









编译 | AI科技大本营
参与 | 林椿眄
编辑 | 谷 磊
对于许多具有挑战性的现实问题,深度学习已经成为最有效的解决方法。
例如,对于目标检测,语音识别和语言翻译等问题,深度学习能够表现出最佳的性能。许多人认为深度神经网络(DNNs)是一种神奇的黑盒子,我们只需要输入一堆数据,网络就能够输出我们所要的解决方案!但是,在实践中我们往往会碰到更多、更复杂的问题。
在设计网络模型并将DNNs应用到一个特定的问题上,往往会遇到很多挑战。对于某一特定的实际问题,我们需要根据实际应用,正确地设计并训练网络模型,同时数据的准备工作也是至关重要的,这将直接影响模型的训练和推理过程。
通过这篇博文,我将与大家分享7个深度学习实用技巧,教你如何让深度神经网络发挥最大作用。
▌1、数据!数据!数据!
众所周知的是,如果把深度学习比作一台大型的机器,那么数据就好比是这台机器的燃料,同时它的数量也能决定深度学习这台机器的性能好坏。有标签的数据越多,模型的性能越好。
对于“更多的数据导致更好的性能”的这个观点,已经得到了业界的一致认同,有兴趣的可以看看这篇题为《重温深度学习时代数据不可思议的有效性》的文章
(https://arxiv.org/abs/1707.02968),进一步了解谷歌公司关于大规模数据的探索以及3亿张图像数据集的构建!
在实际应用中,部署一个深度学习模型时你需要不断地为其提供更多的数据,并通过微调参数来进一步提高模型的性能。如果你想提高模型性能的话,那就尽可能获得更多的数据吧!
增加数据量能够稳定地提高模型的性能
▌2、你应该使用哪种优化器呢?
经过多年的探索,研究人员开发了不同的梯度下降优化算法(SGD),但各有各的优缺点。常被广泛使用的算法包括:
带动量的随机梯度下降法
žAdam法
RMSprop法
Adadelta法
其中,RMSprop,Adadelta和Adam法都是一种自适应优化算法,因为它们会自动更新学习速率。如果使用普通的随机梯度下降法,你需要手动地选择学习率和动量参数,设置动量参数是为了随着时间的推移来不断地降低学习率。
在实践中,自适应优化器往往比普通的梯度下降法更快地让模型达到收敛状态。然而,选择这些优化器的模型最终性能通常都不太好,而普通的梯度下降法通常能够达到更好的收敛最小值,从而获得更好的模型性能,但这可能比某些优化程序需要更多的收敛时间。此外,随机梯度下降法也更依赖于有效的初始化方法和学习速率衰减指数的设置,这在实践中是很难确定的。
因此,如果你只是想快速地获得一些结果,或者只是想测试一个新的技术,自适应优化器将会是不错的选择。Adam是个容易上手的自适应优化器,因为它对初始学习率的设置没有很严格的要求,对于学习率的变化过程也并不是很敏感,因此非常利于深度学习模型的部署。如果你想获得模型的最优性能,可以尝试选择带动量的随机梯度下降法,并通过设置学习率,衰减率和动量参数来最大化模型的性能。
最近的研究表明,你可以混合地使用两类优化器:由Adam优化器过渡到随机梯度下降法来优化模型,能够获得最顶尖的训练模型!具体的做法是,在训练的早期阶段,往往是模型参数的初始化和调整非常敏感的时候。因此,我们可以使用Adam优化器来启动模型的训练,这将为模型的训练节省很多参数初始化和微调的时间。一旦模型的性能有所起伏,我们就可以切换到带动量的随机梯度下降法来进一步优化我们的模型,以达到最佳的性能!
