







TensorFlow教程地址:https://www.tensorflow.org/tutorials/mnist/pros/
讲的是经典的机器学习问题MNIST。
使用卷积神经网络进行训练。
载入MNIST数据
MNIST数据可以从这里下载
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)创建多层卷积网络
权重初始化
这里定义两个方法:
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)tf.truncated_normal根据截断正态分布产生随机数
tf.constant产生常数
卷积(Convolution)和池化(Pooling)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')先说tf.nn.conv2d,它的参数strides代表切边移动的步长,4个方向,而padding是切片上是否可以越过边缘,有两种方式:”SAME”和”VALID”,”SAME”为越过,“VALID”为不越过,它的意义是决定切片中心是否经过图的边缘。
卷积过程例子如下:
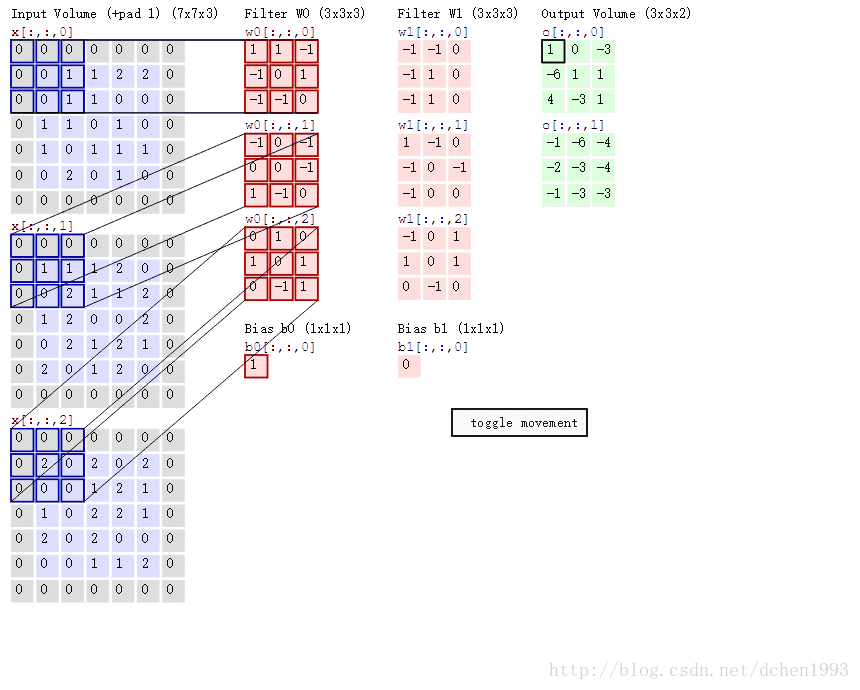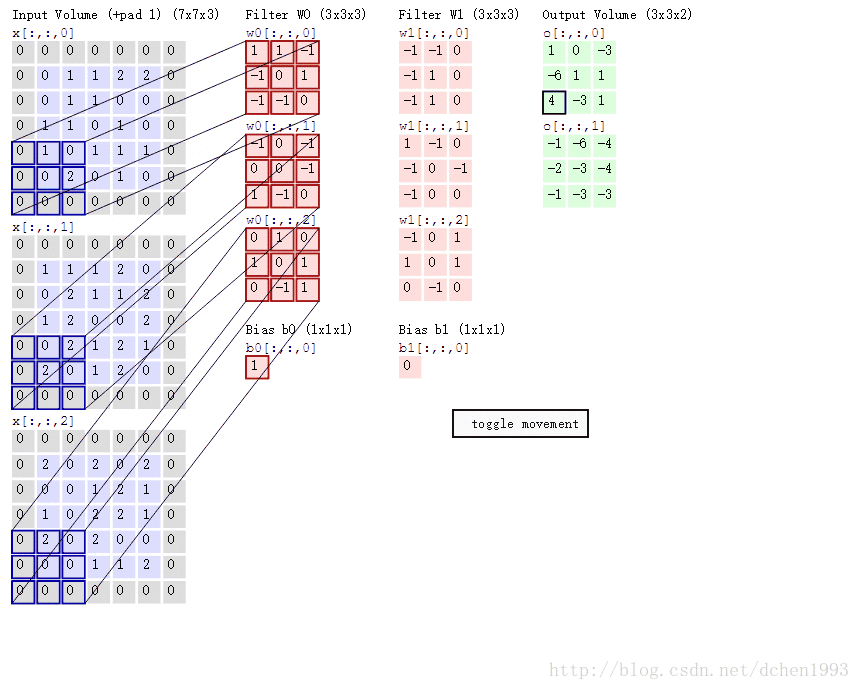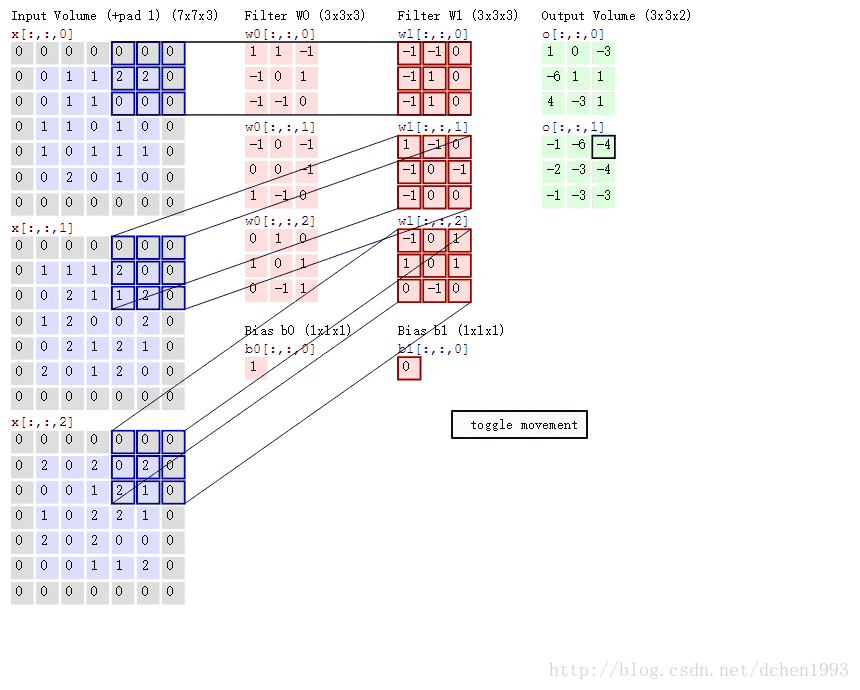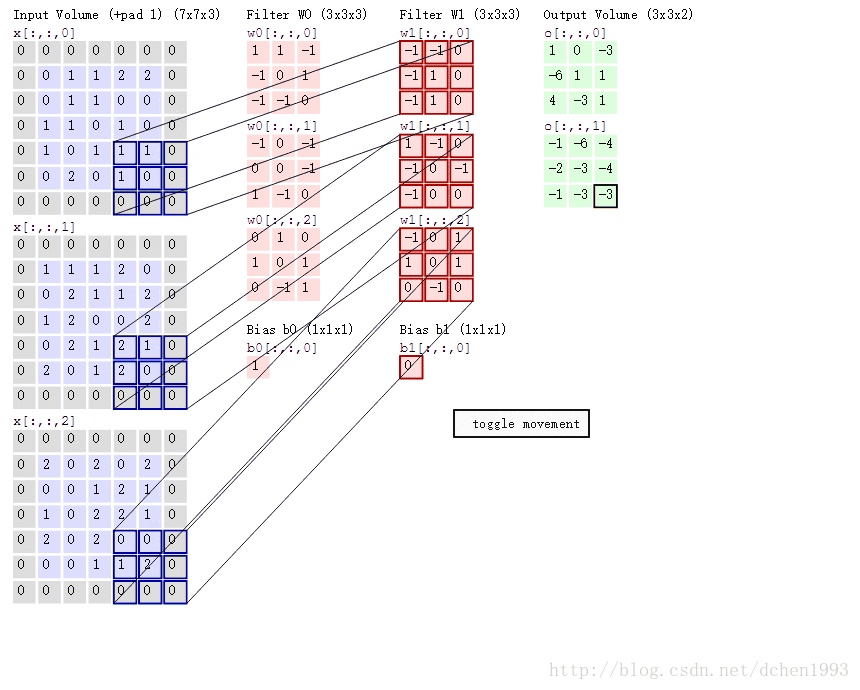
再说tf.nn.max_pool,它是最大化池策略。
参数ksize是要执行取最值的切片在各个维度上的尺寸,四维数组意义为[batch, height, width, channels]。
参数strides是取切片的步长,四维数组意义为四个方向的步长,这里height和width方向都为2,例如原本8x8的矩阵,用2x2切片去pool,会获得5x5的矩阵输出(SAME模式),有效的减少特征维度。
参数Padding同conv2d。
第一个卷积层
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])第一层将以大小为5x5的切片来生成32个特征, [5,5,1,32] 前两位为patch size,再为in_channel,最后为out_channel。in_channel的意义可理解为一个图像RGB的三层,out_channel即生成的神经元数量,如图中的output volume。
x_image = tf.reshape(x, [-1,28,28,1])-1代表任何维度,这里是样本数量,MNIST的图像大小为28*28,由于是黑白的,只有一个in_channel。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)这里使用relu为激活函数,conv2d过程如动图所示,生成32个output volumn,每个大小为28x28,因为
