







1. hadoop三种安装模式
- 单机模式
无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。 - 伪分布式模式
Hadoop守护进程运行在本地机器上,模拟一个小规模的集群。 - 完全分布式模式
Hadoop运行在一个真实的集群中,本文以hadoop-2.6.3为例讲解此模式配置。
2. hadoop分布式模式配置
本文的配置基于完成《hadoop安装与配置》的基础之上。集群配置信息如下:
| 名称 | IP | 功能 |
|---|---|---|
| ubuntu-master | 192.168.30.128 | namenode,jobtracker |
| ubuntu-slave | 192.168.30.129 | datanode |
在hadoop解压目录下新建tmp、hdfs、hdfs\name、hdfs\data文件夹,后续配置文件中会使用这些目录。
为hadoop用户赋予权限,使得该用户获得hadoop目录下文件的操作权限,命令如下:
sudo chown -r /usr/opt/hadoop/hadoop-2.6.3编辑hadoop-2.6.3/etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME值对应到jdk安装目录,如下:
export JAVA_HOME=/usr/opt/java/jdk1.8.0_77
配置hadoop守护进程的运行参数:
- 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://193.168.30.128:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/opt/hadoop/hadoop-2.6.3/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration> - 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.30.128:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/opt/hadoop/hadoop-2.6.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/opt/hadoop/hadoop-2.6.3/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> - 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.30.128:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.30.128:19888</value>