Adam与SGD的性能对比。
由于自适应优化算法能够自适应地设置学习率,其鲁棒性更好,
因此Adam在训练的初期性能更佳,
而SGD能够在训练结束后获得更好的全局最小值。
▌3、如何处理数据不平衡问题
在实际应用中,很多情况下我们将面对不平衡的数据分布。举一个简单的实际例子:你要训练一个深度网络来预测视频Feed流中是否有人持有致命武器。但是训练数据中,只有50个视频中有拿着武器的人以及1000个不带武器的视频!如果只是用这些数据来训练深度学习网络的话,那么模型的性能将不会很好,预测的结果也将偏向于没有武器!这种情况下,我们可以通过一些方法来解决数据的不平衡问题:
对损失函数使用类别权重。简单地说,对于数据量小,代表性不足的类别,在损失函数中使用较高的权重值,这样的话对该类的任何错误都将导致非常大的损失值,以此来惩罚错误分类。
过度抽样:对于数据量小,代表性不足的训练样本,重复地进行采样,这有助于平衡数据类别的分布。对于一些很小的数据集来说,这是解决数据不均衡问题的最好方式。
欠采样:对于数据量大的类别,在模型训练过程汇总可以简单地跳过而不去选择这些数据,这也能一定程度上缓解数据的不平衡现象,特别对于大数据集而言。
数据增强(对少样本的类别):可以对数据量不足的类别做数据增强操作,生成更多的训练样本!例如,在上面检测致命武器的例子中,你可以改变那些带致命武器视频的颜色和光照条件,来生成更多的视频数据。
▌4、迁移学习
正如上面所说的,深度学习模型通常需要大量的数据,数据量越多,模型的性能也将越好。然而,对于一些应用程序来说,大数据的获取可能很困难,标记数据的成本花费也很高。如果我们希望模型的性能达到最佳的话,那么可能至少需要数十万级的数据来训练深度模型。不仅如此,对于不带标签的数据,我们还需要手动地标记数据,这是项非常耗费成本的工作。
面对这种情况,迁移学习将展现其强大的一面。应用迁移学习策略,在不需要太多的训练数据的情况下就能够让我们的模型达到最优的性能!举个例子,例如在百万级ImageNet数据库上预训练ResNet模型。然后冻结模型的前几层权重参数,用我们的数据重训练模型的最后几层并微调ResNet模型。
如此,通过重训练ResNet模型的部分层,我们就可以微调模型学到的图像特征信息,以便将其迁移应用于不同的任务。这是完全有可能实现的,因为图像的低层特征通常都是非常相似的,而高层次的特征则会随着应用的不同而改变。
迁移学习的基本流程
▌5、数据增强:快速而简单地提高模型性能
我们反复地提到:更多的数据 = 更好的模型表现。除了迁移学习之外,提高模型性能的另一种快速而简单的方法是数据增强。数据增强操作是在保证数据原始类别标签的同时,对一些原始图像进行非线性的图像变换,来生成/合成新的训练样本。 常见的图像数据增强方式包括:
水平或垂直旋转/翻转图像
随机改变图像的亮度和颜色
随机模糊图像
随机裁剪图像
基本上,你可以对图像进行任何操作,改变图像的外观,但不能改变整体的内容。即对于一张狗的照片,你可以改变它的大小、角度、颜色、清晰度等,但你要保证它仍然是一张狗的照片。
丰富的数据增强样本
▌6、集成你的模型!
在机器学习中,同时训练多个模型,然后将它们组合在一起能够获得更高的整体性能。具体地说,对弈一个特定的任务,在相同的数据集上同时训练多个深度网络模型。然后,组合模型并通过投票的方式为每个模型分配不同的权重值。最终根据模型的整体性能决定最优的组合方案。
为了保证每个训练模型都有一定的差异性,我们可以对权重进行随机初始化来处理训练模型,还可以通过随机地数据增强来丰富我们的训练数据。一般说来,通过组合多个模型得到的集成模型通常会比单个模型的性能更好,因此这也更贴近实际应用的需要。特别地,在一些比赛中,获胜方通常都是采用集成模型追求更佳的整体性能,来解决实际问题。
集成模型
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接
▌1、数据!数据!数据!
众所周知的是,如果把深度学习比作一台大型的机器,那么数据就好比是这台机器的燃料,同时它的数量也能决定深度学习这台机器的性能好坏。有标签的数据越多,模型的性能越好。
对于“更多的数据导致更好的性能”的这个观点,已经得到了业界的一致认同,有兴趣的可以看看这篇题为《重温深度学习时代数据不可思议的有效性》的文章
(https://arxiv.org/abs/1707.02968),进一步了解谷歌公司关于大规模数据的探索以及3亿张图像数据集的构建!