(2+28+2+1−5)×(2+28+2+1−5)=28×28
。
max_pool后生成32个大小为14x14的矩阵,因为
28/2
。
第二个卷积层
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)过程逻辑同第一层,这里只说明输入输出的形式。
输入的是32个14x14的矩阵,权重体现了这层要输出的矩阵个数为64。
卷积输出64个14x14的矩阵,因为
(14+2+2+1−5)/1
池化输出64个7x7的矩阵,因为
14/2
全连接层
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)全连接层就是普通的神经网络,输入参数维度为7x7x64,第一个隐层神经元数为1024。
Dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)为了减少过拟合,使用dropout策略来训练, keep_prob 为各神经元在dropout过程中保留的概率。dropout只在训练过程中开启,在测试过程中会关闭。
输出层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2使用softmax作为输出层。这里暂时还没使用softmax函数,因为下面要使用tf.nn.softmax_cross_entropy_with_logits函数进行最后的计算,它在数值计算上比tf.nn.softmax稳定。
训练与评估
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_conv, y_))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))这里有三个不同之处:
1. 使用ADAM框架来替代steepest随机梯度下降框架。
2. 增加每次batch使用dropout的概率
keep_prob
。
3. 每100次迭代都进行记录。
Reference
https://www.tensorflow.org/tutorials/mnist/pros/#train_and_evaluate_the_model
http://www.cnblogs.com/hellocwh/p/5564568.html
http://blog.csdn.net/han_xiaoyang/article/details/50542880














 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









