









开源IMDG通常都提供了SPI或其他接口,供用户自行扩展。以Hazelcast为例,我们可以用一些好玩的小工具增强其查询、Map和后端持久化的功能。这些小工具虽然看起来很小,但功能也非常强大。
SQL查询
JoSQL非常简单易用,只需几步就可以在普通Java对象上实现SQL查询功能,而且对标准SQL支持的还很全面呢。同时也提供了接口,我们可以自定义想要的SQL函数。
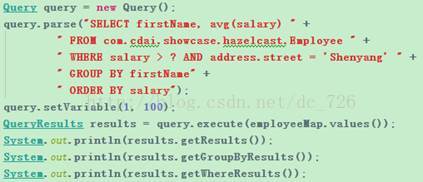
它与Hazelcast的集成方法非常简单,就是新建一个Predicate子类。查询时使用我们新建的这个类,Hazelcast执行时会将我们新定义的apply发送到各个结点上执行,将符合条件的数据返回并汇总,最后返回给我们。利用JoSQL对Hazelcast查询的where过滤条件增强比较容易,但是想利用JoSQL的groupby、join和各种汇总函数对Hazelcast进行增强的话改动比较大,因为Hazelcast的设计就是进行简单的过滤查询,返回值都是对象。要扩展的话可能要利用Hazelcast的MapReduce和Aggregator接口。

堆外存储
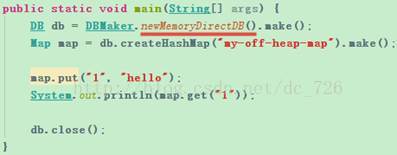
JDK中提供了直接申请堆外内存的方法,就是ByteBuffer.allocateDirect(),其底层调用的是Sun私有的Unsafe.allocateMemory()。因为像Hazelcast这些开源IMDG都把堆外存储缓存数据作为商业版的主打功能之一,所以我们需要自行扩展。但是自己管理堆外内存很麻烦,涉及到空闲内存分配、回收、内存碎片等等管理问题,所以我们还是希望直接使用第三方的产品。在这一领域,目前已经有一些开源产品了:
Ø MapDB:嵌入式数据库,提供文件和堆外存储,以及ACID支持。
Ø DirectMemory:Apache旗下的开源项目,目前还是0.3版本。
Ø 其他:HugeCollections、Fast-serialization等。
以MapDB为例,看一下它的使用方法。具体与Hazelcast的集成方法稍稍麻烦一些,需要实现三个Hazelcast的类,可以参考GitHub上的项目:Hugecast和mapdb-hz-offheap。
后端持久化
使用IMDG时,我们通常还要为每个对象的缓存提供数据加载和持久化类,从而实现缓存的初始化加载和read/write-through功能。可以简单地使用JDBC+DozerMap实现数据的加载保存和实体对象装配,或者利用Hibernate简化这个过程。每种IMDG都提供了对应的扩展接口,例如Hazelcast的扩展点是MapLoader或MapStore,具体实现方式很简单就不列举了。














 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









