







通常情况下,建立索引是加快查询速度的有效手段。但索引不是万能的,靠索引并不能实现对所有数据的快速存取。事实上,如果索引策略和数据检索需求严重不符的话,建立索引反而会降低查询性能。因此在实际使用当中,应该充分考虑到索引的开销,包括磁盘空间的开销及处理开销(如资源竞争和加锁)。例如,如果数据频繁的更新或删加,就不宜建立索引。
建立索引:在SQL语言中,建立聚簇索引使用CREATE INDEX语句,格式为:CREATE CLUSTER INDEX index_name ON table_name(column_name1,column_name2,...);
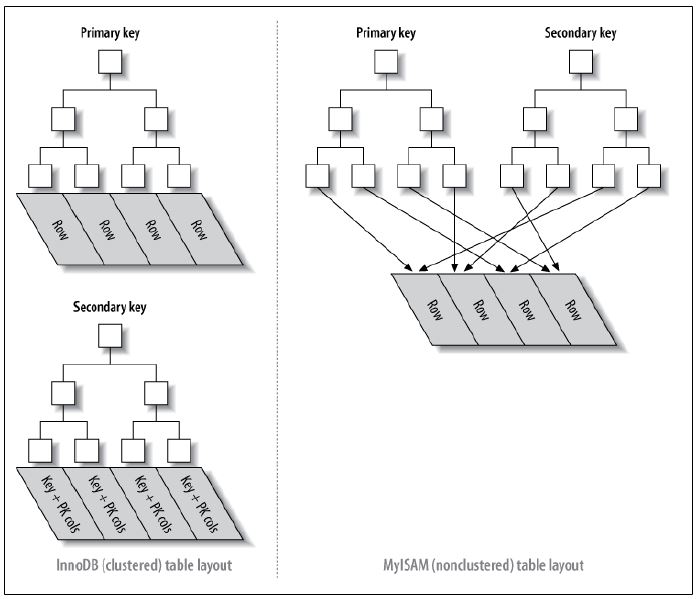
存储特点:
聚集索引:表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。
非聚集索引:表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
他们的区别可以用下图来表示:
更新表数据
1、向表中插入新数据行
如果一张表没有聚集索引,那么它被称为 “堆集 ”( Heap)。这样的表中的数据行没有特定的顺序,所有的新行将被添加到表的末尾位置。 而建立了聚簇索引的数据表则不同:最简单的情况下, 插入操作根据索引找到对应的数据页,然后通过挪动已有的记录为新数据腾出空间,最后插入数据。如果数据页已满,则需要拆分数据页,调整索引指针(且如果表还有非聚集索引,还需要更新这些索引指向新的数据页 )。而类似于自增列为聚集索引的,数据库系统可能并不拆分数据页,而只是简单的新添数据页。
如果一张表没有聚集索引,那么它被称为 “堆集 ”( Heap)。这样的表中的数据行没有特定的顺序,所有的新行将被添加到表的末尾位置。 而建立了聚簇索引的数据表则不同:最简单的情况下, 插入操作根据索引找到对应的数据页,然后通过挪动已有的记录为新数据腾出空间,最后插入数据。如果数据页已满,则需要拆分数据页,调整索引指针(且如果表还有非聚集索引,还需要更新这些索引指向新的数据页 )。而类似于自增列为聚集索引的,数据库系统可能并不拆分数据页,而只是简单的新添数据页。
2、从表中删除数据行
对删除数据行来说:删除行将导致其下方的数据行向上移动以填充删除记录造成的空白。如果删除的行是该数据页中的最后一行,那么该数据页将被回收,相应的索引页中的记录将被删除。对于数据的删除操作,可能导致索引页中仅有一条记录,这时,该记录可能会被移至邻近的索引页中,原索引页将被回收,即所谓的“索引合并”。














 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









