







注:以下内容转载自 现代魔法学院 网站的 URLconf处理其四:URL调度器详解 一文,仅供学习使用。
前面 3 个小节分别介绍了 URL 模式(RegexURLPattern),URL 分解器(RegexURLResolver),匹配结果(ResolverMatch),但是三者没有详细地串联起来,也不好理解。
一般来说,一个请求先会从 URL 匹配器 RegexURLPattern 进入,RegexURLPattern 真正发挥匹配作用的是 RegexURLResolver 对象,并调用 RegexURLResolver.resolve() 启动了解析,一切从这里开始。从 urlresolver.py 中抽取主干部分,可以得到下面的 UML 图:
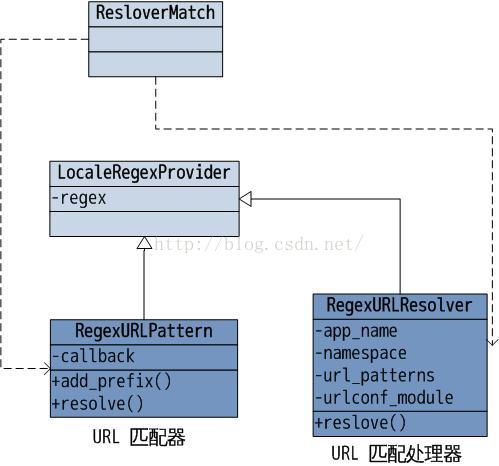
LocaleRegexProvider 类只为地区化而存在,它持有 regex 属性,但在RegexURLResolver 和 RegexURLPattern 中发挥不同的作用:
- RegexURLResolver:过滤 url 的前缀,譬如如果 regex 属性值为 people,那么能将 nowamagic/academy/ 过滤为 academy/。
- RegexURLPattern:匹配整个 url。
ResolverMatch, RegexURLPattern, RegexURLResolver 三个类暂且将他们理解为:
- ResolverMatch 当匹配成功时会实例化返回
- RegexURLPattern,RegexURLResolver 匹配器,但有不同。
摘取 RegexURLPattern 的主干函数作为讲解:
# 执行正则匹配
def resolve(self, path):
match = self.regex.search(path) # 搜索
if match:
# If there are any named groups, use those as kwargs, ignoring
# non-named groups. Otherwise, pass all non-named arguments as
# positional arguments.
# match.groupdict() 返回正则表达式中匹配的变量以及其值, 需要了解 python 中正则表达式的使用
kwargs = match.groupdict()
if kwargs:
args = ()
else:
args = match.groups()
# In both cases, pass any extra_kwargs as **kwargs.
kwargs.update(self.default_args)
# 成功, 返回匹配结果类; 否则返回 None
return ResolverMatch(self.callback, args, kwargs, self.name)
# 对 callback 进行修饰, 如果 self._callback 不是一个可调用的对象, 则可能还是一个字符串, 需要解析得到可调用的对象
@property
def callback(self):
if self._callback is not None:
return self._callback
self._callback = get_callable(self._callback_str)
return self._callback
再摘取 RegexURLResolver 的主干函数作为讲解:
# 最关键的函数
def resolve(self, path):
tried = []
# regex 在 RegexURLResolver 中表示前缀
match = self.regex.search(path)
if match:
# 去除前缀
new_path = path[match.end():]
for pattern in self.url_patterns: # 穷举所有的 url pattern
# pattern 是 RegexURLPattern 实例
try:
"""在 RegexURLResolver.resolve() 中的一句: sub_match = pattern.resolve(new_path) 最为关键.
从上面 patterns() 函数的作用知道, pattern 可以是 RegexURLPattern 对象或者 RegexURLResolver 对象. 当为 RegexURLResolver 对象的时候, 就是启动子 url 匹配处理器, 于是又回到了上面.
RegexURLPattern 和 RegexURLResolver 都有一个 resolve() 函数, 所以, 下面的一句 resolve() 调用, 可以是调用 RegexURLPattern.resolve() 或者 RegexURLResolver.resolve()"""
# 返回 ResolverMatch 实例
sub_match = pattern.resolve(new_path)
except Resolver404 as e:
# 搜集已经尝试过的匹配器, 在出错的页面中会显示错误信息
sub_tried = e.args[0].get('tried')
if sub_tried is not None:
tried.extend([[pattern] + t for t in sub_tried])
else:
tried.append([pattern])
else:
# 是否成功匹配
if sub_match:
# match.groupdict()
# Return a dictionary containing all the named subgroups of the match,
# keyed by the subgroup name.
# 如果在 urls.py 的正则表达式中使用了变量, match.groupdict() 返回即为变量和值.
sub_match_dict = dict(match.groupdict(), **self.default_kwargs)
sub_match_dict.update(sub_match.kwargs)
# 返回 ResolverMatch 对象, 如你所知, 得到此对象将可以执行真正的逻辑操作, 即 views.py 内定义的函数.
return ResolverMatch(sub_match.func,
sub_match.args, sub_match_dict,
sub_match.url_name, self.app_name or sub_match.app_name,
[self.namespace] + sub_match.namespaces)
tried.append([pattern])
# 如果没有匹配成功的项目, 将异常
raise Resolver404({'tried': tried, 'path': new_path})
raise Resolver404({'path' : path})
# 修饰 urlconf_module, 返回 self._urlconf_module, 即 urlpatterns 变量所在的文件
@property
def urlconf_module(self):
try:
return self._urlconf_module
except AttributeError:
self._urlconf_module = import_module(self.urlconf_name)
return self._urlconf_module
# 返回指定文件中的 urlpatterns 变量
@property
def url_patterns(self):
patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module)
try:
iter(patterns) # 是否可以迭代
except TypeError:
raise ImproperlyConfigured("The included urlconf %s doesn't have any patterns in it" % self.urlconf_name)
# patterns 实际上是 RegexURLPattern 对象和 RegexURLResolver 对象的集合
return patterns
ResolverMatch 不贴代码了,它包装了匹配成功所需要的信息,如 views.py 中定义的函数。















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









