










声明:非常抱歉给大家看到这种排版的文章,但是我实在没有办法了,调了很多次,第二天又乱了,希望CSDN的相关人员能够正视这个问题。否则我将换平台。
前言:
在Windows平台中的SQL Server,对数据库实例的配置有一个很重要的性能提升手段,就是使用即时文件初始化,未出现这个功能之前,数据库数据文件的增长是靠填0来实现的,也就是如果要扩充100G空间,那么就要填入100G体积的0,这个是非常耗时的操作,作者实际遇到过的例子是大概十来G要花费3、4小时,当然跟磁盘I/O跟当前服务器繁忙情况也有关系。
当出现即时文件初始化(Instant File Initialization)之后,这个行为就大大改变,SQL Server会“告诉”操作系统给我预留100G的空间,我稍后再用,操作系统觉得有条件的话,就把某部分空间划定为“预留”,然后通知SQL Server“扩充完成”,此时SQL Server就可以继续做自己的事情。这个行为通常只需要少数几秒(视扩充大小而定),相比起来,这个功能真的可以理解为“即时”。
但是它也有某些限制:
1. 仅对数据文件有效,对日志文件无效。
2. 存在安全问题(系统管理员可以通过某些工具或者技术查到已划给SQL Server但是未被SQL Server使用的那部分空间上旧数据的内容)。
3. SQL Server引擎服务帐号需要有本机管理员或本机管理员组成员角色,或服务帐号需要被授予在Windows上的“Perform volume maintenance tasks,执行卷任务”权限。
4.某些功能如TDE会阻止即时文件初始化。
5.仅适合建库、添加数据文件、增加现有数据文件大小(重建索引有时候会增加空间,上面作者经历的就是重建索引非长久,后面发现在等待磁盘分配,检查后发现SQL 引擎权限不够无法进行即时文件初始化)、还原数据库
但是本文并不想过于深入到这里,所以点到为止,网上已经有很多详细介绍,在此不重复,本文重点在Linux上的即时文件初始化。
注:从 SQL Server 2012 SP4 和 SQL Server 2016 SP1 到 SQL Server 2017 开始,sys.dm_server_servicesDMV 中的列 instant_file_initialization_enabled 可用来识别是否启用了即时文件初始化。
背景介绍:
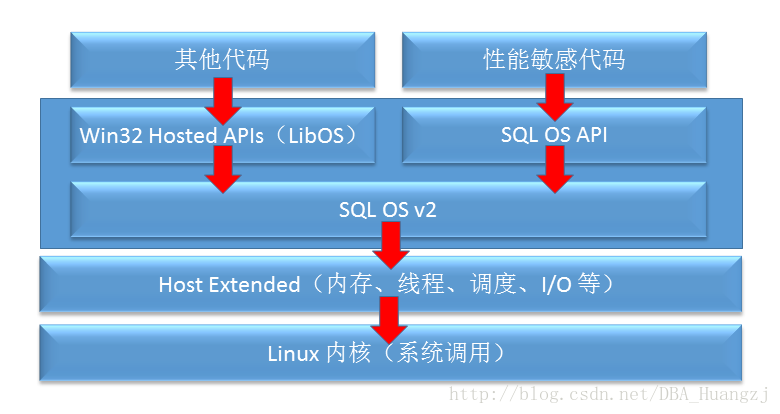
基于这种流程,实际上我们可以想象得到,在SQL Server文件初始化时,应该会通知Linux检查磁盘是否有足够空间,如果有,就告诉Linux创建文件所需的信息,然后Linux根据这些信息调用各种系统函数来实现创建和初始化这两个主要步骤。
这篇文章用到了很多Linux的知识,可能对于在Windows上的SQL Server用户来说会比较痛苦,但是作者希望读者能得益的当然是知道在说什么,如果不知道,也最起码了解方法,用这个套路去研究其他感兴趣的功能。如果有精力和时间,作者会尽量多写一些类似的文章,一方面自己巩固,另外一方面也愿意分享给大家。
使用strace收集系统调用:
经过上面的简介之后,下面来使用Linux工具看看SQL Server在与操作系统交互时发生了什么事,这里使用了叫strace的工具来查看使用了什么系统调用及发生了什么事。从而引伸出SQL Server On Linux如何实现即时文件初始化功能,也可以使用这种方式去发现大部分SQL Server在Windows上的行为在Linux上是怎样的。但是需要注意的是,这种“研究”性质的工作不要在重要环境下进行。
strace:
常用于跟踪进程执行时的系统调用和接收的信号。由于Linux中进程不能直接访问硬件设备,必须由用户态切换到内核态,通过系统调用来访问硬件设备。strace就是用来跟踪进程产生的系统调用及其参数、返回值和执行时间等信息。详细内容可以参考一下Ubuntu的网站:Strace (本人使用Ubuntu Server进行学习实践)。
准备工作:
下面就使用strace来跟踪SQL Server On Linux进程“sqlservr”,首先我们使用ps命令来查找SQL Server进程,可以看到总是有两个进程,这里需要的是子进程,也就是进程ID更高的那个,比如下图的24912:

然后我们对这个进程ID,使用strace并使用参数-t (增加时间戳)、-f (跟踪由fork调用锁产生的子进程)和-p(要跟踪的进程ID),并输出到一个TestDB.txt文件中:

开启之后,我们接下来就是创建一个数据文件和日志文件的数据库,默认情况下数据库文件大小为8MB。这个值可以从model数据库的文件中看到,新库默认都从这里作为模版来创建。
这里借用必要的跟踪标记(How and Why to Enable Instant File Initialization),再次提醒,即时文件初始化仅对数据文件有效。日志文件依旧使用填充0的方式来增长,主要因为应对故障恢复。
DBCC TRACEON(3004,3605,-1)
GO
CREATE DATABASE TestDB
GO
EXEC sp_readerrorlog
GO
DROP DATABASE TestDB
GO
DBCC TRACEOFF(3004,3605,-1)执行完毕后返回如下结果:

接下来停止strace(使用ctrl+c),此时可以对TestDB.txt文件进行分析。提醒一下,开启和关闭strace的速度要尽可能快,作者一开始开启了然后处理其他事情,结果文件几百M,数据过亿行,实在无法舒适地研究,只能重做。
通过Linux内部机制检查创建MDF过程:
32159 11:46:15 open("/var/opt/mssql/data/TestDB_log.ldf", O_RDWR|O_CREAT|O_EXCL|O_DIRECT, 0660) = 223
下面来分析一下整个过程:
1. SQL Server向Linux内核(kernel)申请了一个进程(32159)用于执行CREATE命令。这个进程ID(PID)在后续会配合另外一个ID(文件ID)作为标识。
2. 调用 OPEN函数。OPEN函数里面的参数:
- O_RDWR:以read/wirte形式打开文件。
- O_CREAT:创建文件
- O_EXCL:如果文件已存在,则阻止覆盖文件。
- O_DIRECT:对文件启用同步I/O并禁用文件系统缓存。
- 0660:是文件模式
- 223:函数的返回值,这个是文件描述符,简单来说就是文件ID,这个ID用于传输到后续的操作中作为对象ID。这个ID是实际环境产生,读者实操时很可能不一样。

4. 紧接着的下一行是:32159 11:46:14 ftruncate(223, 8388608) = 0,意味着让 ftruncate根据上面的设置,对ID为223的文件设置8388608的大小。
5. 再接着往下看,会发现有一行:32159 11:46:14 io_submit(140693586616320, 1, [{data=0x1839df4d8, pwrite, fildes=223, str="\1\v\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0c\0\0\0\2\0\374\37"..., nbytes=8192, offset=8192}]) = 1。这里的 io_submit用于发起异步I/O( Linux Asynchronous I/O)到Linux磁盘。函数的参数是:aio_context_t,即请求中的块数量 ,然后是AIO控制块的数组,用[]包住,这里比较重要的是pwrite和fildes,pwrite是写操作,而fildes是操作的文件ID。str是实际数据。然后是bytes的数量及偏移量(offset,即IO的起点)。从str中看到,并不是全为0,意味着mdf没有使用0来填充。