</property>
</configuration> - 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.30.128:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.30.128:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.30.128:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.30.128:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.30.128:8088</value>
</property>
</configuration> - 配置masters
将msater机器加入masters文件中,内如如下:
192.168.30.128- 配置slaves
将所有slave机器加入到slave是文件中(如果master也作为datanode请一并加入),内容如下:
192.168.30.128
192.168.30.129
- 修改hosts
修改所有master机器和slave机器的hosts文件,注意注释掉127.0.1.1配置
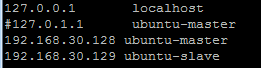
最后在所有机器上复制以上配置信息,可以通过复制/etc/hadoop文件夹到所有机器相应目录下,完成机器配置复制,命令如下:
scp -r /usr/opt/hadoop/hadoop-2.6.3/etc/hadoop czliuming@192.168.30.128:/usr/opt/hadoop/hadoop-2.6.3/etc注:如果上述文件在相应目录下不存在,可以自行创建,我的目录下就没有mapred-site.xml
完成以上配置后,hadoop集群已搭建完毕,下面进行hdfs初始化(仅执行一次),进入hadoop安装目录,执行以下命令:
bin/hadoop namenode -format出现如下界面则hdfs初始化成功:
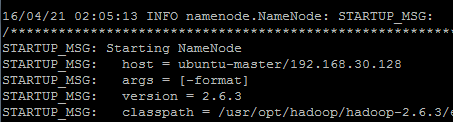
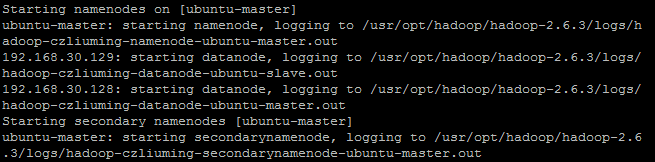
hdfs初始化结束后,我们就可以尝试启动hadoop集群了,首先启动hdfs命令如下:
sbin/start-dfs.sh出现如下图信息,则表示启动成功:
接下来,我们启动yarn,执行以下命令;
sbin/start-yarn.sh启动信息如下图:

最后通过浏览器访问(http://192.168.30.128:8088/cluster/nodes)来查看集群运行状态,如下图所示:
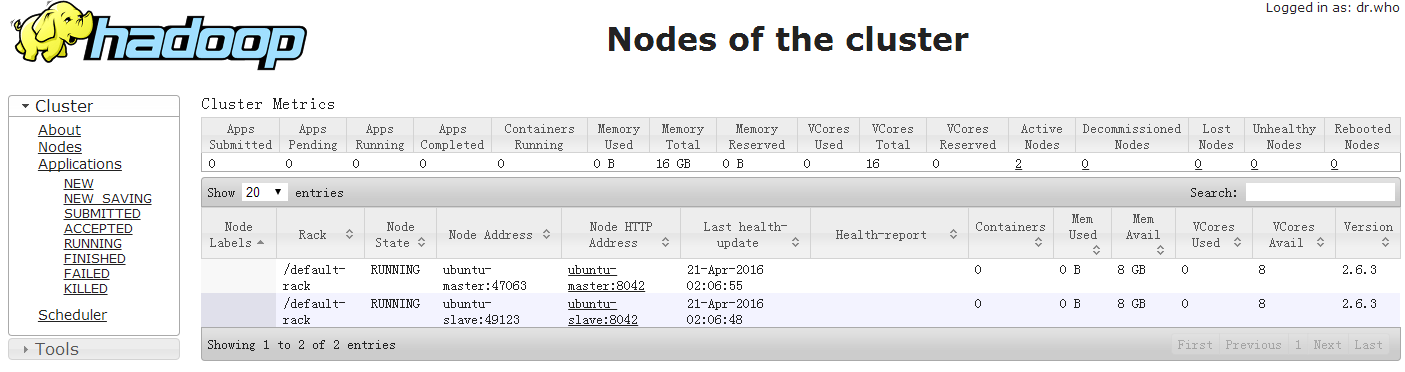
至此,hadoop集群的搭建已全部完成。
3. WordCount测试
Eclipse安装Hadoop插件
在GitHub上下载[hadoop-eclipse-plugin-2.6.0插件]将hadoop-eclipse-plugin-2.6.0.jar拷贝到Eclipse安装目录\plungins目录下,重启Eclipse打开window->preferences,如果增加了Hadoop map/reduce菜单则证明插件安装成功。
在系统环境变量中新建变量“HADOOP_USER_NAME=czliuming”并新建变量“HADOOP_HOME=D:\Software\Hadoop\hadoop-2.6.3”将hadoop解压目录下bin目录加入path路径中。
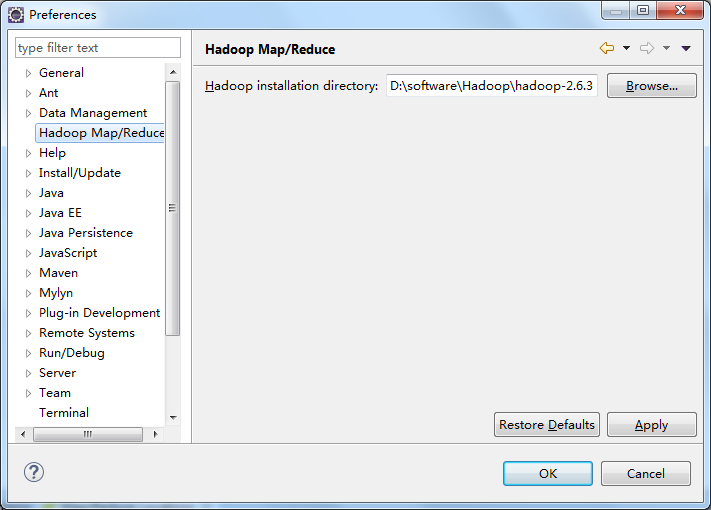
点击Hadoop map/reduce菜单,配置hadoop在本地系统的解压目录如图所示:
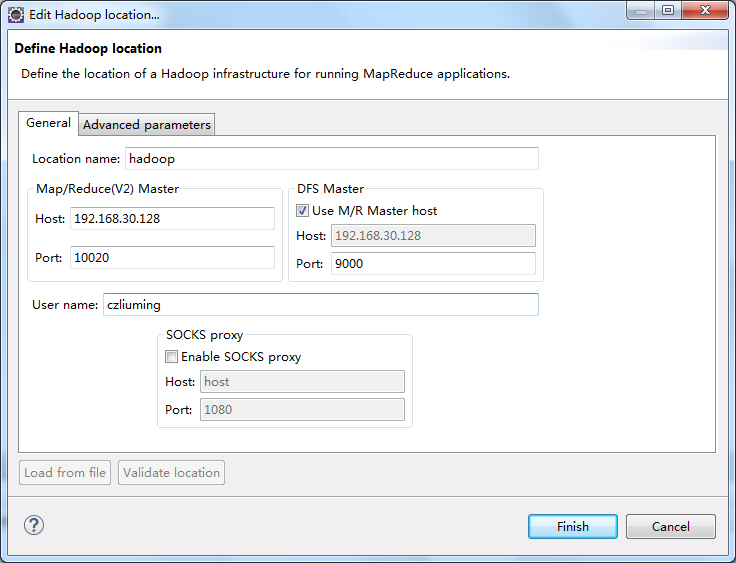
切换到map/reduce工程视图,在Map/Reduce Locations控制台中右键选择“New Hadoop Location”对hadoop集群进行连接配置,如图所示:
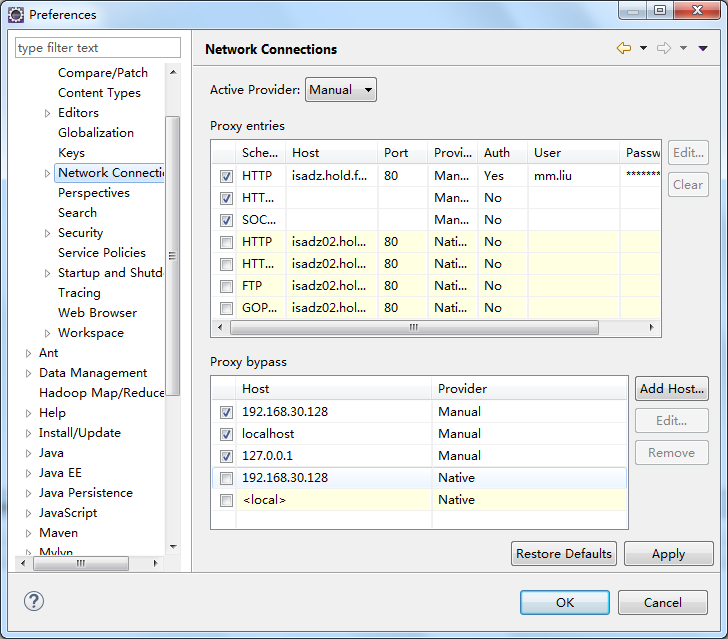
其中,Host为hadoop-master的ip地址,map/reduce端口号为mapred-site.xml中mapreduce.jobhistory.address配置的端口号,DFS端口号为core-site.xml中fs.defaultFS配置的端口号。注意:如果连接失败,请检查代理设置,将master机器IP加入到代理过滤列表中,如图所示:
WordCount程序测试
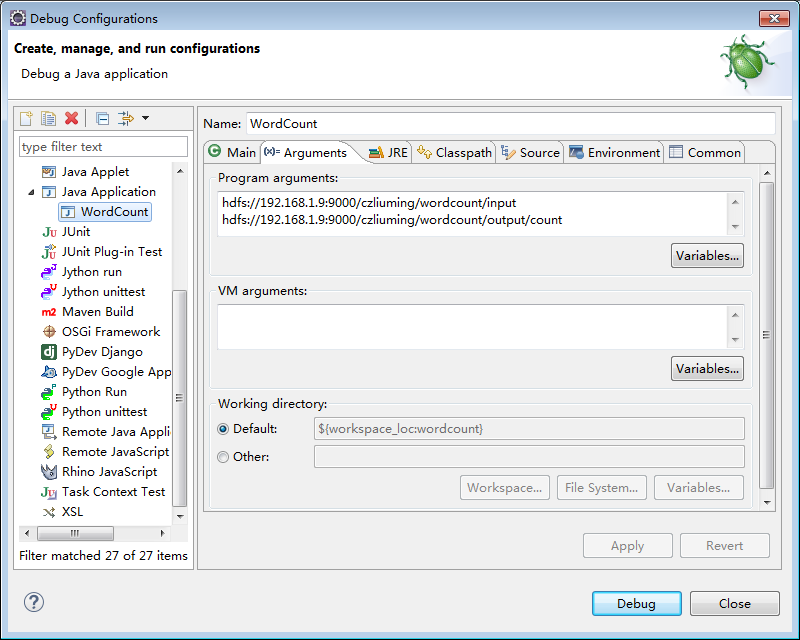
新建Map/Reduce Project,在src目录中新建WordCount类,并输入以下代码:package wordcount; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }设置启动参数,如图所示:
其中,第一个为输入目录,第二个为输出目录,根据实际情况进行配置,我的配置如下:
最后执行wordcount程序,执行完毕会在输出目录输出单词统计结果,至此wordcount测试结束。
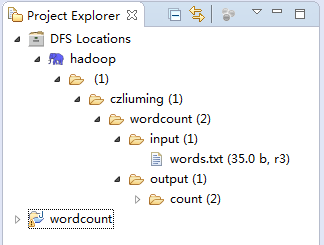
注意:如果执行过程中出现报错,请参考《Hadoop常见问题汇总》进行处理。














 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









