









2016年过去了, 简单回顾, 这一年中oracle应用级别优化, 有了基本套路,简单概述下,1 根据业务需求,数据生命周期抽象出数据模型,数据按周期 全自动化管理。
2 各种分离, 读写分离, 数据量分离, 负载分离。并发分离或者说压力分离。 3 数据暴增场景下, 更加精密的分区规划,替代索引。防止产生过渡的数据碎片,挤压磁盘空间
和性能空间。 4 整合数据加载,清洗,归并流程。 特殊复杂的特殊处理, 保证性能。 5 存储规划,现有数据模型对性能压力大增,如何规划, 好像没有说清楚,举例把,比
如 现在机构表,上面有个字段表示上级机构编号, 经常有查询需要查其子孙机构 基本信息, 现在我们是用的 递归查询, 众说周知 递归查询 效率相当慢, 设计出精妙的表结
构可以规避递归查询, 而且还可以支持老的查询, 因为后期改造,代码分离在各个模块中, 有的模块甚至已经封板。 5 诡异问题诊断。 也就是今天要说的。
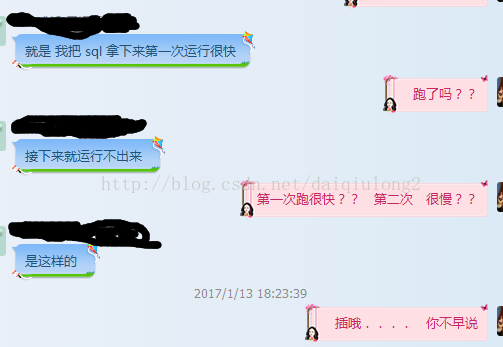
下班时候接到问题, 说SQL慢, 而且执行计划,SQL什么的都已经发出来,看了下一套NL, NL 嵌套NL, 性能可能的地方就是这NL, 但不是我 预期的, 简单询问下,
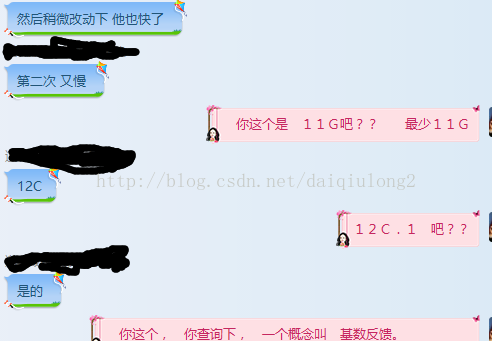
一大跳, 也就是说, 第一次查询 很快, 第二次或者 以后查询 很慢很慢, 然后 稍微 改变下变量的值, 第一次查询 又是很快, 第二次查询 又查不出来。
用oracle 的都知道的, 第一次查询慢, 第二次查询肯定比第二次查询快对吧, 后来问了下 oracle版本, 12C , 于是 心里差不多有底了 基数反馈, 叫他 查询下这个概念,
我懒的给她改了, 叫她添加 hints , 完事之后, 果然解决了, 前后 性能都是 很快了。
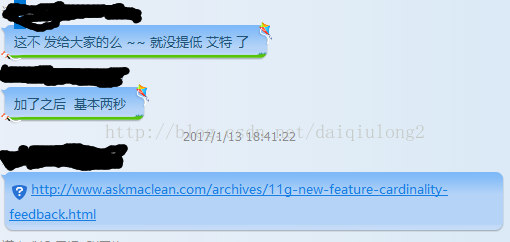
以前就知道 是基数反馈, 这种表现, 今天遇到了, 简单纪念之......















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









