









“ 图解用栈数据结构对树的前序遍历,中序遍历,后续遍历。”
树的遍历
所谓遍历 (Traversal) 是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问题。
二叉树遍历
本文以二叉树的遍历为例总结。
二叉树由根结点及左、右子树这三个基本部分组成。因此,在任一给定结点上,可以按某种次序执行三个操作:
访问结点本身(Node)
遍历该结点的左子树(Left subtree)
遍历该结点的右子树(Right subtree)
根据访问结点操作发生位置不同,命名:
前序遍历 Preorder Traversal :访问根结点的操作发生在遍历其左右子树之前。
中序遍历 Inorder Traversal:访问根结点的操作发生在遍历其左右子树之中间。
后序遍历 Postorder Traversal : 访问根结点的操作发生在遍历其左右子树之后。
二叉树的数据结构定义如下所示:
public class TreeNode<T>
{
public T val { get; set; }
public TreeNode<T> left { get; set; }
public TreeNode<T> right { get; set; }
public TreeNode(T data)
{
val = data;
}
}思考算法
我们借助栈,先将根节点推入栈内,因为首先访问根节点,这意味着它必须先出栈,但是我们还没有机会让左右子树入栈呢?
自然地,我们想到定义一个临时变量引用根节点,这样在循环时,不断修改这个临时变量,我们在此处将它成为上下文 context,它始终指向当前遍历子树的根节点,如下图所示,假设为某个遍历时的子树,此时context指向的便是子树的根节点,节点1出栈后,通过context引用它,然后找到它的左右子树,即 context.left, context.right。
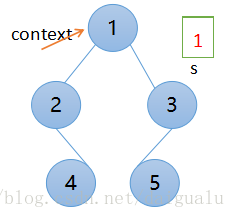
想明白这个context的作用,栈s的出栈时机,进栈时机在前序遍历不难理解,所以循环体内完成一个完整的一步做的事情也就容易理解了,一个遍历步骤做的事情如下:
- context指向的当前子树的根节点为null吗? 如果是,则将context指向栈 s的栈顶,即下一个子树根节点,实际上为右子树。
- 访问栈顶,并出栈栈顶元素,出栈了不用担心,我们通过context引用了这个出栈元素。
- context.right 进栈
- context.left 进栈,至于为什么是先进栈right,这里不解释了。
- 既然访问完了子树的根节点,那么前序遍历下一步是访问左子树了,自然地,context被迭代为context.left 。
前序遍历(栈结构实现)
前序遍历 Preorder Traversal :先访问根结点,然后访问根节点的左子树,最后访问根节点的右子树。
给定如下图所示的二叉树,
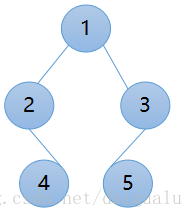
那么用栈这种数据结构,如何前序遍历这颗二叉树呢?
首先,我们把代码放在这里,然后分析这个代码是怎么想出来的。
public static IList<T> PreorderTraversal<T>(
TreeNode<T> root)
{
IList<T> rtn = new List<T>();
if (root == null) return rtn;
var s = new Stack<TreeNode<T>>();
s.Push(root);
TreeNode<T> context = root;
while (s.Count > 0) {
if (context == null)
context = s.Peek();
rtn.Add(s.Peek().val); //访问栈顶元素
s.Pop();
if (context.right != null) //左子树入栈
s.Push(context.right);
if (context.left != null) //右子树入栈
s.Push(context.left);
context = context.left;
}
return rtn;
}while遍历前,各个变量的状态
s 栈有一个节点 1
context 上下文变量引用节点 1
第一次遍历,此时栈中含有元素,进入循环体内,上下文为节点 1,不满足 if 条件,访问 节点 1,节点 1 出栈, 节点 1 的右子树不为 null 先入栈,左子树也为 null后入栈, 上下文变量赋值为 左子树节点 2,如下图所示:
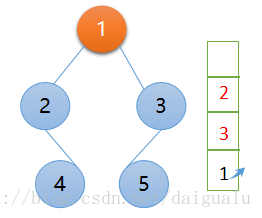
context = node2
第二次遍历,访问节点 2,然后节点 2 出栈,节点 2 的右子树不为 null,入栈,此时的 context 被赋值为节点 2的左子树,即为 null
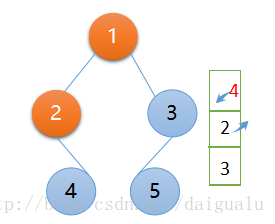
context = null
第三次遍历,会特殊一些了,因为此时的context为 null,注意源码实现中的 if 条件,
if (context == null)
context = s.Peek();
满足了条件,context 被赋值为栈顶节点 4,然后执行逻辑与以上遍历相同,访问栈顶节点 4,显然这个节点 4的左右子树皆为 null,context再次被赋值,且等于 null。
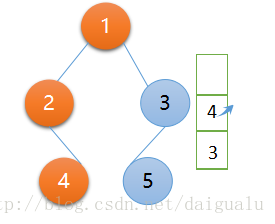
context = null
第四次遍历,依然满足 if 条件,context 被赋值为栈顶节点 3,执行逻辑与上相似,访问栈顶节点 3,节点 3 出栈,节点 3 的右子树为null,左子树不为null,入栈,context再次被赋值为节点 3 的左子树 5
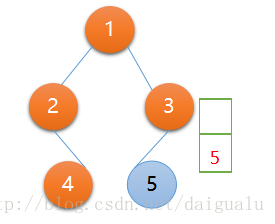
context = node5
第五次遍历,不满足 if 条件了,直接访问节点 5, 然后节点 5 出栈,显然节点 5 左右子树为null,context赋值为node5.left,即为null,并且栈的元素已经空了。
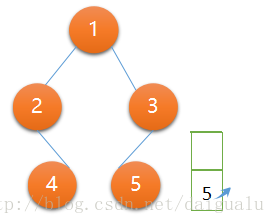
context = null
此时,while (s.Count > 0) 不满足了,退出遍历。
前序遍历总结
前序遍历在遍历前先入栈根节点,context引用根节点,进入遍历后,有一个 if 条件判断context为null吗,如果是说明上文的左子树为null,context需要引用此时栈顶元素,访问栈顶元素,栈顶元素出栈,接下来,首先入栈右子树,然后入栈左子树,context为 context.left 进行迭代。因此,以上二叉树访问节点的次序为
1->2->4->3->5
中序遍历
中序遍历,遍历根节点位于遍历左子树和右子树之间,即左子树,根节点,右子树。
中序遍历的源码如下:
public IList<T> InorderTraversal<T>(TreeNode<T> root)
{
IList<T> rtn = new List<T>();
var s = new Stack<TreeNode<T>>();
if (root == null) return rtn;
s.Push(root);
while (s.Count > 0)
{
var context = s.Peek();
while (context != null)
{
s.Push(context.left);
context = context.left;
}
s.Pop();
if (s.Count == 0)
return rtn;
rtn.Add(s.Peek().val);
TreeNode<T> curNode = s.Pop();
s.Push(curNode.right);
}
return rtn;
}不妨您先思考一下,这段代码是怎么构思出来的,分析中序遍历,后续遍历图解,敬请关注明天的推送,谢谢。
本文由算法实验室倾情奉献,除合作社区及合作媒体外,禁止转载。
算法实验室分享最新的算法和应用实现相关技术内容。














 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









