







K-Means++聚类算法
一、k-Means++
K-Means++ 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
K-Means++算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-Means++算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。
1、算法思路:
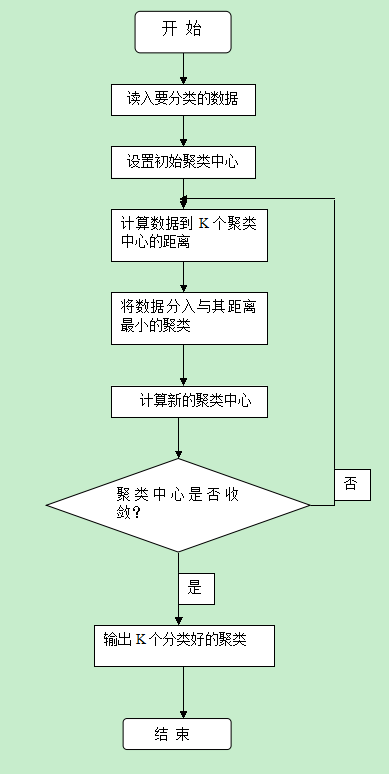
首先从输入的数据点集合中随机选择一个点作为第一个聚类中心,对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离Distance(x),选择一个新的数据点作为新的聚类中心,选择的原则是:Distance(x)较大的点,被选取作为聚类中心的概率较大,重复上述直到k个聚类中心被选出来;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然 后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
2、算法步骤:
step.1—先从n个对象中随机挑个随机点当“种子点”,对于每个点,我们都计算其和最近的一个“种子点”的距离Distance(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。重复直到k个聚类中心被选出来。
step.2—计算所有数据样本与每个质心的欧氏距离,将数据样本加入与其欧氏距离最短的那个质心的簇中(记录其数据样本的编号)
step.3—计算现在每个簇的质心,进行更新,判断新质心是否与原质心相等,若相等,则迭代结束,若不相等,回到step2继续迭代。
3、算法流程图
二、数据集介绍
2.1 Iris数据集介绍
iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。
三类分别为:setosa, versicolor, virginica。
数据包含4个独立的属性,这些属性变量测量植物的花朵,比如萼片和花瓣的长度等。
2.2 wine数据集介绍
这份数据集包含来自3种不同起源的葡萄酒的共178条记录。13个属性是葡萄酒的13种化学成分。通过化学分析可以来推断葡萄酒的起源。值得一提的是所有属性变量都是连续变量。数据集特征:多变量;记录数:178;领域:物理;属性特征:整数,实数;属性数目:13。
2.3 abalone数据集介绍
采用UCI数据集中的abalone数据集进行测试。该数据集包括涉及生活领域的8个类别的4177个数据对象,其中含有1个分类型属性,1个整数型属性和6个实数型属性。分类属性数据对象中含有1528个记录为F(父)值,1307个记录为M(母)值,还有1342个记录为I(未成年人)值。
三、java实现
如果需要具体代码请加QQ 1633581545 













 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