在实际应用中,部署一个深度学习模型时你需要不断地为其提供更多的数据,并通过微调参数来进一步提高模型的性能。如果你想提高模型性能的话,那就尽可能获得更多的数据吧!
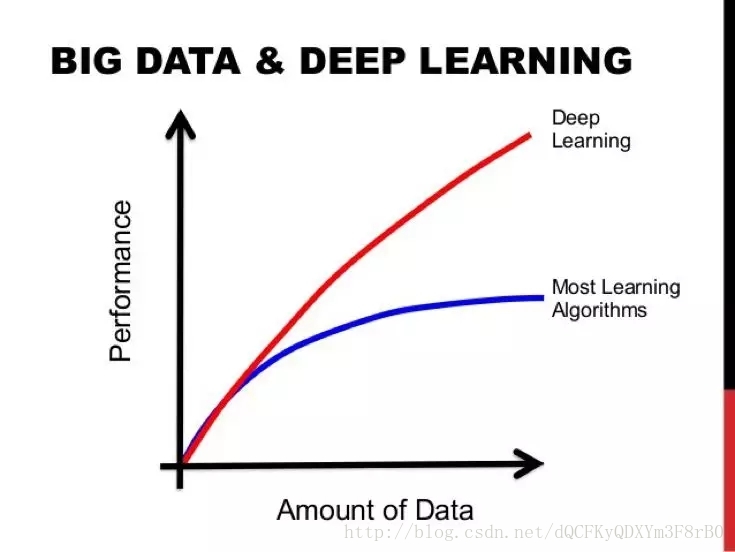
增加数据量能够稳定地提高模型的性能
▌2、你应该使用哪种优化器呢?
经过多年的探索,研究人员开发了不同的梯度下降优化算法(SGD),但各有各的优缺点。常被广泛使用的算法包括:
带动量的随机梯度下降法
žAdam法
RMSprop法
Adadelta法
其中,RMSprop,Adadelta和Adam法都是一种自适应优化算法,因为它们会自动更新学习速率。如果使用普通的随机梯度下降法,你需要手动地选择学习率和动量参数,设置动量参数是为了随着时间的推移来不断地降低学习率。
在实践中,自适应优化器往往比普通的梯度下降法更快地让模型达到收敛状态。然而,选择这些优化器的模型最终性能通常都不太好,而普通的梯度下降法通常能够达到更好的收敛最小值,从而获得更好的模型性能,但这可能比某些优化程序需要更多的收敛时间。此外,随机梯度下降法也更依赖于有效的初始化方法和学习速率衰减指数的设置,这在实践中是很难确定的。
因此,如果你只是想快速地获得一些结果,或者只是想测试一个新的技术,自适应优化器将会是不错的选择。Adam是个容易上手的自适应优化器,因为它对初始学习率的设置没有很严格的要求,对于学习率的变化过程也并不是很敏感,因此非常利于深度学习模型的部署。如果你想获得模型的最优性能,可以尝试选择带动量的随机梯度下降法,并通过设置学习率,衰减率和动量参数来最大化模型的性能。
最近的研究表明,你可以混合地使用两类优化器:由Adam优化器过渡到随机梯度下降法来优化模型,能够获得最顶尖的训练模型!具体的做法是,在训练的早期阶段,往往是模型参数的初始化和调整非常敏感的时候。因此,我们可以使用Adam优化器来启动模型的训练,这将为模型的训练节省很多参数初始化和微调的时间。一旦模型的性能有所起伏,我们就可以切换到带动量的随机梯度下降法来进一步优化我们的模型,以达到最佳的性能!