6. 在做完这些之后,下面会有一系列的 fsync函数调用:
32159 11:46:14 fsync(223 <unfinished ...>
32159 11:46:14 <... fsync resumed> ) = 0这里要注意线程ID是否为上面查到的32159。这个函数把缓存中的文件ID为223的内容刷到磁盘上进行永久存储,如果fsync resumed返回0则为成功,1为失败。
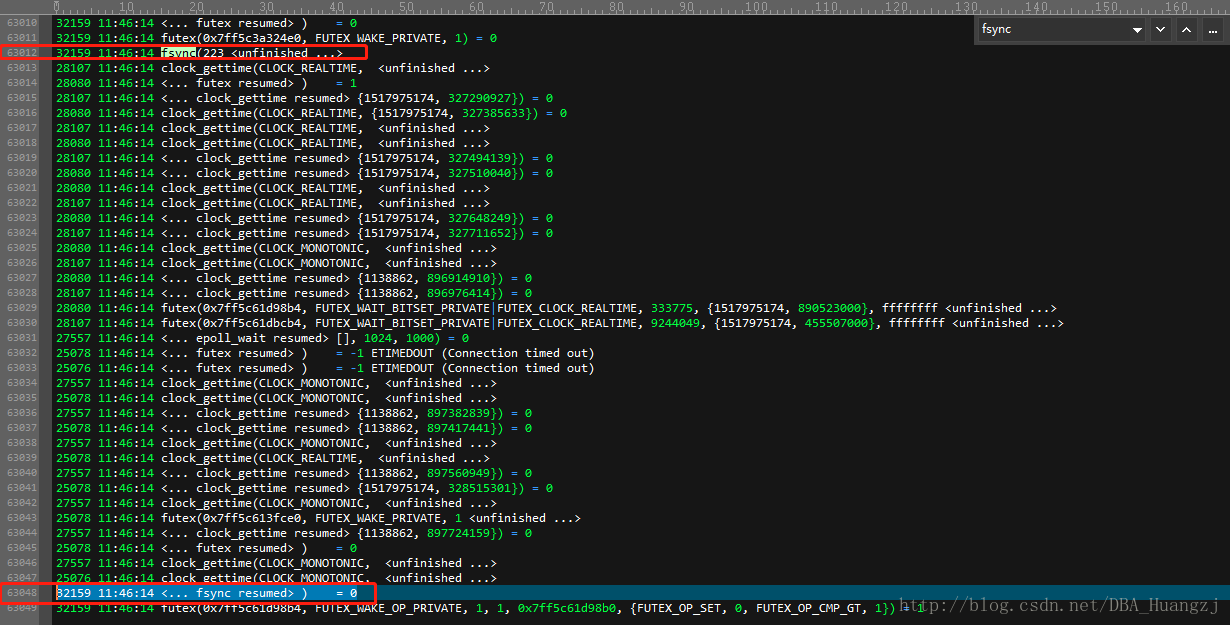
32159 11:46:14 close(223) = 0
至此,MDF文件的创建过程算是结束了。接下来是该看看LDF的创建过程。
通过Linux内部机制检查创建LDF过程:
32159 11:46:15 open("/var/opt/mssql/data/TestDB_log.ldf", O_RDWR|O_CREAT|O_EXCL|O_DIRECT, 0660) = 223

