据结构),从而哈希表将具有大约两倍的容量。
扩容完成后,原数组中的元素必须重新计算存储位置,这是个很消耗性能的操作,所以如果我们在创建HashMap时如果能预估出需要的容量大小,则可以在实例化是直接指定其初始容量大小。(new HashMap(int initialCapacity))
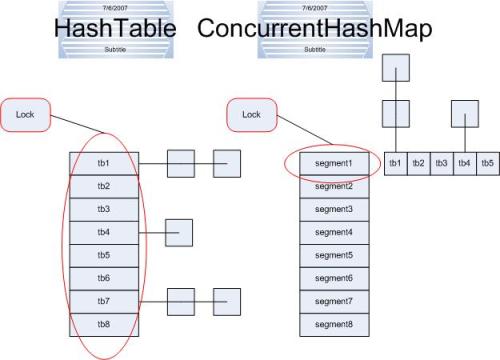
除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。而Hashtable和ConcurrentHashMap有什么分别呢?
它们都可以用于多线程的环境,但是当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。因为ConcurrentHashMap引入了分割(segmentation),不论它变得多么大,仅仅需要锁定map的某个部分,而其它的线程不需要等到迭代完成才能访问map。简而言之,在迭代的过程中,初始化时容量都是16,ConcurrentHashMap仅仅锁定map的某个位置(可以理解为ConcurrentHashMap有16个Hashtable,加锁时,只锁定其中一个),而Hashtable则会锁定整个map(一个数组)。















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