Adam与SGD的性能对比。
由于自适应优化算法能够自适应地设置学习率,其鲁棒性更好,
因此Adam在训练的初期性能更佳,
而SGD能够在训练结束后获得更好的全局最小值。
▌3、如何处理数据不平衡问题
在实际应用中,很多情况下我们将面对不平衡的数据分布。举一个简单的实际例子:你要训练一个深度网络来预测视频Feed流中是否有人持有致命武器。但是训练数据中,只有50个视频中有拿着武器的人以及1000个不带武器的视频!如果只是用这些数据来训练深度学习网络的话,那么模型的性能将不会很好,预测的结果也将偏向于没有武器!这种情况下,我们可以通过一些方法来解决数据的不平衡问题:
对损失函数使用类别权重。简单地说,对于数据量小,代表性不足的类别,在损失函数中使用较高的权重值,这样的话对该类的任何错误都将导致非常大的损失值,以此来惩罚错误分类。
过度抽样:对于数据量小,代表性不足的训练样本,重复地进行采样,这有助于平衡数据类别的分布。对于一些很小的数据集来说,这是解决数据不均衡问题的最好方式。
欠采样:对于数据量大的类别,在模型训练过程汇总可以简单地跳过而不去选择这些数据,这也能一定程度上缓解数据的不平衡现象,特别对于大数据集而言。
数据增强(对少样本的类别):可以对数据量不足的类别做数据增强操作,生成更多的训练样本!例如,在上面检测致命武器的例子中,你可以改变那些带致命武器视频的颜色和光照条件,来生成更多的视频数据。
▌4、迁移学习
正如上面所说的,深度学习模型通常需要大量的数据,数据量越多,模型的性能也将越好。然而,对于一些应用程序来说,大数据的获取可能很困难,标记数据的成本花费也很高。如果我们希望模型的性能达到最佳的话,那么可能至少需要数十万级的数据来训练深度模型。不仅如此,对于不带标签的数据,我们还需要手动地标记数据,这是项非常耗费成本的工作。
面对这种情况,迁移学习将展现其强大的一面。应用迁移学习策略,在不需要太多的训练数据的情况下就能够让我们的模型达到最优的性能!举个例子,例如在百万级ImageNet数据库上预训练ResNet模型。然后冻结模型的前几层权重参数,用我们的数据重训练模型的最后几层并微调ResNet模型。
如此,通过重训练ResNet模型的部分层,我们就可以微调模型学到的图像特征信息,以便将其迁移应用于不同的任务。这是完全有可能实现的,因为图像的低层特征通常都是非常相似的,而高层次的特征则会随着应用的不同而改变。
迁移学习的基本流程
▌5、数据增强:快速而简单地提高模型性能
我们反复地提到:更多的数据 = 更好的模型表现。除了迁移学习之外,提高模型性能的另一种快速而简单的方法是数据增强。数据增强操作是在保证数据原始类别标签的同时,对一些原始图像进行非线性的图像变换,来生成/合成新的训练样本。 常见的图像数据增强方式包括:
水平或垂直旋转/翻转图像
随机改变图像的亮度和颜色
随机模糊图像
随机裁剪图像
基本上,你可以对图像进行任何操作,改变图像的外观,但不能改变整体的内容。即对于一张狗的照片,你可以改变它的大小、角度、颜色、清晰度等,但你要保证它仍然是一张狗的照片。
丰富的数据增强样本
▌6、集成你的模型!
在机器学习中,同时训练多个模型,然后将它们组合在一起能够获得更高的整体性能。具体地说,对弈一个特定的任务,在相同的数据集上同时训练多个深度网络模型。然后,组合模型并通过投票的方式为每个模型分配不同的权重值。最终根据模型的整体性能决定最优的组合方案。
为了保证每个训练模型都有一定的差异性,我们可以对权重进行随机初始化来处理训练模型,还可以通过随机地数据增强来丰富我们的训练数据。一般说来,通过组合多个模型得到的集成模型通常会比单个模型的性能更好,因此这也更贴近实际应用的需要。特别地,在一些比赛中,获胜方通常都是采用集成模型追求更佳的整体性能,来解决实际问题。
集成模型
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接
▌2、你应该使用哪种优化器呢?