ftruncate:
32159 11:46:15 ftruncate(223, 8388608 <unfinished ...>
fsync:
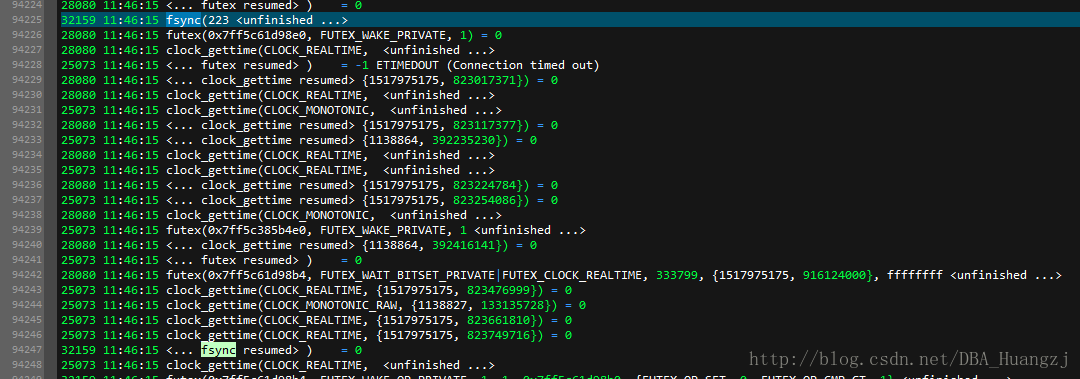
上面步骤跟MDF都是一样的,但是接下来就会出现不一样的地方:
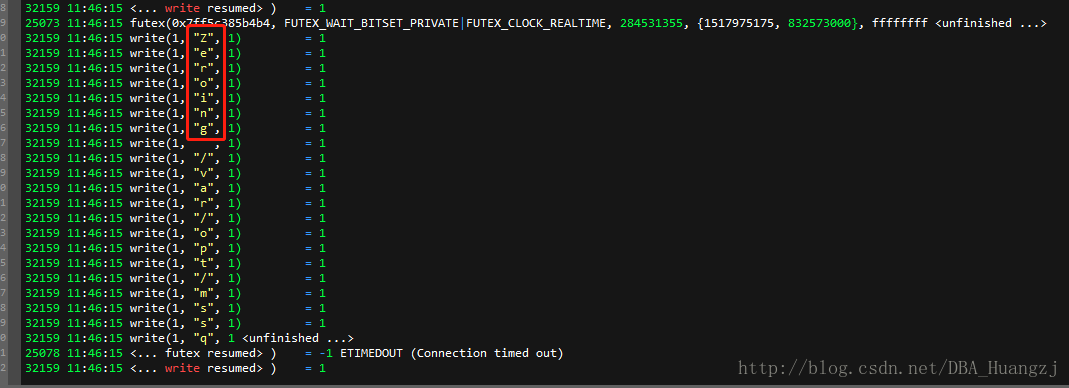
竖着来读就是“zeroing”,会发现有一系列的write调用。这个调用并不是写入到文件,而是一个标准输出,其中第一个参数是1,代表文件描述符是标准输出,第二个参数是需要写到标准输出的数据,这里是单字符,第三个参数是被写入数据的大小,最后就是返回值,也就是这里的1。这个标准输出是在哪?实际上就是SQL Server的Errorlog。
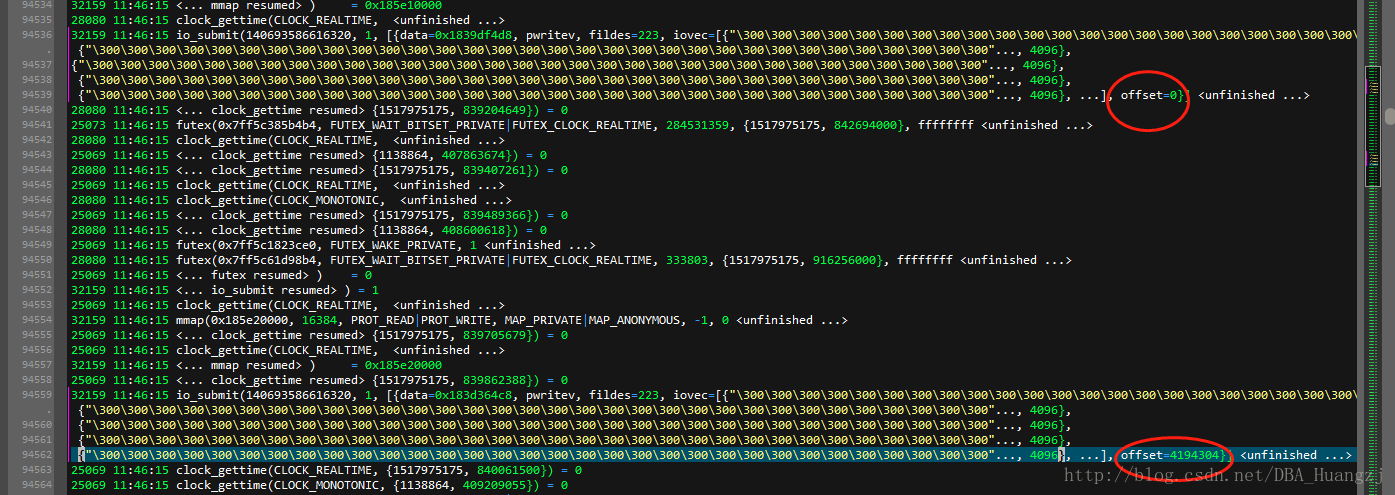
留意上面的offset,每个io_submit写入4MB数据,最后一个offset为4194304bytes=4MB,这里两次io_submit,总共为8MB。
当io_submit完成后,可以看到一系列的write把 zeroing写入到标准输出。然后同样使用fsync刷缓存到磁盘。最后关闭文件。
这个过程就是在Linux上进行的即时文件初始化功能。
总结:
首先,可以看出在Linux中的SQL Server也能实现即时文件初始化功能,这个是通过切换到系统态然后通过系统调用进行资源分配。
在这个过程中,调用的步骤为:
- 创建专用进程进行操作。
- 通过open函数进行文件初始化。
- 通过fallocate函数搭配ftruncate函数对文件进行实际配置。
- 使用io_submit函数发起异步I/O把str的值写入缓存。
- 调用fsync函数把缓存中的值写入磁盘。
- 调用close函数关闭文件并释放锁。














 2622
2622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