经过多年的探索,研究人员开发了不同的梯度下降优化算法(SGD),但各有各的优缺点。常被广泛使用的算法包括:
- 带动量的随机梯度下降法
- žAdam法
- RMSprop法
- Adadelta法
其中,RMSprop,Adadelta和Adam法都是一种自适应优化算法,因为它们会自动更新学习速率。如果使用普通的随机梯度下降法,你需要手动地选择学习率和动量参数,设置动量参数是为了随着时间的推移来不断地降低学习率。
在实践中,自适应优化器往往比普通的梯度下降法更快地让模型达到收敛状态。然而,选择这些优化器的模型最终性能通常都不太好,而普通的梯度下降法通常能够达到更好的收敛最小值,从而获得更好的模型性能,但这可能比某些优化程序需要更多的收敛时间。此外,随机梯度下降法也更依赖于有效的初始化方法和学习速率衰减指数的设置,这在实践中是很难确定的。
因此,如果你只是想快速地获得一些结果,或者只是想测试一个新的技术,自适应优化器将会是不错的选择。Adam是个容易上手的自适应优化器,因为它对初始学习率的设置没有很严格的要求,对于学习率的变化过程也并不是很敏感,因此非常利于深度学习模型的部署。如果你想获得模型的最优性能,可以尝试选择带动量的随机梯度下降法,并通过设置学习率,衰减率和动量参数来最大化模型的性能。
最近的研究表明,你可以混合地使用两类优化器:由Adam优化器过渡到随机梯度下降法来优化模型,能够获得最顶尖的训练模型!具体的做法是,在训练的早期阶段,往往是模型参数的初始化和调整非常敏感的时候。因此,我们可以使用Adam优化器来启动模型的训练,这将为模型的训练节省很多参数初始化和微调的时间。一旦模型的性能有所起伏,我们就可以切换到带动量的随机梯度下降法来进一步优化我们的模型,以达到最佳的性能!
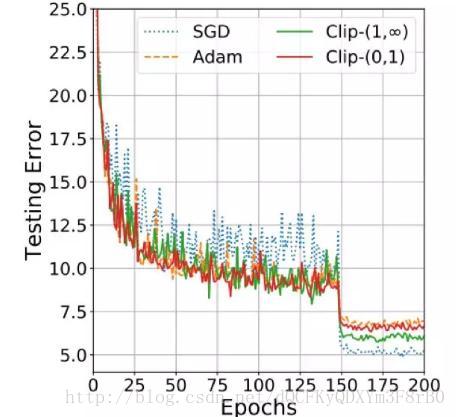
Adam与SGD的性能对比
由于自适应优化算法能够自适应地设置学习率,其鲁棒性更好,因此Adam在训练的初期性能更佳,而SGD能够在训练结束后获得更好的全局最小值。
▌3、如何处理数据不平衡问题
在实际应用中,很多情况下我们将面对不平衡的数据分布。举一个简单的实际例子:你要训练一个深度网络来预测视频Feed流中是否有人持有致命武器。但是训练数据中,只有50个视频中有拿着武器的人以及1000个不带武器的视频!如果只是用这些数据来训练深度学习网络的话,那么模型的性能将不会很好,预测的结果也将偏向于没有武器!这种情况下,我们可以通过一些方法来解决数据的不平衡问题:
对损失函数使用类别权重。简单地说,对于数据量小,代表性不足的类别,在损失函数中使用较高的权重值,这样的话对该类的任何错误都将导致非常大的损失值,以此来惩罚错误分类。
过度抽样:对于数据量小,代表性不足的训练样本,重复地进行采样,这有助于平衡数据类别的分布。对于一些很小的数据集来说,这是解决数据不均衡问题的最好方式。
欠采样:对于数据量大的类别,在模型训练过程汇总可以简单地跳过而不去选择这些数据,这也能一定程度上缓解数据的不平衡现象,特别对于大数据集而言。
数据增强(对少样本的类别):可以对数据量不足的类别做数据增强操作,生成更多的训练样本!例如,在上面检测致命武器的例子中,你可以改变那些带致命武器视频的颜色和光照条件,来生成更多的视频数据。
▌4、迁移学习
正如上面所说的,深度学习模型通常需要大量的数据,数据量越多,模型的性能也将越好。然而,对于一些应用程序来说,大数据的获取可能很困难,标记数据的成本花费也很高。如果我们希望模型的性能达到最佳的话,那么可能至少需要数十万级的数据来训练深度模型。不仅如此,对于不带标签的数据,我们还需要手动地标记数据,这是项非常耗费成本的工作。
面对这种情况,迁移学习将展现其强大的一面。应用迁移学习策略,在不需要太多的训练数据的情况下就能够让我们的模型达到最优的性能!举个例子,例如在百万级ImageNet数据库上预训练ResNet模型。然后冻结模型的前几层权重参数,用我们的数据重训练模型的最后几层并微调ResNet模型。
如此,通过重训练ResNet模型的部分层,我们就可以微调模型学到的图像特征信息,以便将其迁移应用于不同的任务。这是完全有可能实现的,因为图像的低层特征通常都是非常相似的,而高层次的特征则会随着应用的不同而改变。
迁移学习的基本流程
▌5、数据增强:快速而简单地提高模型性能
我们反复地提到:更多的数据 = 更好的模型表现。除了迁移学习之外,提高模型性能的另一种快速而简单的方法是数据增强。数据增强操作是在保证数据原始类别标签的同时,对一些原始图像进行非线性的图像变换,来生成/合成新的训练样本。 常见的图像数据增强方式包括:
水平或垂直旋转/翻转图像
随机改变图像的亮度和颜色
随机模糊图像
随机裁剪图像
基本上,你可以对图像进行任何操作,改变图像的外观,但不能改变整体的内容。即对于一张狗的照片,你可以改变它的大小、角度、颜色、清晰度等,但你要保证它仍然是一张狗的照片。
丰富的数据增强样本
▌6、集成你的模型!
在机器学习中,同时训练多个模型,然后将它们组合在一起能够获得更高的整体性能。具体地说,对弈一个特定的任务,在相同的数据集上同时训练多个深度网络模型。然后,组合模型并通过投票的方式为每个模型分配不同的权重值。最终根据模型的整体性能决定最优的组合方案。
为了保证每个训练模型都有一定的差异性,我们可以对权重进行随机初始化来处理训练模型,还可以通过随机地数据增强来丰富我们的训练数据。一般说来,通过组合多个模型得到的集成模型通常会比单个模型的性能更好,因此这也更贴近实际应用的需要。特别地,在一些比赛中,获胜方通常都是采用集成模型追求更佳的整体性能,来解决实际问题。
集成模型
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接
▌3、如何处理数据不平衡问题
在实际应用中,很多情况下我们将面对不平衡的数据分布。举一个简单的实际例子:你要训练一个深度网络来预测视频Feed流中是否有人持有致命武器。但是训练数据中,只有50个视频中有拿着武器的人以及1000个不带武器的视频!如果只是用这些数据来训练深度学习网络的话,那么模型的性能将不会很好,预测的结果也将偏向于没有武器!这种情况下,我们可以通过一些方法来解决数据的不平衡问题:
- 对损失函数使用类别权重。简单地说,对于数据量小,代表性不足的类别,在损失函数中使用较高的权重值,这样的话对该类的任何错误都将导致非常大的损失值,以此来惩罚错误分类。
- 过度抽样:对于数据量小,代表性不足的训练样本,重复地进行采样,这有助于平衡数据类别的分布。对于一些很小的数据集来说,这是解决数据不均衡问题的最好方式。
- 欠采样:对于数据量大的类别,在模型训练过程汇总可以简单地跳过而不去选择这些数据,这也能一定程度上缓解数据的不平衡现象,特别对于大数据集而言。
- 数据增强(对少样本的类别):可以对数据量不足的类别做数据增强操作,生成更多的训练样本!例如,在上面检测致命武器的例子中,你可以改变那些带致命武器视频的颜色和光照条件,来生成更多的视频数据。
▌4、迁移学习
正如上面所说的,深度学习模型通常需要大量的数据,数据量越多,模型的性能也将越好。然而,对于一些应用程序来说,大数据的获取可能很困难,标记数据的成本花费也很高。如果我们希望模型的性能达到最佳的话,那么可能至少需要数十万级的数据来训练深度模型。不仅如此,对于不带标签的数据,我们还需要手动地标记数据,这是项非常耗费成本的工作。
面对这种情况,迁移学习将展现其强大的一面。应用迁移学习策略,在不需要太多的训练数据的情况下就能够让我们的模型达到最优的性能!举个例子,例如在百万级ImageNet数据库上预训练ResNet模型。然后冻结模型的前几层权重参数,用我们的数据重训练模型的最后几层并微调ResNet模型。
如此,通过重训练ResNet模型的部分层,我们就可以微调模型学到的图像特征信息,以便将其迁移应用于不同的任务。这是完全有可能实现的,因为图像的低层特征通常都是非常相似的,而高层次的特征则会随着应用的不同而改变。
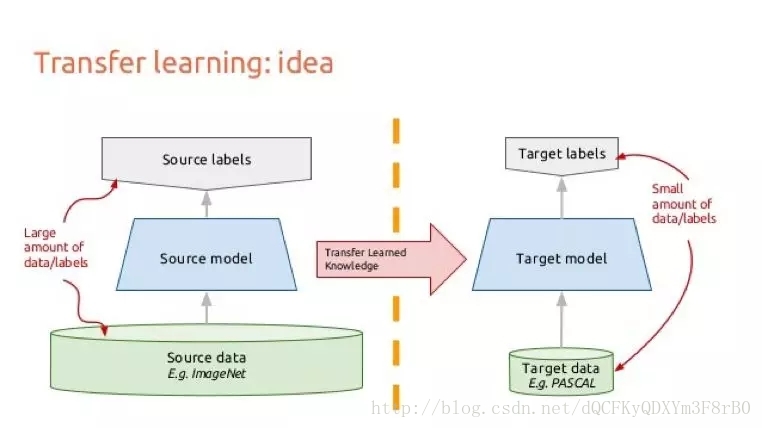
迁移学习的基本流程
▌5、数据增强:快速而简单地提高模型性能
我们反复地提到:更多的数据 = 更好的模型表现。除了迁移学习之外,提高模型性能的另一种快速而简单的方法是数据增强。数据增强操作是在保证数据原始类别标签的同时,对一些原始图像进行非线性的图像变换,来生成/合成新的训练样本。 常见的图像数据增强方式包括:
水平或垂直旋转/翻转图像
随机改变图像的亮度和颜色
随机模糊图像
随机裁剪图像
基本上,你可以对图像进行任何操作,改变图像的外观,但不能改变整体的内容。即对于一张狗的照片,你可以改变它的大小、角度、颜色、清晰度等,但你要保证它仍然是一张狗的照片。
丰富的数据增强样本
▌6、集成你的模型!
在机器学习中,同时训练多个模型,然后将它们组合在一起能够获得更高的整体性能。具体地说,对弈一个特定的任务,在相同的数据集上同时训练多个深度网络模型。然后,组合模型并通过投票的方式为每个模型分配不同的权重值。最终根据模型的整体性能决定最优的组合方案。
为了保证每个训练模型都有一定的差异性,我们可以对权重进行随机初始化来处理训练模型,还可以通过随机地数据增强来丰富我们的训练数据。一般说来,通过组合多个模型得到的集成模型通常会比单个模型的性能更好,因此这也更贴近实际应用的需要。特别地,在一些比赛中,获胜方通常都是采用集成模型追求更佳的整体性能,来解决实际问题。
集成模型
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接
▌5、数据增强:快速而简单地提高模型性能
我们反复地提到:更多的数据 = 更好的模型表现。除了迁移学习之外,提高模型性能的另一种快速而简单的方法是数据增强。数据增强操作是在保证数据原始类别标签的同时,对一些原始图像进行非线性的图像变换,来生成/合成新的训练样本。 常见的图像数据增强方式包括:
- 水平或垂直旋转/翻转图像
- 随机改变图像的亮度和颜色
- 随机模糊图像
- 随机裁剪图像
基本上,你可以对图像进行任何操作,改变图像的外观,但不能改变整体的内容。即对于一张狗的照片,你可以改变它的大小、角度、颜色、清晰度等,但你要保证它仍然是一张狗的照片。

丰富的数据增强样本
▌6、集成你的模型!
在机器学习中,同时训练多个模型,然后将它们组合在一起能够获得更高的整体性能。具体地说,对弈一个特定的任务,在相同的数据集上同时训练多个深度网络模型。然后,组合模型并通过投票的方式为每个模型分配不同的权重值。最终根据模型的整体性能决定最优的组合方案。
为了保证每个训练模型都有一定的差异性,我们可以对权重进行随机初始化来处理训练模型,还可以通过随机地数据增强来丰富我们的训练数据。一般说来,通过组合多个模型得到的集成模型通常会比单个模型的性能更好,因此这也更贴近实际应用的需要。特别地,在一些比赛中,获胜方通常都是采用集成模型追求更佳的整体性能,来解决实际问题。
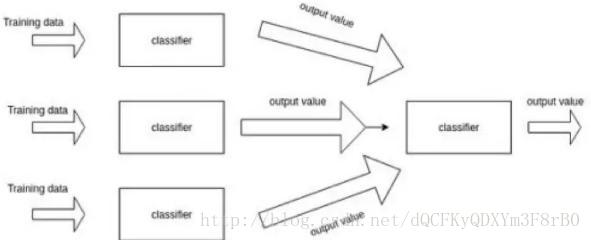
集成模型
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接
▌7、剪枝——为你的训练提速
随着模型深度的增加,模型性能也将更好,但模型的训练速度又如何呢?层数越深意味着参数量更多,而更多的参数意味着更多的计算和更多的内存消耗,训练速度也将变慢。理想情况下,我们希望在提高训练速度的同时保持模型的高性能。这可以通过剪枝来实现。
剪枝的核心思想是,深度网络中存在许多冗余参数,这些参数对模型的输出没有太大贡献。我们可以按网络的输出贡献来排列网络中的神经元,将排名低的那些神经元移除我们的模型,这样就可以得到一个更小、更快的网络。此外,还可以根据神经元权重的L1/L2均值来平均激活每个神经元,再通过计算神经元在验证集上不为零的次数或者其他创造性方法来对神经元进行排序。一个更快/更小的模型,对于深度学习模型在移动设备上部署是至关重要的。
最近的一些研究表明,仅仅丢弃一些卷积滤波器,就能够在不损耗模型精度的同时加速模型的训练,得到一个快而小的深度模型。在这项研究中,神经元的排名方式也是相当简单:在每个修剪迭代中,利用每个滤波器权重的L1范数对所有的过滤器进行排序,然后在全部层中修剪掉m个排名最低的过滤器,再不断重复以上的操作直到获得我们想要的模型。这是个非常成功的剪枝案例。
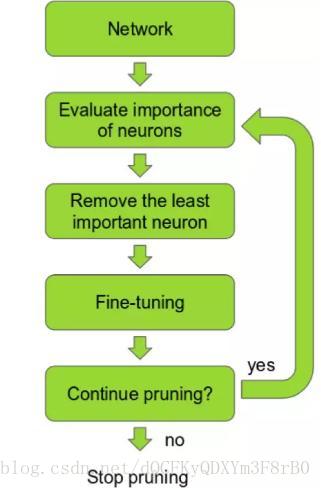
深度神经网络修剪的步骤
此外,在最近的另一篇分析ResNet模型结构的文章中,作者提出了一种修剪过滤器的观点。研究发现,在移除网络层的时候,带残余连接的网络(如ResNets)与那些没有使用快捷连接的网络(如VGG或AlexNet)相比,残差网络的性能更加稳健,在剪枝的同时也不会过多地影响模型的性能。这项发现具有重要的实际意义,这就意味着我们在部署一个修剪网络时,网络设计最好要采用残差网络结构(如ResNets),让我们的模型鲁棒性更好。
以上,就是你能学习到的7大深度学习实用技巧!
作者 | George Seif
原文链接














 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









